确保跨子组的均衡性能的人工智能模型训练的制作方法
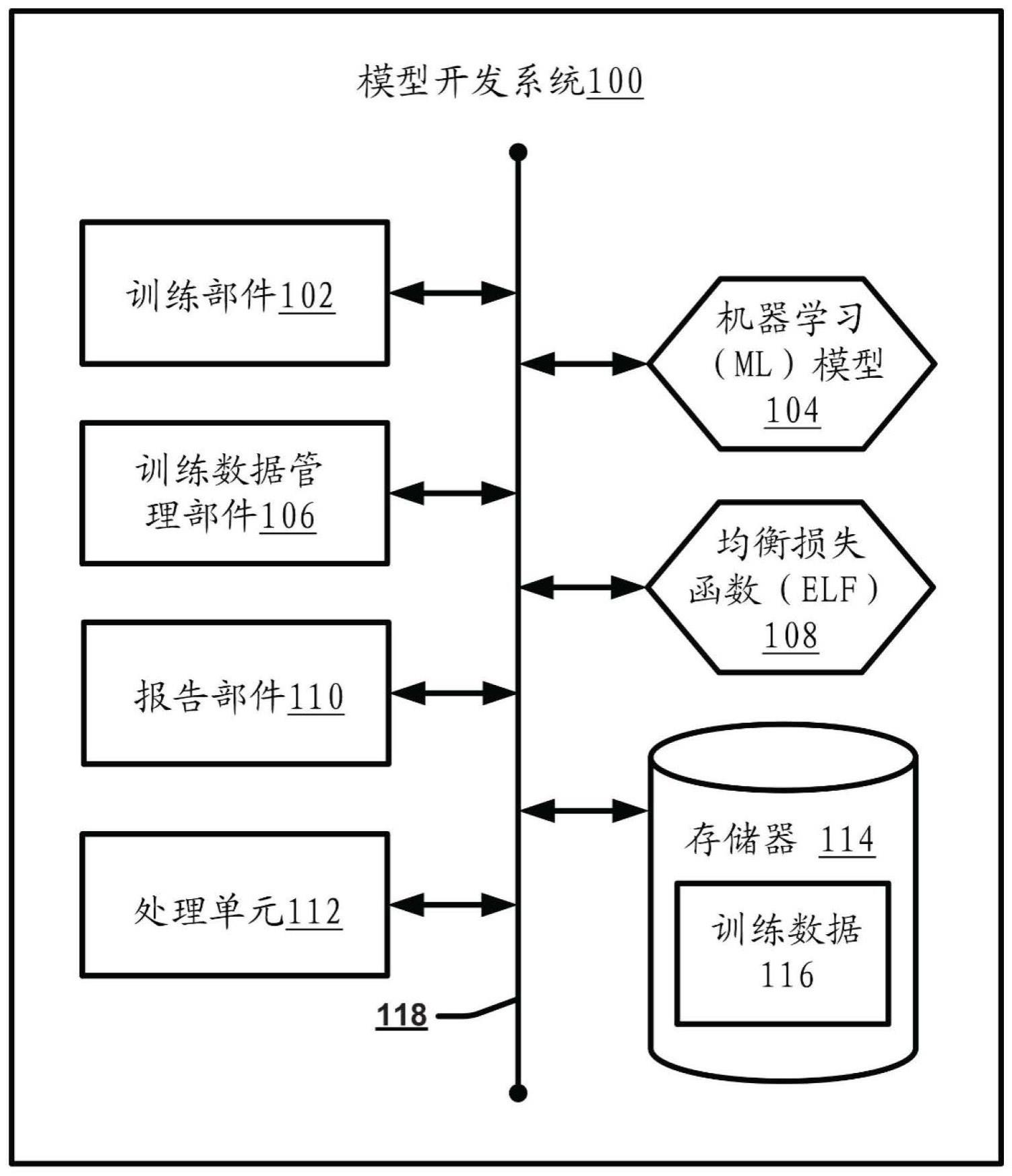
本申请涉及人工智能(ai)模型开发,并且更具体地涉及确保跨不同子组的均衡模型性能的训练技术。
背景技术:
1、人工智能(ai)和机器学习(ml)是一个快速发展的技术领域,影响着各行各业。机器学习技术(诸如深度神经网络)的进步最近在各种ai领域中表现出令人印象深刻的性能,有时甚至超过了人类,这些ai领域包括计算机视觉、语音、自然语言处理(nlp)、生物信息学、药物设计、医学图像分析等。由于机器学习算法继续演变以实现日益更复杂且精确的自动化推断能力,因此保持ai对社会的影响有益的目标已引起验证、有效性、安全性和控制领域的关注。例如,虽然ai个人助手在解释日常命令中的nlp技术误差可能是令人烦恼的,并且在一些情况下令人发笑,但是基于ai的输出的准确度在此类输出控制汽车、飞机、自动交易系统、电网、安全系统等时变得更重要。
2、在医学背景中使用的机器学习模型/算法的性能准确度是至关重要的,特别是在机器学习模型/算法的输出控制生命维持医疗装置的操作的情况下。医疗软件是指在医学背景内使用的任何软件或系统,例如用于诊断或治疗目的的独立软件、嵌入医疗装置中的软件、驱动医疗装置或确定其如何使用的软件、用作医疗装置的附件的软件、用于医疗装置的设计、生产和测试的软件以及提供医疗装置的质量控制管理的软件。
3、根据与软件相关联的类型、预期用途和风险水平,医疗软件的监管环境可能具有不同的审查要求和水平。例如,在作为“经许可的医用产品”在临床实践中授权使用之前,一些监管机构需要软件被分类为医疗装置,通常称为软件即医疗装置(samd),以符合用于有形医疗装置的相同监管路径。医学ai模型的监管批准也对其有关数据子组的无偏差性能是有条件的。通常使用人口统计或医学状况元信息构建子组。目前,子组分析不是模型训练过程的一部分,并且模型的总准确度不一定延伸到所识别的子组中的每个子组。一些解决方案通过增强或增加采样而均衡来自每个子组的训练样本的数量,以此解决该问题。然而,这些方法不确保在领域中的均衡模型性能,因此可能不会受到监管批准的欢迎。
技术实现思路
1、以下呈现了
技术实现要素:
以提供对本发明的一个或多个实施方案的基本理解。本发明内容不旨在标识关键或重要元素,也不旨在描绘不同实施方案的任何范围或权利要求的任何范围。其唯一目的是以简化形式呈现概念,作为稍后呈现的更详细描述的序言。在一个或多个实施方案中,本文描述了促进开发跨不同子组均衡执行的ai模型的系统、计算机实现的方法、装置和/或计算机程序产品。
2、根据一个实施方案,提供了一种系统,该系统包括存储器和处理器,该存储器存储计算机可执行部件,该处理器执行存储在该存储器中的该计算机可执行部件。计算机可执行部件包括训练部件,该训练部件使用均衡损失函数在训练数据上训练ml模型,以执行推断任务,从而产生训练版本的ml模型,该均衡损失函数驱动ml模型跨训练数据中表示的不同子组的均衡性能,该训练版本提供跨不同子组的限定的均衡性能水平。不同子组在训练数据中被标记,并且均衡损失函数被配置为使用标记来识别不同子组。就这一点而言,可以认为均衡损失函数是“子组感知”,并且在模型训练和验证期间对跨子组的性能的变化进行惩罚。
3、在一些实施方案中,结合所公开的系统描述的元件能够以不同形式体现,诸如计算机实现的方法、计算机程序产品或另一种形式。
技术特征:
1.一种系统,所述系统包括:
2.根据权利要求1所述的系统,其中,所述不同子组在所述训练数据中被标记,并且其中,所述均衡损失函数被配置为使用所述标记来识别所述不同子组。
3.根据权利要求1所述的系统,其中,所述均衡损失函数对所述机器学习模型跨所述不同子组的性能的变化进行惩罚。
4.根据权利要求1所述的系统,其中,所述均衡损失函数针对所述不同子组中的至少两个子组采用不同损失权重。
5.根据权利要求4所述的系统,其中,所述不同损失权重基于包括在所述不同子组中的相应子组中的训练数据样本的相对数量。
6.根据权利要求1所述的系统,其中,所述训练部件基于所述均衡损失函数的输出来测量所述机器学习模型跨所述不同子组的性能,并且其中,所述计算机可执行部件还包括:
7.根据权利要求1所述的系统,其中,所述训练部件使用包括训练阶段和验证阶段的监督机器学习过程来训练所述机器学习模型,并且其中,所述训练部件在所述训练阶段和所述验证阶段期间使用所述均衡损失函数。
8.根据权利要求1所述的系统,其中,所述训练部件使用包括训练阶段和验证阶段的监督机器学习过程来训练所述机器学习模型,并且其中,所述计算机可执行部件还包括:
9.一种方法,所述方法包括:
10.根据权利要求9所述的方法,其中,所述不同子组在所述训练数据中被标记,并且其中,所述均衡损失函数被配置为使用所述标记来识别所述不同子组。
11.根据权利要求9所述的方法,其中,所述均衡损失函数对所述机器学习模型跨所述不同子组的性能的变化进行惩罚。
12.根据权利要求9所述的方法,其中,所述均衡损失函数针对所述不同子组中的至少两个子组采用不同损失权重。
13.根据权利要求12所述的方法,其中,所述不同损失权重基于包括在所述不同子组的相应子组中的训练数据样本的相对数量。
14.根据权利要求9所述的方法,所述方法还包括:
15.根据权利要求9所述的方法,其中,所述训练包括训练阶段和验证阶段,并且其中,所述训练包括在所述训练阶段和所述验证阶段期间采用所述均衡损失函数。
16.根据权利要求9所述的方法,其中,所述训练包括训练阶段和验证阶段,并且其中,所述方法还包括:
17.一种包括可执行指令的非暂态机器可读存储介质,所述可执行指令在由处理器执行时促进操作的执行,所述操作包括:
18.根据权利要求17所述的非暂态机器可读存储介质,其中,所述不同子组在所述训练数据中被标记,并且其中,所述均衡损失函数被配置为使用所述标记来识别所述不同子组,并且对所述机器学习模型跨所述不同子组的性能的变化进行惩罚。
19.根据权利要求17所述的非暂态机器可读存储介质,其中,所述均衡损失函数针对所述不同子组中的至少两个子组采用不同损失权重。
20.根据权利要求19所述的非暂态机器可读存储介质,其中,所述不同损失权重基于包括在所述不同子组中的相应子组中的训练数据样本的相对数量。
技术总结
本公开描述了促进以确保跨不同子组的均衡模型性能的方式训练人工智能(AI)模型的技术。根据一个实施方案,提供了一种系统,该系统包括存储器和处理器,该存储器存储计算机可执行部件,该处理器执行存储在该存储器中的该计算机可执行部件。该计算机可执行部件包括训练部件,该训练部件使用均衡损失函数在训练数据上训练机器学习(ML)模型,以执行推断任务,从而产生训练版本的该ML模型,该均衡损失函数驱动该ML模型跨该训练数据中表示的不同子组的均衡性能,该训练版本提供跨该不同子组的限定的均衡性能水平。该均衡损失函数是“子组感知”,并且在模型训练和验证期间对跨该子组的模型性能的变化进行惩罚。
技术研发人员:克里希纳·希瑟拉姆·施莱姆,钱丹·库马尔·马拉帕·阿拉达哈里,V·R·梅拉普迪
受保护的技术使用者:通用电气精准医疗有限责任公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!