基于字频词频的字符分组方法、存储介质及电子设备与流程
1.本发明涉及字库隐形水印技术领域,特别涉及一种基于字频词频的字符分组方法、存储介质及电子设备。
背景技术:
2.在现有的文本水印技术中,为了提高水印算法抵抗打印扫描、屏幕截屏和屏幕拍照等恶意攻击的鲁棒性能,基于字符拓扑结构修改的文本数字水印技术成为主流。即通过将特定字符进行不同形式的变形后对应不同的水印信息位串,字符变形数据会保存在特定的水印字库中,并在电子文本文档打印输出和屏幕显示的过程中,通过字体替换来实现水印信息的嵌入。当我们针对不同的用户使用不同的字符变形数据,对于该用户来说,该特定的水印字库即构成其安全字库。
3.现有的安全字库存在很多缺陷,为了实现在不改变用户任何使用习惯的前提下,用以解决现有技术中水印加载通用性差、系统稳定性差、实现过程复杂以及水印算法鲁棒性能低等问题,北京国隐科技有限公司申请的专利《一种通用的文本水印方法和装置》(公布号:cn114708133a)中公开了如下方案:一种通用的文本水印方法,包括以下步骤:根据特定策略对选定字库中一定数目的字符进行分组;根据特定规则对每个分组中的所有字符进行变形设计,并生成水印字符数据临时文件;生成用户终端水印编码数据,用以标识用户终端的身份认证信息;依据水印编码数据,并结合水印字符数据临时文件和分组的字符,动态生成并实时加载水印字库文件;运行电子格式的文本文件,在文件打印输出和屏幕显示的文档内容数据中利用水印字库文件实时嵌入水印信息。
4.该方案中需要对字符进行分组。在对字符进行分组时,理论上来说,字频较高的字符,应该分别位于不同组;常出现在一起的字符,应该分别位于不同组。满足这两个要求所生成的安全字库,在进行安全码的提取时,所需要的文字内容更少,因此,提取效果、准确率也更佳。该方案中的字符分组方法存在诸多不足:其一,每组中的字符数基本相等,这与上述的要求有所冲突;其二,分组时只考虑了字频,并没有对词频进行充分考虑,理论上,经常出现的词语中对应的字符,应该分在不同组别中,这样可以在更短的内容中出现更多分组,在进行安全码的提取时所需的内容更少;其三,该方案中对分组进行优化时的计算过程太复杂,需消耗大量的时间和算力。
技术实现要素:
5.本发明的目的在于提供一种基于字频词频的字符分组方法,能够更加合理的对字符进行分组。
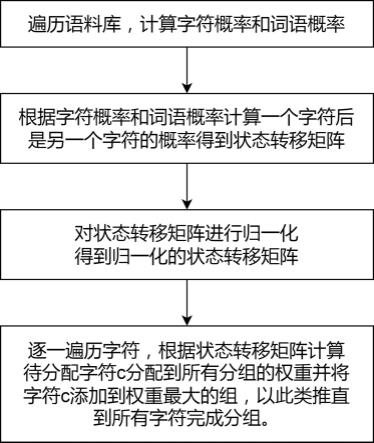
6.为实现以上目的,本发明采用的技术方案为:一种基于字频词频的字符分组方法,包括如下步骤:遍历语料库,根据待分组的n个字符的出现频数计算各字符概率,对语料库中的所有文本进行分词,根据n个字符所组成词语的出现频数计算各词语概率;
根据和计算一个字符后是另一个字符的概率得到状态转移矩阵;对状态转移矩阵进行归一化使得一个字符后是其他字符的概率之和为1得到归一化的状态转移矩阵;逐一遍历字符,计算待分配字符c分配到所有分组的权重并将字符c添加到权重最大的组,该权重和随机二元字符包含组别数的期望值正相关,以此类推直到所有字符完成分组。
7.与现有技术相比,本发明存在以下技术效果:该分组方案主要从词语之间的关联来对字符进行分组,对于常作为一个单词出现的多个字符,尽量将它们分配在不同的组中,状态转移矩阵反映的就是一个字符后是另一个字符的概率,再通过权重计算公式,让经常出现在一起的两个字符分在不同组时的权重增大,这样我们就能通过选择权重最大的组来让一起出现的字符尽量不同组,从而实现了字符的合理分组,此种分组方式对每组中字符个数不做限制,从而更加合理。
附图说明
8.图1是本发明的流程图。
具体实施方式
9.下面结合图1,对本发明做进一步详细叙述。
10.参阅图1,本发明公开了一种基于字频词频的字符分组方法,包括如下步骤:遍历语料库,根据待分组的n个字符的出现频数计算各字符概率,n的最优取值范围为1000~3000,通过对字符的字频进行排序,挑选字频较高的n个字符。分词模型有很多,我们选用较为成熟的分词模型,对语料库中的所有文本进行分词,根据n个字符所组成词语的出现频数计算各词语概率。这里的字频和词频可以利用已有的语料库和模型去计算,也可以直接采用之前已经计算好的结果。语料库的选择也可以根据用户的需求去选择,即可以选择通用的语料库,也可以选择某个企业或组织的内部语料库,针对不同的语料库,所得到的字符分组也是不同的。
11.根据和计算一个字符后是另一个字符的概率得到状态转移矩阵,该矩阵的行、列数均等于字符数n,状态转移矩阵中的元素代表字符后是字符的概率,通过构建状态转移矩阵,从而建立了字符和字符之间的关系。具体地,状态转移矩阵中的元素可以根据如下公式计算得到:式中,是特定词语概率之和,该特定词语中字符和字符相邻且按顺序排列。也即,这里的词语包含的是或或这样的词语,必须要字符
在前、字符在后且两个字符相邻布置,不包括或者这样的词语。由于分词时会分出包含其他词语的长词语,所以需要求和;并且会忽视不构成词语的连续字,所以计算得到的状态转移矩阵中有很多元素的值为0,因此需要进一步进行归一化处理。
12.进一步地,对状态转移矩阵进行归一化使得一个字符后是其他字符的概率之和为1得到归一化的状态转移矩阵;状态转移矩阵可以唯一地表示一个马尔科夫链,求出该矩阵后,语料库到语言模型的建模就完成了。具体地,按如下公式重置状态转移矩阵中为0的元素:式中,为状态转移矩阵中第i行所有元素之和,为状态转移矩阵中第i行所有元素为0的字符对应的字符概率之和。如果某个字符与其他任何字符均不组成词语,那么在状态转移矩阵中该行元素的值均为0,经过归一化以后,该行元素的值就是各字符本身的概率。
13.当我们得到归一化的状态转移矩阵后,为了能够更好的对字符进行分组,我们考虑这样一个场景:字符集中的所有字符都已经完成了分组,此时有需要对一个新的字符c进行分组,只需要计算出该待分配字符c的最佳分组,重复这种思路,对每个字符都计算出最佳分组后,所得到的分组即n个字符的最佳分组。那么,如何确定某个字符的最佳分组呢,我们通过引入权重的方式来确定。
14.首先,我们定义语言模型下随机二元字符包含组别数的期望值为g,用来衡量分组的效果,n个字符分组后对应的g值计算公式如下:其中,g代表二元字符包含的不同组别数,当字符分在同一组时,,当字符分在不同组时,。即字符后是字符的概率,且。
15.通过g的定义,我们可以得知,越大时,其最佳分组是将字符分在不同组,反映在g上就是g的值越大。因此,我们只需要计算待分配字符c分在每个组时的g值,当g值越大,表示该分组效果最佳。
16.因此,本发明的实施例一中,直接以随机二元字符包含组别数的期望值g作为权
重,具体地,所述的计算待分配字符c分配到所有组的权重步骤中,按如下公式计算待分配字符c分配到第k组时的权重:式中,a为已分组字符和待分配字符c构成的集合,即归一化的状态转移矩阵中字符对应行、字符对应列的元素值。该实施例中,每分配一个字符时,计算该字符分在各组时对应的g值。
17.实施例一种的方案,随着已分组字符越来越多,后面的计算量也越来越大。为了提高处理速度,我们换一种思路,通过计算g的增加量来寻找最佳分组。将待分配字符c分到第k组时,g的增加量为:其中,前两项与k无关,即与分组方法无关。根据上面的推导过程,我们可以有两种方式来定义权重。
18.实施例二,所述的计算待分配字符c分配到所有组的权重步骤中,按如下公式计算待分配字符c分配到第k组时的权重:
式中,即归一化的状态转移矩阵中字符c对应行、字符对应列的元素值。
19.实施例三,所述的计算待分配字符c分配到所有组的权重步骤中,按如下公式计算待分配字符c分配到第k组时的权重:式中,即归一化的状态转移矩阵中字符c对应行、字符对应列的元素值。
20.分组k根据需要进行取值,比如可以取30,那么,此时的求和项数是大于的求和项数的,也即实施例二中的计算量虽然相较于实施例一中的方案少了很多,但是依然多于实施例三中的计算量的。因此,我们实际在进行权重的计算时,优选采用作为权重。
21.通过以上的描述我们可知,不论是随机二元字符包含组别数的期望值g本身,还是g的增加量,还是简化得到的,都是与随机二元字符包含组别数的期望值正相关的。除了这里提到的三个权重外,还可以设置其他的权重,只要其与g是正相关的即可。
22.进一步地,所述的逐一遍历字符,计算待分配字符c分配到所有分组的权重的步骤中,按照字频从高到低的顺序逐一遍历。我们每分配一个字符c,其实就是求局部最优解,按照字频从高到低的顺序遍历,可以求得整体最优解,即所有字符分组后的最优解。
23.本发明还公开了一种计算机可读存储介质和一种电子设备。具体地,一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如前所述的基于字频词频的字符分组方法。一种电子设备,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序时,实现如前所述的基于字频词频的字符分组方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1