基于多标签分类模型实现的法律多意图识别方法和装置与流程
本申请涉及意图识别,尤其涉及一种基于多标签分类模型实现的法律多意图识别方法和装置。
背景技术:
1、目前对于法律领域,问答系统的实际使用较少。在实际生活中,法律咨询应用非常广泛,对咨询者问题的解答,处理对当前问题的理解,也需要结合实际的咨询者的情况,分析出咨询者的意图,进行解答。
2、法律咨询场景和一般问答场景相比,其意图划分更加精细,并且问答方式需要融入法律领域的相关能力模型,为了达到这个目的,需要通过把机器学习模型嵌入系统来实现。难点在于,由于法律领域信息很广,意图类别非常精细,同一条文本在不同场景下可能对应不同的意图,或者同时对应多个意图。如何结合对话识别出咨询者当前场景下,准确的,完整的意图,直接对当前法律faq问答系统的准确率产生影响。
技术实现思路
1、本申请旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本申请的第一个目的在于提出一种基于多标签分类模型实现的法律多意图识别方法,解决了现有意图识别方法难以准确完整的识别咨询者的意图的技术问题,通过使用少量数据对模型进行训练,使得模型能够在法律意图识别中更加客观准确的分析咨询者的意图,提升了识别效率、准确率和全面性。
3、本申请的第二个目的在于提出一种基于多标签分类模型实现的法律多意图识别装置。
4、本申请的第三个目的在于提出一种计算机设备。
5、本申请的第四个目的在于提出一种非临时性计算机可读存储介质。
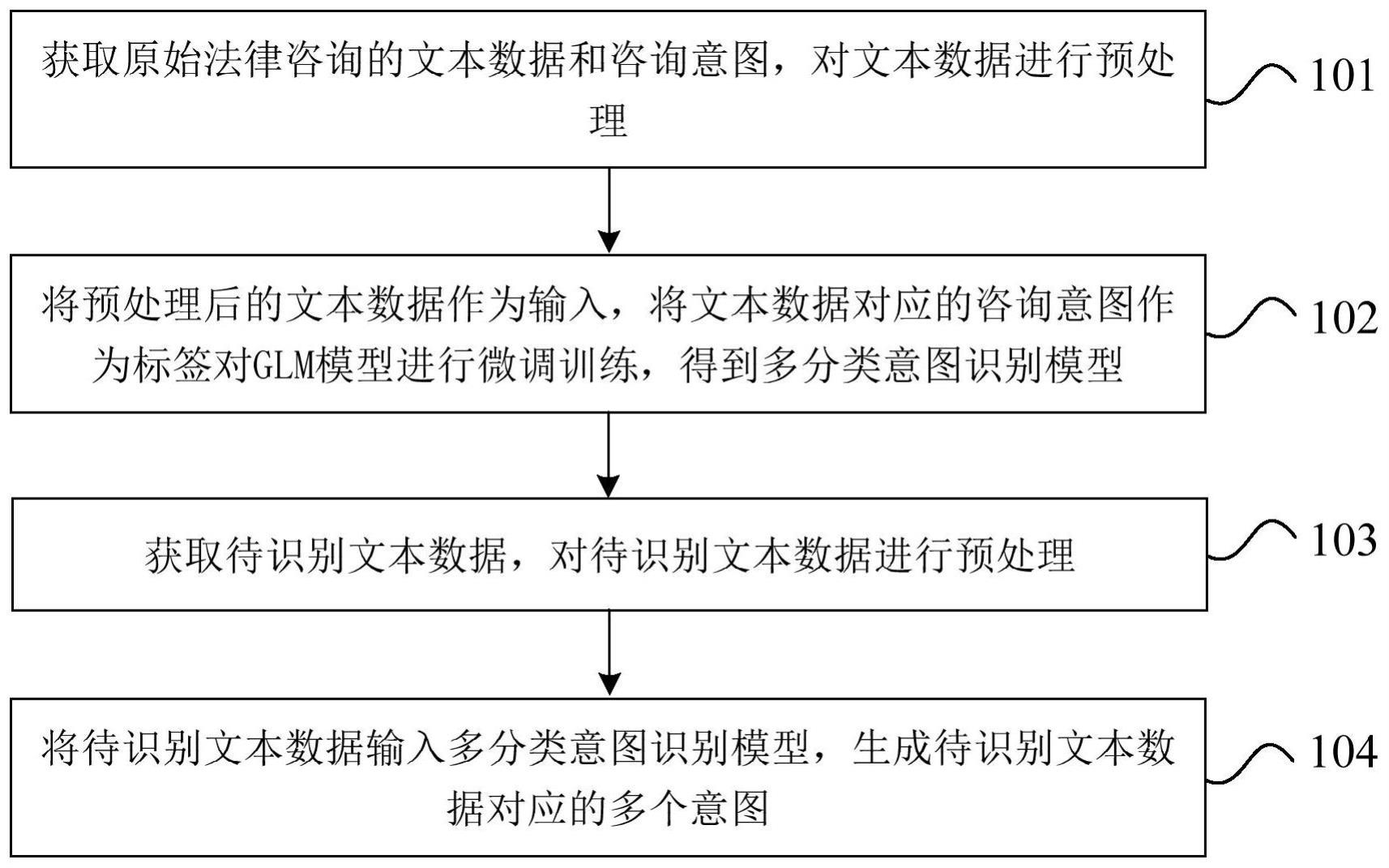
6、为达上述目的,本申请第一方面实施例提出了一种基于多标签分类模型实现的法律多意图识别方法,包括:获取原始法律咨询的文本数据和咨询意图,对文本数据进行预处理;将预处理后的文本数据作为输入,将文本数据对应的咨询意图作为标签对glm模型进行微调训练,得到多分类意图识别模型;获取待识别文本数据,对待识别文本数据进行预处理;将待识别文本数据输入多分类意图识别模型,生成待识别文本数据对应的多个意图。
7、可选地,在本申请的一个实施例中,对文本数据进行预处理,包括:
8、使用文本改写模型将文本数据改写为书面文本数据;
9、通过指代消解模型对书面文本数据进行指代消解,消除歧义文本;
10、去除经过指代消解的书面文本数据的停用词;
11、分别对所述去除停用词的书面文本数据提取关键词和文本摘要,得到关键词和文本摘要。
12、可选地,在本申请的一个实施例中,在使用文本改写模型将文本数据改写为书面文本数据之前,包括:
13、获取法律口语化文本及其对应语意的书面文本作为训练数据;
14、将口语化文本作为输入,将书面文本作为标签,对文本改写模型进行训练。
15、可选地,在本申请的一个实施例中,通过指代消解模型对书面文本数据进行指代消解,消除歧义文本,包括:
16、使用bert模型提取实体的嵌入表示;
17、根据嵌入表示进行实体指代关系预测;
18、根据实体指代关系的预测结果,对书面文本数据进行指代消解预测,从而得到经过指代消解的书面文本数据。
19、可选地,在本申请的一个实施例中,在通过指代消解模型对书面文本数据进行指代消解,消除歧义文本之前,包括:
20、获取对话数据;
21、通过对对话数据进行实体指代和指代关系标注,构建训练数据集;
22、利用训练数据集对指代消解模型进行训练。
23、可选地,在本申请的一个实施例中,将待识别文本数据输入多分类意图识别模型,生成待识别文本数据对应的多个意图,包括:
24、将待识别文本数据输入多分类意图识别模型,多分类意图识别模型自动识别意图数量和意图类别,并依次输出识别得到的多个意图。
25、为达上述目的,本发明第二方面实施例提出了一种基于多标签分类模型实现的法律多意图识别装置,包括:
26、第一获取模块,用于获取原始法律咨询的文本数据和咨询意图,对文本数据进行预处理;
27、训练模块,用于将预处理后的文本数据作为输入,将文本数据对应的咨询意图作为标签对glm模型进行微调训练,得到多分类意图识别模型;
28、第二获取模块,用于获取待识别文本数据,对待识别文本数据进行预处理;
29、生成模块,用于将待识别文本数据输入多分类意图识别模型,生成待识别文本数据对应的多个意图。
30、可选地,在本申请的一个实施例中,对文本数据进行预处理,包括:
31、使用文本改写模型将文本数据改写为书面文本数据;
32、通过指代消解模型对书面文本数据进行指代消解,消除歧义文本;
33、去除经过指代消解的书面文本数据的停用词;
34、分别对去除停用词的书面文本数据提取关键词和文本摘要,得到关键词和文本摘要。
35、为达上述目的,本发明第三方面实施例提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时,实现上述施例所述的基于多标签分类模型实现的法律多意图识别方法。
36、为了实现上述目的,本发明第四方面实施例提出了一种非临时性计算机可读存储介质,当所述存储介质中的指令由处理器被执行时,能够执行一种基于多标签分类模型实现的法律多意图识别方法。
37、本申请基于多标签分类模型实现的法律多意图识别方法、装置、计算机设备和非临时性计算机可读存储介质,解决了现有意图识别方法难以准确完整的识别咨询者的意图的技术问题,通过使用少量数据对模型进行训练,使得模型能够在法律意图识别中更加客观准确的分析咨询者的意图,提升了识别效率、准确率和全面性。
38、本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
技术特征:
1.一种基于多标签分类模型实现的法律多意图识别方法,其特征在于,包括以下步骤:
2.如权利要求1所述的方法,其特征在于,对所述文本数据进行预处理,包括:
3.如权利要求2所述的方法,其特征在于,在所述使用文本改写模型将所述文本数据改写为书面文本数据之前,包括:
4.如权利要求2所述的方法,其特征在于,所述通过指代消解模型对所述书面文本数据进行指代消解,消除歧义文本,包括:
5.如权利要求4所述的方法,其特征在于,在所述通过指代消解模型对所述书面文本数据进行指代消解,消除歧义文本之前,包括:
6.如权利要求1所述的方法,其特征在于,所述将所述待识别文本数据输入多分类意图识别模型,生成所述待识别文本数据对应的多个意图,包括:
7.一种基于多标签分类模型实现的法律多意图识别装置,其特征在于,包括:
8.如权利要求7所述的装置,其特征在于,对所述文本数据进行预处理,包括:
9.一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如权利要求1-6中任一所述的方法。
10.一种非临时性计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-6中任一所述的方法。
技术总结
本申请提出了一种基于多标签分类模型实现的法律多意图识别方法,涉及意图识别技术领域,其中,该方法包括:获取原始法律咨询的文本数据和咨询意图,对文本数据进行预处理;将预处理后的文本数据作为输入,将文本数据对应的咨询意图作为标签对GLM模型进行微调训练,得到多分类意图识别模型;获取待识别文本数据,对待识别文本数据进行预处理;将待识别文本数据输入多分类意图识别模型,生成待识别文本数据对应的多个意图。本申请通过模型学习能够在法律意图识别中更加客观准确的分析咨询者的意图,提升了识别效率、准确率和全面性。
技术研发人员:张泽龙
受保护的技术使用者:北京智谱华章科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!