基于多模态影像的图像融合方法、设备及介质与流程
本申请涉及图像处理领域,具体涉及一种基于多模态影像的图像融合方法、设备及介质。
背景技术:
1、在泛血管手术领域中,通常医生在x光成像的引导下进行手术,辅以造影剂的注射获取数字减影血管造影,通过肉眼观察和经验判断,判定如何继续手术器械的推送以及器械的放置;通常在手术过程中cta影像和x光成像的手术引导和辅助是各自独立的。
2、发明人发现,尽管已有厂商推出了cta与x光成像融合显示的功能(如ge assist、philips vessel navigation等),但大部分产品采用的是简单的刚性配准融合,术前的三维模型与术中的组织器官的实际的形态有较大的差异,二维与三维解剖学信息未能充分互补,导致融合影像未能带来最佳的引导效果,并且,由于术前采集cta时和术中获取x光影像时静态和动态不完全匹配,患者姿态变化、组织器官形变不同,融合显示存在较大的误差,应用于术中导航效率较低。
技术实现思路
1、针对现有技术中的问题,本申请提供一种基于多模态影像的图像融合方法、设备及介质,能够准确融合匹配三维静态影像数据和二维动态影像数据。
2、为了解决上述问题中的至少一个,本申请提供以下技术方案:
3、第一方面,本申请提供一种基于多模态影像的图像融合方法,包括:
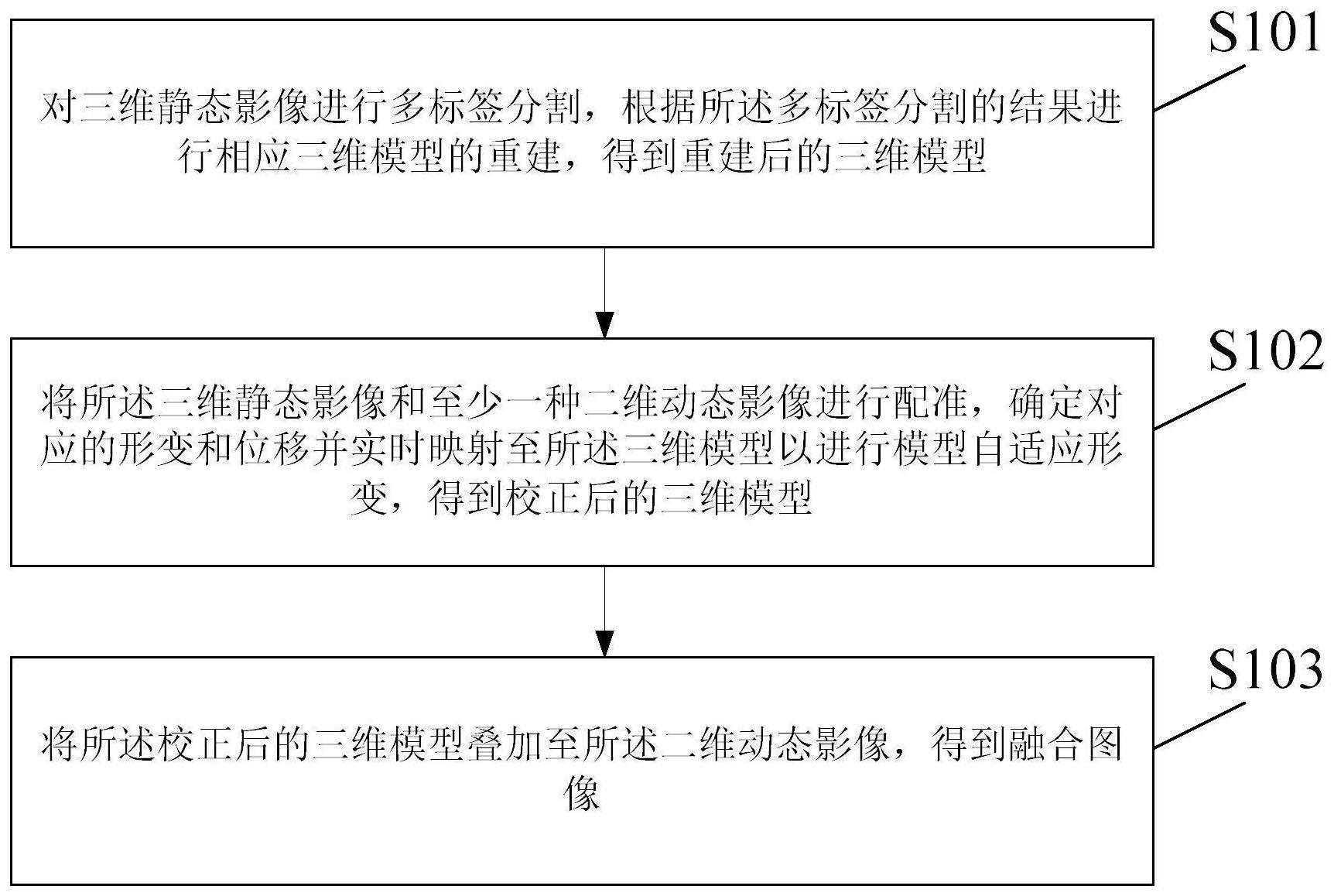
4、对三维静态影像进行多标签分割,根据所述多标签分割的结果进行相应三维模型的重建,得到重建后的三维模型;
5、将所述三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移并实时映射至所述三维模型以进行模型自适应形变,得到校正后的三维模型;
6、将所述校正后的三维模型叠加至所述二维动态影像,得到融合图像。
7、进一步地,在所述对三维静态影像进行多标签分割之前,包括:
8、对输入的三维静态影像进行视场数量判断;
9、若存在多个视场的三维静态影像,则对所述多个视场的三维静态影像进行影像融合,得到经过所述影像融合后的三维静态影像。
10、进一步地,所述对所述多个视场的三维静态影像进行影像融合,得到经过所述影像融合后的三维静态影像,包括:
11、根据预设轴向距离对所述多个视场的三维静态影像进行重采样;
12、根据所述重采样后的多个视场的三维静态影像以及各自的空间位置进行影像融合,得到经过所述影像融合后的三维静态影像。
13、进一步地,所述根据预设轴向距离对所述多个视场的三维静态影像进行重采样,包括:
14、根据预设轴向距离和所述多个视场的三维静态影像的体素数量以及对应的物理长度,对所述多个视场的三维静态影像进行重采样,得到经过所述重采样后的三维静态影像。
15、进一步地,所述根据所述重采样后的多个视场的三维静态影像以及各自的空间位置进行影像融合,得到经过所述影像融合后的三维静态影像,包括:
16、根据所述重采样后的多个视场的三维静态影像不同横断面的坐标轴位置和空间偏移信息确定多个视场的三维静态影像的对应关系;
17、根据所述多个视场的三维静态影像的对应关系进行影像融合,得到经过所述影像融合后的三维静态影像。
18、进一步地,所述对三维静态影像进行多标签分割,根据所述多标签分割的结果进行相应三维模型的重建,得到重建后的三维模型,包括:
19、根据预设深度学习语义分割算法对三维静态影像进行多标签分割,得到多标签分割的结果;
20、对所述多标签分割的结果进行结果融合后对相应的三维模型进行模型重建,得到重建后的三维模型。
21、进一步地,所述根据预设深度学习语义分割算法对三维静态影像进行多标签分割,得到多标签分割的结果,包括:
22、提取三维静态影像图像特征;
23、根据预设分类器和损失函数对预设深度学习语义分割算法进行模型训练,并根据经过所述模型训练后的深度学习语义分割算法和所述三维静态影像图像特征进行多标签分割,得到多标签分割的结果。
24、进一步地,所述将所述三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移,包括:
25、将二维动态影像转换为直接数字化x射线影像;
26、对所述直接数字化x射线影像和所述三维静态影像进行图像特征匹配,并根据所述图像特征匹配的结果确定对应的线性变换矩阵,其中,所述线性变换矩阵包含对应的形变和位移信息。
27、进一步地,所述将所述三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移包括:
28、对所述三维静态影像和至少一种二维动态影像进行特征提取;
29、根据所述特征提取结果确定对应的形变场,其中,所述形变场包含对应的形变和位移信息。
30、进一步地,所述确定对应的形变和位移,包括:
31、根据预设视频语义分割算法对配准后的影像进行目标部位分割;
32、根据所述目标部位分割的结果进行连续帧分割结果比较,确定实时位移和形变信息。
33、进一步地,所述确定对应的形变和位移并实时映射至所述三维模型以进行模型自适应形变,得到校正后的三维模型,包括:
34、根据确定的形变和位移确定所述三维模型中对应的参照截面;
35、根据所述参照截面和设定中心线将所述形变和位移实时映射至所述三维模型,得到校正后的三维模型。
36、进一步地,在所述根据所述参照截面和设定中心线将所述形变和位移实时映射至所述三维模型之前,包括:
37、根据所述多标签分割的结果提取目标部分的各区域边界并基于欧式距离获取各区域边界对应的最大内切球;
38、根据所述内切球球心确定所述区域边界所在平面与中心线的交点,并根据所述交点的连线确定中心线。
39、第二方面,本申请提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述的基于多模态影像的图像融合方法的步骤。
40、第三方面,本申请提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述的基于多模态影像的图像融合方法的步骤。
41、第四方面,本申请提供一种计算机程序产品,包括计算机程序/指令,该计算机程序/指令被处理器执行时实现所述的基于多模态影像的图像融合方法的步骤。
42、由上述技术方案可知,本申请提供一种基于多模态影像的图像融合方法、设备及介质,通过深度学习算法对获取的三维静态影像数据进行多标签分割,并在分割基础上实现测量和三维重建,形成准确的静态三维模型,将三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移并实时映射至三维模型以进行模型自适应形变,矫正融合显示结果,将自适应形变后的三维模型叠加至所述二维动态影像,得到融合图像,由此能够准确融合匹配三维静态影像数据和二维动态影像数据。
技术特征:
1.一种基于多模态影像的图像融合方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于多模态影像的图像融合方法,其特征在于,在所述对三维静态影像进行多标签分割之前,包括:
3.根据权利要求2所述的基于多模态影像的图像融合方法,其特征在于,所述对所述多个视场的三维静态影像进行影像融合,得到经过所述影像融合后的三维静态影像,包括:
4.根据权利要求3所述的基于多模态影像的图像融合方法,其特征在于,所述根据预设轴向距离对所述多个视场的三维静态影像进行重采样,包括:
5.根据权利要求3所述的基于多模态影像的图像融合方法,其特征在于,所述根据所述重采样后的多个视场的三维静态影像以及各自的空间位置进行影像融合,得到经过所述影像融合后的三维静态影像,包括:
6.根据权利要求1所述的基于多模态影像的图像融合方法,其特征在于,所述对三维静态影像进行多标签分割,根据所述多标签分割的结果进行相应三维模型的重建,得到重建后的三维模型,包括:
7.根据权利要求6所述的基于多模态影像的图像融合方法,其特征在于,所述根据预设深度学习语义分割算法对三维静态影像进行多标签分割,得到多标签分割的结果,包括:
8.根据权利要求1所述的基于多模态影像的图像融合方法,其特征在于,所述将所述三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移,包括:
9.根据权利要求1所述的基于多模态影像的图像融合方法,其特征在于,所述将所述三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移包括:
10.根据权利要求1所述的基于多模态影像的图像融合方法,其特征在于,所述确定对应的形变和位移,包括:
11.根据权利要求1所述的基于多模态影像的图像融合方法,其特征在于,所述确定对应的形变和位移并实时映射至所述三维模型以进行模型自适应形变,得到校正后的三维模型,包括:
12.根据权利要求11所述的基于多模态影像的图像融合方法,其特征在于,在所述根据所述参照截面和设定中心线将所述形变和位移实时映射至所述三维模型之前,包括:
13.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至12任一项所述的基于多模态影像的图像融合方法的步骤。
14.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现权利要求1至12任一项所述的基于多模态影像的图像融合方法的步骤。
技术总结
本申请实施例提供一种基于多模态影像的图像融合方法、设备及介质,方法包括:对三维静态影像进行多标签分割,根据所述多标签分割的结果进行相应三维模型重建,得到重建后的三维模型;将所述三维静态影像和至少一种二维动态影像进行配准,确定对应的形变和位移并实时映射至所述三维模型以进行模型自适应形变,得到校正后的三维模型;将所述校正后的三维模型叠加至所述二维动态影像,得到融合图像;本申请能够准确融合匹配三维静态影像数据和二维动态影像数据。
技术研发人员:请求不公布姓名
受保护的技术使用者:深圳微美机器人有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!