基于多级缓存的快速可解释性方法
1.本发明涉及的是一种机器学习领域的技术,具体是一种基于多级缓存的快速可解释性方法。
背景技术:
2.随着互联网的快速发展,人工智能和大数据技术带动了推荐系统的繁荣发展。推荐系统的模型生成同时需要给出解释,即1)机器学习模型本质的可解释性和事后的可解释性;2)特定机器学习模型的可解释性和机器学习模型无关的可解释性;3)局部的可解释性和全局的可解释性。
技术实现要素:
3.本发明针对现有技术生成解释结果的过程缓慢,在实时性要求高的场景,实时生成推荐结果的解释是比较迟缓的不足,提出一种基于多级缓存的快速可解释性方法,比传统的每传入一次数据都要启动解释响应速度加快,可应用于推荐模型开发人员和实际的推荐系统场景中,告知模型建模人员或者使用用户得到推荐物品的本质原因。
4.本发明是通过以下技术方案实现的:
5.本发明涉及一种基于多级缓存的快速可解释性方法,分别通过本地缓存在同一个进程内的内存空间中以及通过分布式缓存中缓存历史数据解释性报告用于快速读取,依次通过唯一标识检索本地缓存和分布式缓存失败后以零拷贝方式传输,减少数据在内核缓冲区和用户进程缓冲区之间反复的i/o拷贝操作以及用户进程地址空间和内核地址空间之间因为上下文切换而带来的cpu开销。
6.所述的零拷贝(zero-copy)方式是指:在计算机执行操作时,cpu不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及cpu的拷贝时间。它的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现cpu的零参与,彻底消除cpu在这方面的负载。实现零拷贝用到的最技术是dma数据传输技术和内存区域映射技术。
附图说明
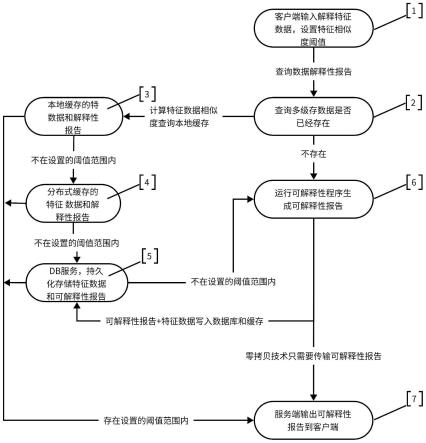
7.图1为本发明流程图。
具体实施方式
8.如图1所示,为本实施例涉及一种基于多级缓存的快速可解释性方法,包括:
9.步骤1)互联网客户端输入待解释的数据特征和实际待解释的数据,将输入处理成唯一标识;
10.所述的唯一标识包括:hashcode,uuid,snowflake算法生成的id等。
11.步骤2)将输入的唯一标识发送至本地缓存并且查询。
12.步骤3)当唯一标识的解释性报告数据命中时直接返回结果报告给客户端,解释报告直接生成显示给客户端,直接响应,转到步骤7);否则将输入的唯一标识发送至分布式缓存并且查询,转到步骤4)。
13.步骤4)当唯一标识的解释性报告数据命中时直接返回结果报告给客户端,解释报告直接生成显示给客户端,直接响应,转到步骤7);否则转到步骤5)。
14.步骤5)通过数据库存储服务查询唯一标识的解释性报告数据,当查询命中时直接返回解释性报告给客户端,解释报告直接生成显示给客户端,直接响应,转到步骤7);否则转到步骤6)。
15.步骤6)通过可解释性报告的程序生成可解释性报告后,通过零拷贝方式将报告直接输出至客户端,再通知分布式缓存和数据库存储并转到步骤7)。
16.所述的可解释性报告的程序是指:给模型建模人员解释模型做出推荐结果的原因或者给用户解释给出推荐列表的原因(比如,您的好友也购买了某商品,您的好友也喜欢本视频)
17.所述的零拷贝(zero-copy)方式是指:在计算机执行操作时,cpu不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及cpu的拷贝时间。它的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现cpu的零参与,彻底消除cpu在这方面的负载。实现零拷贝用到的最技术是dma数据传输技术和内存区域映射技术。
18.步骤7)通过客户端以页面渲染、文字显示、图片、语音等方式展现解释性报告。
19.上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
技术特征:
1.一种基于多级缓存的快速可解释性方法,其特征在于,分别通过本地缓存在同一个进程内的内存空间中以及通过分布式缓存中缓存历史数据解释性报告用于快速读取,依次通过唯一标识检索本地缓存和分布式缓存失败后以零拷贝方式传输,减少数据在内核缓冲区和用户进程缓冲区之间反复的i/o拷贝操作以及用户进程地址空间和内核地址空间之间因为上下文切换而带来的cpu开销;所述的零拷贝方式是指:在计算机执行操作时,cpu不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及cpu的拷贝时间,它的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现cpu的零参与,彻底消除cpu在这方面的负载,实现零拷贝用到的最技术是dma数据传输技术和内存区域映射技术。2.根据权利要求1所述的基于多级缓存的快速可解释性方法,其特征是,具体包括:步骤1)互联网客户端输入待解释的数据特征和实际待解释的数据,将输入处理成唯一标识;所述的唯一标识包括:hashcode,uuid,snowflake算法生成的id;步骤2)将输入的唯一标识发送至本地缓存并且查询;步骤3)当唯一标识的解释性报告数据命中时直接返回结果报告给客户端,解释报告直接生成显示给客户端,直接响应,转到步骤7);否则将输入的唯一标识发送至分布式缓存并且查询,转到步骤4);步骤4)当唯一标识的解释性报告数据命中时直接返回结果报告给客户端,解释报告直接生成显示给客户端,直接响应,转到步骤7);否则转到步骤5);步骤5)通过数据库存储服务查询唯一标识的解释性报告数据,当查询命中时直接返回解释性报告给客户端,解释报告直接生成显示给客户端,直接响应,转到步骤7);否则转到步骤6);步骤6)通过可解释性报告的程序生成可解释性报告后,通过零拷贝方式将报告直接输出至客户端,再通知分布式缓存和数据库存储并转到步骤7);步骤7)通过客户端以页面渲染、文字显示、图片、语音方式展现解释性报告。3.根据权利要求1所述的基于多级缓存的快速可解释性方法,其特征是,所述的可解释性报告的程序是指:给模型建模人员解释模型做出推荐结果的原因或者给用户解释给出推荐列表的原因。
技术总结
一种基于多级缓存的快速可解释性方法,分别通过本地缓存在同一个进程内的内存空间中以及通过分布式缓存中缓存历史数据解释性报告用于快速读取,依次通过唯一标识检索本地缓存和分布式缓存失败后以零拷贝方式传输,减少数据在内核缓冲区和用户进程缓冲区之间反复的I/O拷贝操作以及用户进程地址空间和内核地址空间之间因为上下文切换而带来的CPU开销。本发明比传统的每传入一次数据都要启动解释响应速度加快,可应用于推荐模型开发人员和实际的推荐系统场景中,告知模型建模人员或者使用用户得到推荐物品的本质原因。用用户得到推荐物品的本质原因。用用户得到推荐物品的本质原因。
技术研发人员:彭岗 卢宏涛
受保护的技术使用者:上海交通大学
技术研发日:2022.11.21
技术公布日:2023/3/6
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1