一种基于视频图像的内涝场景下行人风险评估方法
1.本发明涉及一种基于视频图像的内涝场景下行人风险评估方法,技术应用领域为应急管理和城市排水防涝等。
背景技术:
2.受快速城镇化和气候变化等影响,我国很多城市面临日益严峻的内涝问题。城市内涝造成城市机能瘫痪,影响生产生活,给人民生命财产造成重大损失。内涝灾害风险评估可为排水防涝规划、应急管理、防灾减灾提供科学依据,从而有效减轻内涝造成的损失。
3.城市内涝灾害风险评估主要侧重于城市尺度和社区尺度的内涝灾害风险评估。面向内涝场景下行人安全的风险评估技术还很少,已有技术一般仅考虑积水深度等危险性指标,利用城市排水模型得到不同降水重现期下的行人风险等级空间分布图。
4.现有技术缺少对行人的性别、年龄段、人体淹没部位等脆弱性和危险性指标的考虑,没有形成对行人风险的综合评估。现有技术缺少引入实时监测数据,难以对行人风险做到实时动态评估。随着智慧城市和平安城市的建设,城市当中布设了大量视频监控设备,以视频图像的方式记录着城市动态。内涝场景下的视频图像中蕴含了行人性别、年龄段和人体淹没部位等信息,因此视频图像为内涝场景下的行人风险评估提供了监测数据支撑。
技术实现要素:
5.本发明针对现有技术的不足,提供一种基于视频图像的内涝场景下行人风险评估方法,该方法从视频图像中自动提取出内涝场景下的行人性别、年龄段和人体淹没部位等脆弱性和危险性指标信息,构建综合考虑脆弱性指数和危险性指数的行人风险指数模型,在此基础上实现对行人风险的实时、动态和综合评估。
6.一种基于视频图像的内涝场景下行人风险评估方法的实现具体包括如下步骤:
7.步骤(1)内涝场景下行人检测
8.从内涝场景下的视频图像中检测出行人,记录包含行人目标的外接矩形框;
9.步骤(2)内涝场景下行人性别识别
10.①
构建内涝场景下的行人性别分类器:将用于二分类的softmax层及其全连接层替换inception-v3模型原有softmax层及其全连接层,得到新inception-v3模型,将利用内涝场景下的男性和女性行人图像集训练过的新inception-v3模型作为内涝场景下的行人性别分类器;
11.②
利用该性别分类器识别出外接矩形框范围内行人的性别;
12.步骤(3)内涝场景下行人年龄段识别
13.①
构建行人年龄段分类器:将用于三分类的softmax层及其全连接层替换inception-v3模型原有softmax层及其全连接层,得到新inception-v3模型,将利用内涝场景下的少年、壮年和老年行人图像集训练过的新inception-v3模型作为内涝场景下的行人年龄段分类器;
14.②
利用该年龄段分类器识别出外接矩形框范围内行人的年龄段;
15.步骤(4)水面分割
16.①
利用labelme工具为水面分割准备所需训练数据集,训练segnet模型;
17.②
利用segnet模型从视频图像中分割出水面,记录水面的多边形区域范围;
18.步骤(5)行人淹没部位判别
19.①
根据行人目标外接矩形框与水面多边形区域的空间关系,判断出行人是否处于积水当中;
20.②
对于未处于积水当中的行人,其淹没部位为“无”;
21.③
对于处于积水当中的行人,利用openpose检测出外接矩形框范围内行人的人体部位关键点并存储关键点信息;根据人体部位关键点信息推断出行人被积水淹没的大致部位;
22.步骤(6)内涝场景下行人风险指数评估
23.①
将行人的性别和年龄段组合作为脆弱性指标,将行人的淹没部位作为危险性指标;
24.②
采用专家调查问卷方式确定各个性别和年龄段组合对应的脆弱性指数以及各个淹没部位对应的危险性指数;
25.③
将行人个体的脆弱性指数与行人个体的危险性指数乘积定义为行人的个体风险指数;将视频图像范围内所有行人的个体风险指数之和定义为行人的总体风险指数;将视频图像范围内所有行人的个人风险指数的平均值定义为行人的平均风险指数;
26.④
从视频图像中提取各个行人个体的性别、年龄段和人体淹没部位,根据性别、年龄段和人体淹没部位分别得到对应的脆弱性指数和危险性指数,进而计算得到行人的个体风险指数、总体风险指数和平均风险指数。
27.作为优选,所述的步骤(1)中内涝场景下的行人检测,是通过利用yolov5模型检测出行人目标,得到行人目标的外接矩形框。
28.作为优选,所述的步骤(2)中内涝场景下的行人性别识别,具体包括以下步骤:
29.①
搜集内涝场景下的行人图像,通过人工判别将行人分为男性和女性两类,构建内涝场景下的行人性别图像样本库;
30.②
将用于二分类的softmax层及其全连接层替换原始inception-v3模型原有的softmax层及其全连接层,得到新的inception-v3模型;
31.③
使用内涝场景下的行人性别图像样本库训练这个新的inception-v3模型的softmax层及其全连接层的参数,模型其它层的参数保持不变,模型优化采用adam算法,得到基于inception-v3模型的内涝场景下行人性别分类器;
32.④
获取行人目标的外接矩形框内图像,将其输入至该行人性别分类器计算得到行人性别。
33.作为优选,所述的步骤(3)中内涝场景下的行人年龄段识别,具体包括以下步骤:
34.①
搜集内涝场景下的行人图像,通过人工判别将行人分为少年、壮年和老年三类,构建内涝场景下的行人年龄段图像样本库;
35.②
将用于三分类的softmax层及其全连接层替换原始inception-v3模型原有的softmax层及其全连接层,得到新的inception-v3模型;
36.③
使用内涝场景下的行人年龄段图像样本库训练这个新的inception-v3模型的softmax层及其全连接层的参数,模型其它层的参数保持不变,模型优化采用adam算法,得到基于inception-v3模型的内涝场景下行人年龄段分类器;
37.④
获取行人目标的外接矩形框内图像,将其输入至该行人年龄段分类器计算得到行人年龄段。
38.作为优选,所述的步骤(4)中利用labelme工具为水面分割准备所需训练数据集,训练segnet模型,具体为:利用labelme工具标注出图像中的水面以及背景物,标注后会生成对应的json文件,再利用json文件生成训练segnet模型所需的数据集;利用生成的数据集训练segnet模型,模型优化采用adam算法。
39.作为优选,所述的步骤(5)中根据人体部位关键点信息推断出行人被积水淹没的大致部位,具体包括以下步骤:
40.步骤
①
根据存储信息,依次为左眼、右眼、左耳、右耳、鼻子、脖子、左肩膀、右肩膀、左臀部、右臀部、左膝盖、右膝盖、左脚踝和右脚踝这些关键点分别创建一个元组对象[关键点的名称,关键点的x值,关键点的y值和关键点的c值],x值和y值代表关键点位置信息,c值代表置信度;将这些元组对象按照同样的顺序依次入栈,入栈完成后,栈顶的元组对象为右脚踝的元组对象,栈底的元组对象为左眼的元组对象;需要说明的是,若关键点被积水淹没,会导致关键点被openpose检测不到,关键点的[x值,y值,c值]会被openpose赋值为[0,0,0];
[0041]
步骤
②
读取栈顶的元组对象,判断该元组对象的[x值,y值,c值]是否为[0,0,0]。若[x值,y值,c值]为[0,0,0],则该元组对象出栈,继续回到步骤
②
;否则,进入步骤
③
;
[0042]
步骤
③
根据该元组对象的关键点名称确定淹没部位,确定淹没部位的规则如下:
[0043]
·
若关键点名称为左脚踝或右脚踝,则淹没部位为脚踝以下;
[0044]
·
若关键点名称为左膝盖或右膝盖,则淹没部位为脚踝~膝盖;
[0045]
·
若关键点名称为左臀部或右臀部,则淹没部位为膝盖~臀部;
[0046]
·
若关键点名称为左肩膀或右肩膀,则淹没部位为臀部~肩膀;
[0047]
·
若关键点名称为脖子、鼻子、左耳朵、右耳朵、左眼睛或右眼睛,则淹没范围为肩膀以上。
[0048]
本发明的有益效果:
[0049]
1、该发明综合考虑行人的脆弱性指标和危险性指标,实现对内涝场景下行人风险的综合评估。
[0050]
2、该发明充分利用视频图像中蕴含的行人性别、年龄段和人体淹没部位等信息,实现对内涝场景下行人风险的实时动态评估。
[0051]
3、该发明有助于及时发现、提醒和疏散风险指数较高的行人,减少对行人安全的威胁和财产损失。
附图说明
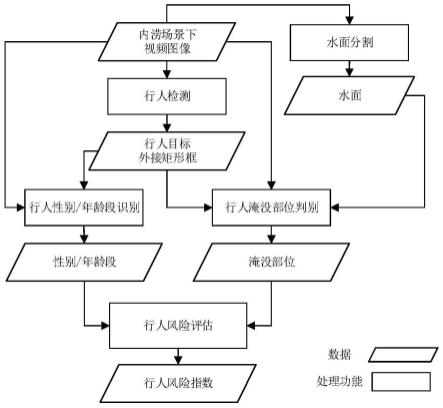
[0052]
图1为本发明的实现流程图;
[0053]
图2(a)为行人处于积水当中的示意图;
[0054]
图2(b)为行人未处于积水当中的示意图;
[0055]
图3为根据关键点确定淹没部位的示意图。
具体实施方式
[0056]
下面结合如图1所示的流程图,说明本发明的具体实施方法:
[0057]
步骤(1)内涝场景下行人检测
[0058]
①
利用yolov5模型从内涝视频图像中自动检测出图像区域范围内的所有行人目标,识别出的行人目标可能是完整的行人目标,也可能是行人在积水水面以上部分的目标;
[0059]
②
记录包含各个行人目标的外接矩形框;
[0060]
步骤(2)内涝场景下行人性别识别
[0061]
具体步骤:
①‑③
为内涝场景下行人识别分类器的构建和训练过程,
④
为行人性别分类器的应用。
[0062]
①
搜集内涝场景下的行人图像,通过人工判别将行人图像分为男性和女性两类,构建内涝场景下的行人性别图像样本库;
[0063]
②
将用于二分类的softmax层及其全连接层替换原始inception-v3模型的softmax层及其全连接层,得到新的inception-v3模型;
[0064]
③
使用内涝场景下的行人性别图像样本库训练这个新的inception-v3模型的softmax层及其全连接层的参数,模型其它层的参数保持不变,模型优化采用adam算法,得到基于inception-v3模型的内涝场景下行人性别分类器;
[0065]
④
获取行人目标的外接矩形框内图像,将其输入至该行人性别分类器计算得到行人性别;
[0066]
步骤(3)内涝场景下行人年龄段识别
[0067]
具体步骤:
①‑③
为内涝场景下行人年龄段分类器的构建和训练过程,
④
为行人年龄段分类器的应用。
[0068]
①
搜集内涝场景下的行人图像,通过人工判别将行人分为少年(0-14岁)、壮年(15-64岁)和老年(65岁及以上)三类,构建内涝场景下的行人年龄段图像样本库;
[0069]
②
将用于三分类的softmax层及其全连接层替换原始inception-v3模型原有的softmax层及其全连接层,得到新的inception-v3模型;
[0070]
③
使用内涝场景下的行人年龄段图像样本库训练这个新的inception-v3模型的softmax层及其全连接层的参数,模型其它层的参数保持不变,模型优化采用adam算法,得到基于inception-v3模型的内涝场景下行人年龄段分类器;
[0071]
④
获取行人目标的外接矩形框内图像,将其输入至该行人年龄段分类器计算得到行人年龄段;
[0072]
步骤(4)水面分割
[0073]
①
搜集内涝场景下的视频或图像,将视频数据转为图像;
[0074]
②
利用labelme工具标注出图像中的水面以及车辆、行人、道路、建筑物等“背景”物,标注后会生成对应的json文件,再利用json文件生成训练segnet模型所需的数据集;利用生成的数据集训练segnet模型,segnet模型优化采用adam算法;
[0075]
③
利用训练过的segnet模型从内涝场景下的视频图像中分割出水面,记录水面的多边形区域范围;
[0076]
步骤(5)行人淹没部位判别
[0077]
①
根据行人目标外接矩形框与水面多边形区域的空间关系,判断出行人是否处于积水当中:若外接矩形框底部边的一个或两个角点在水面多边形内或多边形边上,则判定行人处于积水当中(图2(a)),否则判定行人没有处于积水当中(图2(b));
[0078]
②
对于未处于积水当中的行人,其淹没部位为“无”;
[0079]
③
对于处于积水当中的行人:
[0080]
首先,利用openpose模型检测外接矩形框范围内行人的人体关键点(包括左右脚踝、左右膝盖、左右臀部、左右肩膀、左右肘、左右腕、脖子、鼻子、左右眼睛、左右耳朵等关键点),并将关键点信息存储到一个json文件当中;
[0081]
然后,使用左右脚踝、左右膝盖、左右臀部、左右肩膀、脖子、鼻子、左右耳朵、左右眼睛这些关键点推断行人被积水淹没的大致部位(图3),具体步骤如下:
[0082]
步骤1)根据存储关键点信息的json文件,依次为左眼、右眼、左耳、右耳、鼻子、脖子、左肩膀、右肩膀、左臀部、右臀部、左膝盖、右膝盖、左脚踝和右脚踝等关键点分别创建一个元组对象[关键点的名称,关键点的x值,关键点的y值和关键点的c值],x值和y值代表关键点位置信息,c值代表置信度信息;将这些元组对象按照同样的顺序依次入栈,入栈完成后,栈顶的元组对象为右脚踝的元组对象,栈底的元组对象为左眼的元组对象;需要说明的是,若关键点被积水淹没,会导致关键点被openpose检测不到,关键点的[x值,y值,c值]会被openpose赋值为[0,0,0];
[0083]
步骤2)读取栈顶的元组对象,判断该元组对象的[x值,y值,c值]是否为[0,0,0]。若[x值,y值,c值]为[0,0,0],则该元组对象出栈,继续回到步骤2);否则,进入步骤3);
[0084]
步骤3)根据该元组对象的关键点的名称确定淹没部位,确定淹没部位的规则如下:
[0085]
·
若关键点名称为左脚踝或右脚踝,则淹没部位为脚踝以下;
[0086]
·
若关键点名称为左膝盖或右膝盖,则淹没部位为脚踝~膝盖;
[0087]
·
若关键点名称为左臀部或右臀部,则淹没部位为膝盖~臀部;
[0088]
·
若关键点名称为左肩膀或右肩膀,则淹没部位为臀部~肩膀;
[0089]
·
若关键点名称为脖子、鼻子、左耳朵、右耳朵、左眼睛或右眼睛,则淹没范围为肩膀以上;
[0090]
步骤(6)行人风险评估
[0091]
①
将性别和年龄段组合(包括男性-少年、女性-少年、男性-壮年、女性-壮年、男性-老年和女性-老年)作为脆弱性指标,将淹没部位(包括无、脚踝以下、脚踝~膝盖、膝盖~臀部、臀部~肩膀和肩膀以上)作为危险性指标;
[0092]
②
采用专家调查问卷方式确定各个性别和年龄段组合所对应的脆弱性指数以及各个淹没部位所对应的危险性指数;
[0093]
③
将行人个体的脆弱性指数和危险性指数的乘积定义为行人个体的风险指数,行人个体的风险指数模型如式(1):
[0094][0095]
其中,为t时刻第i个行人的个体风险指数,为t时刻第i个行人的个体危险性
指数,v
it
为t时刻第i个行人的个体脆弱性指数;
[0096]
④
将视频图像范围内所有行人的个体风险指数之和定义为行人的总体风险指数,行人的总体风险指数模型如式(2):
[0097][0098]
其中,r
t
为t时刻行人的总体风险指数,n为行人的数量;
[0099]
⑤
将视频图像范围内所有行人的个人风险指数的平均值定义为行人的平均风险指数,行人的平均风险指数模型如式(3):
[0100][0101]
其中为t时刻行人的平均风险指数;
[0102]
⑥
从视频各个时刻的图像中提取各个行人个体的性别、年龄段和人体淹没部位后,根据性别、年龄段和人体淹没部位分别得到对应的脆弱性指数和危险性指数,依次代入式(1)、式(2)和式(3)分别得到视频图像范围内对应时刻的行人的个体风险指数、总体风险指数和平均风险指数。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1