一种提升表情基表达能力的方法、装置、设备及介质与流程
本申请涉及计算机动画,具体而言,涉及一种提升表情基表达能力的方法、装置、设备及介质。
背景技术:
1、传统的人脸动画采用多视角三维重建的人脸表情直接驱动人脸模型的方式,这种方式会占用大量的内存,同时也不便于动画师进行编辑操作。随着计算机技术的飞速发展,重建人脸表情源数据通过转化为参数化的表情序列的形式来降低内存。
2、目前,较多使用通用的blendshape模型对重建的人脸表情进行参数化转化。使用通用的blendshape模型对重建的人脸表情得到参数,在不同人脸上会存在表达精度不足的问题,为了提高blendshape模型的表达精度,现有技术主要通过引进外部采集到的特定人脸表情,这里的采集方式主要包括对特定演员配合进行拍摄采集,或者通过人工刻画。上述提高blendshape模型精度的方式都需要额外的人工操作,效率较低。
技术实现思路
1、有鉴于此,本申请的目的在于提供一种提升表情基表达能力的方法、装置、设备及介质,在不需要人工外部输入数据的情况下,能够自动表情基的表达效果进行提升,降低了人工成本,提高了处理效率。
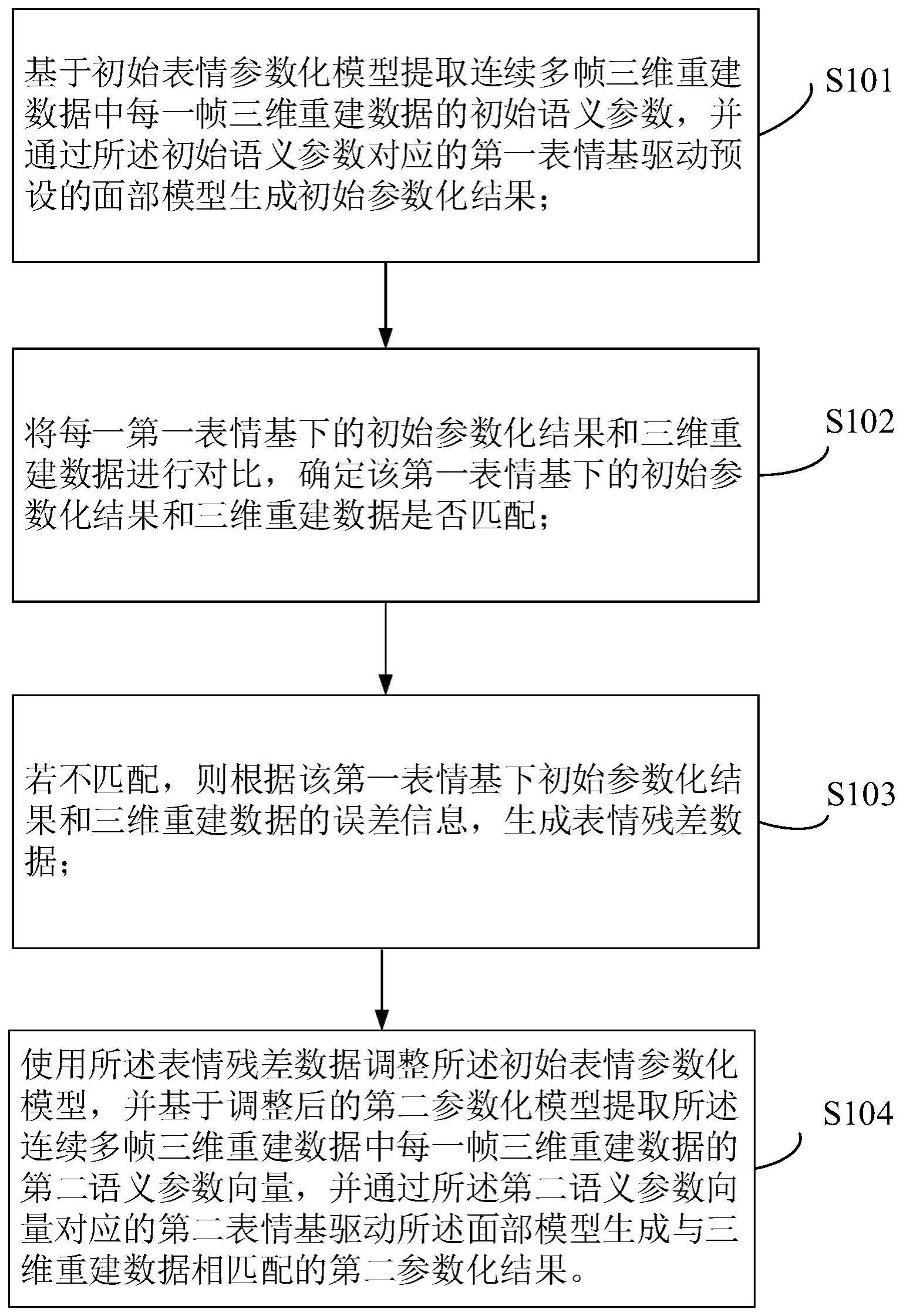
2、第一方面,本申请实施例提供了一种提升表情基表达能力的方法,所述方法包括:
3、基于初始表情参数化模型提取连续多帧三维重建数据中每一帧三维重建数据的初始语义参数,并通过所述初始语义参数对应的第一表情基驱动预设的面部模型生成初始参数化结果;
4、将每一第一表情基下的初始参数化结果和三维重建数据进行对比,确定该第一表情基下的初始参数化结果和三维重建数据是否匹配;
5、若不匹配,则根据该第一表情基下初始参数化结果和三维重建数据的误差信息,生成表情残差数据;
6、使用所述表情残差数据调整所述初始表情参数化模型,并基于调整后的第二参数化模型提取所述连续多帧三维重建数据中每一帧三维重建数据的第二语义参数向量,并通过所述第二语义参数向量对应的第二表情基驱动所述面部模型生成与三维重建数据相匹配的第二参数化结果。
7、第二方面,本申请实施例提供了一种提升表情基表达能力的装置,所述装置包括:
8、提取模块,用于基于初始表情参数化模型提取连续多帧三维重建数据中每一帧三维重建数据的初始语义参数,并通过所述初始语义参数对应的第一表情基驱动预设的面部模型生成初始参数化结果;
9、误差分析模块,用于将每一第一表情基下的初始参数化结果和三维重建数据进行对比,确定该第一表情基下的初始参数化结果和三维重建数据是否匹配;
10、生成模块,用于若不匹配,则根据该第一表情基下初始参数化结果和三维重建数据的误差信息,生成表情残差数据;
11、调整模块,用于使用所述表情残差数据调整所述初始表情参数化模型,并基于调整后的第二参数化模型提取所述连续多帧三维重建数据中每一帧三维重建数据的第二语义参数向量,并通过所述第二语义参数向量对应的第二表情基驱动所述面部模型生成与三维重建数据相匹配的第二参数化结果。
12、第三方面,本申请实施例提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的提升表情基表达能力的方法的步骤。
13、第四方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述的提升表情基表达能力的方法的步骤。
14、本申请的实施例提供的技术方案可以包括以下有益效果:
15、本申请方法包括:基于初始表情参数化模型提取连续多帧三维重建数据中每一帧三维重建数据的初始语义参数,并通过所述初始语义参数对应的第一表情基驱动预设的面部模型生成初始参数化结果;将每一第一表情基下的初始参数化结果和三维重建数据进行对比,确定该第一表情基下的初始参数化结果和三维重建数据是否匹配;若不匹配,则根据该第一表情基下初始参数化结果和三维重建数据的误差信息,生成表情残差数据;使用所述表情残差数据调整所述初始表情参数化模型,并基于调整后的第二参数化模型提取所述连续多帧三维重建数据中每一帧三维重建数据的第二语义参数向量,并通过所述第二语义参数向量对应的第二表情基驱动所述面部模型生成与三维重建数据相匹配的第二参数化结果。本申请能够对通过初始表情参数化模型得到的第一表情基进行分析,确定出该第一表情基下初始参数化结果和三维重建数据的误差信息,进而生成表情残差数据;使用表情残差数据对初始表情参数化模型进行调整,得到第二参数化模型;通过第二参数化模型能够得到的表达效果更好的第二表情基;不需要人工进行外部数据的输入,提高了效率。
16、为使本申请的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
技术特征:
1.一种提升表情基表达能力的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述三维重建数据中包含有预设数量的第一关键点;所述将每一第一表情基下的初始参数化结果和三维重建数据进行对比,包括:
3.根据权利要求2所述的方法,其特征在于,所述方法还包括:
4.根据权利要求1所述的方法,其特征在于,所述根据第一表情基下初始参数化结果和三维重建数据的误差信息,生成表情残差数据,包括:
5.根据权利要求1所述的方法,其特征在于,所述根据第一表情基下初始参数化结果和三维重建数据的误差信息,生成表情残差数据,包括:
6.根据权利要求1所述的方法,其特征在于,所述初始表情参数化模型中包含有第一数量的表情维度;所述使用所述表情残差数据对所述初始表情参数化模型进行调整,得到调整后的第二参数化模型,包括:
7.根据权利要求1所述的方法,其特征在于,通过以下方式得到第二参数化模型:
8.一种提升表情基表达能力的装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行如权利要求1至7任一所述的提升表情基表达能力的方法的步骤。
10.一种计算机可读存储介质,其特征在于,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如权利要求1至7任一所述的提升表情基表达能力的方法的步骤。
技术总结
本申请提供了一种提升表情基表达能力的方法、装置、设备及介质,该方法包括:基于初始表情参数化模型提取每一帧三维重建数据的初始语义参数,并通过初始语义参数对应的第一表情基驱动预设的面部模型生成初始参数化结果;将每一第一表情基下的初始参数化结果和三维重建数据进行对比,确定初始参数化结果和三维重建数据是否匹配;若不匹配,则根据初始参数化结果和三维重建数据的误差信息,生成表情残差数据;使用表情残差数据调整初始表情参数化模型,得到调整后的第二参数化模型,通过第二参数化模型确定的第二表情基驱动面部模型生成与三维重建数据相匹配的第二参数化结果。本申请不需要人工进行外部数据的输入,提高了效率。
技术研发人员:沈成泽,林杰,林传杰,侯杰
受保护的技术使用者:网易(杭州)网络有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!