基于分布式文件系统流式数据实时更新插入合并处理方法与流程
1.本发明属于大数据流式数据处理技术领域,尤其涉及一种基于分布式文件系统流式数据实时更新插入合并处理方法。
背景技术:
2.随着各行业的数据量日益增多以及业务的复杂化,在基于分布式文件系统来处理大批量数据的同时,对基于分布式文件系统处理大批量数据的时效性要求越来越高。在以往的数据接入到分布式文件系统的场景,我们只能批量的对接入的数据进行处理,无法实时的更新合并插入的数据,造成数据分析处理具有较高的延迟性。与此同时,随着数据接入分布式文件系统的方式向着流式环境的转变,如何在分布式文件系统中对流式数据的更新合并处理也成为当下需要解决的技术问题。
技术实现要素:
3.本发明要解决的技术问题是:提供一种基于分布式文件系统流式数据实时更新插入合并处理方法,以解决现有技术在分布式文件系统中无法实时对流数据更新插入的合并操作。
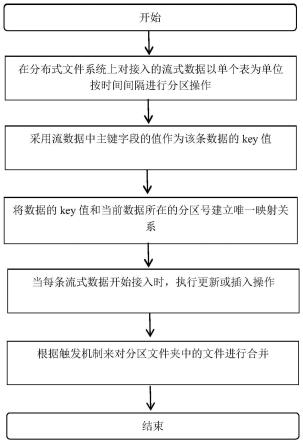
4.本发明技术方案:一种基于分布式文件系统流式数据实时更新插入合并处理方法,所述方法包括:步骤1、在分布式文件系统上对接入的流式数据以单个表为单位按时间间隔进行分区操作;步骤2、采用流数据中主键字段的值作为该条数据的key值;步骤3、将数据的key值和当前数据所在的分区号建立唯一映射关系,把这种映射关系存放在第三方数据库中,利用第三方数据库完成索引的构建;步骤4、当每条流式数据开始接入时,执行更新或插入操作;步骤5、根据触发机制来对分区文件夹中的文件进行合并。
5.一个分区为一个单独的文件夹,文件夹的名字以分区名来命名。分区名为当前文件夹的创建时间,格式为’年月日时分秒毫秒’。
6.key值为一条数据的全局唯一标识,用于判断该条数据是属于更新操作还是插入操作。
7.执行更新或插入操作的判断方法为:首先拿当前这条数据的key值在第三方数据库中的索引表去寻找,如果这条key存在,则该条数据为更新操作;如果这条key不存在,则该条数据为插入操作。
8.更新和插入操作的方法为:根据索引能够定位到当前这条数据所在的分区,将这该条数据直接追加到当前分区的log文件中;插入操作则是直接把这条数据追加到当前最新分区的log文件中,同时在索引库中增加该条数据的索引。
9.文件进行合并的方法为:在每个分区文件夹中有两种不同的文件类型,根据触发
机制来对分区文件夹中的文件进行合并;用log文件来存储单次合并前产生的新增数据,用parquet文件来存储合并后的数据,每次合并后都将把log文件删除。
10.文件进行合并分位主动合并和被动合并;被动合并指当对表进行访问时对所有的分区进行合并操作,然后把合并后最新的parquet文件作为最新的数据来访问。
11.主动合并指每创建一个分区时就对之前的所有分区进行合并。
12.本发明的有益效果:根据本发明提供的一种基于分布式文件系统流式数据实时更新插入合并处理方法,能够解决基于分布式文件系统流式数据的更新插入问题,使其能够实时的访问到分布式文件系统中最新的数据。
13.解决了现有技术的分布式文件系统中无法实时对流数据更新插入的合并操作。
附图说明
14.图1为本发明流程示意图。
具体实施方式
15.本发明一种基于分布式文件系统流式数据实时更新插入合并处理方法包括以下步骤:步骤a:分区我们首先在分布式文件系统上对接入的流式数据以单个表为单位按时间间隔进行分区操作。一个分区为一个单独的文件夹,文件夹的名字以分区名来命名。分区名为当前文件夹的创建时间,格式为’年月日时分秒毫秒’,精确到毫秒,例如:20221109010101001。
16.在每个分区中我们根据用途不一样定义两种不同后缀的文件。一种是*.parquet格式和*.log格式。log文件用于存储该分区新增的数据,parquet文件用于存储该分区进行合并之后的数据。
17.步骤b:构建key我们采用流数据中主键字段的值作为该条数据的key值,key值为一条数据的全局唯一标识,用于后续判断该条数据是属于更新操作还是插入操作。
18.步骤c:构建索引随着数据的积累和时间的推移,我们将会产生大量的分区。所以我们构建了一个索引机制,来帮助我们判断当前数据属于更新操作还是插入操作,并且属于更新操作的情况下,快速的获取到该条数据所在的分区号。
19.我们将数据的key值和当前数据所在的分区号建立唯一映射关系,这种映射关系在数据第一次写入后就保持不变。把这种映射关系存放在第三方数据库中,利用第三方数据库完成索引的构建。
20.步骤d:更新插入当我们每条流式数据开始接入时,首先会拿当前这条数据的key值在第三方数据库中的索引表去寻找,如果这条key存在,则该条数据为更新操作。如果这条key不存在,则该条数据为插入操作。
21.根据数据的操作类型不同,采用不同的数据处理方式,如果是更新操作,我们根据
索引能够快速的定位到当前这条数据所在的分区,把该条数据直接追加到当前分区的log文件中。如果是插入操作,则直接把该条数据追加到当前最新分区的log文件中,同时在索引库中增加该条数据的索引。
22.步骤e:合并在每个分区文件夹中有两种不同的文件类型,我们根据触发机制来对分区文件夹中的文件进行合并。我们log文件来存储单次合并前产生的新增数据,用parquet文件来存储合并后的数据,每次合并后都将把log文件删除。在初始化时到第一次合并前,文件夹中并没有parquet文件,只可能会有log文件,只有在第一次合并之后才会有parquet文件。如果该文件夹中只有parquet文件,没有log文件,则证明从上一次合并到当前这次合并的过程中该分区都没有新增数据,所以当前次合并该分区不用合并。
23.合并的触发机制我们分为2种情况,主动合并和被动合并。当对表进行访问时对所有的分区进行合并操作,然后把合并后最新的parquet文件作为最新的数据来访问,这种合并称之为被动合并。如果设置每创建一个分区时就对之前的所有分区进行合并,这种合并称之为主动合并。主动合并和被动合并共同作用,完成流数据的合并。
技术特征:
1.一种基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:所述方法包括:步骤1、在分布式文件系统上对接入的流式数据以单个表为单位按时间间隔进行分区操作;步骤2、采用流数据中主键字段的值作为该条数据的key值;步骤3、将数据的key值和当前数据所在的分区号建立唯一映射关系,把这种映射关系存放在第三方数据库中,利用第三方数据库完成索引的构建;步骤4、当每条流式数据开始接入时,执行更新或插入操作;步骤5、根据触发机制来对分区文件夹中的文件进行合并。2.根据权利要求1所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:一个分区为一个单独的文件夹,文件夹的名字以分区名来命名;分区名为当前文件夹的创建时间,格式为’年月日时分秒毫秒’。3.根据权利要求1所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:key值为一条数据的全局唯一标识,用于判断该条数据是属于更新操作还是插入操作。4.根据权利要求1所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:执行更新或插入操作的判断方法为:首先拿当前这条数据的key值在第三方数据库中的索引表去寻找,如果这条key存在,则该条数据为更新操作;如果这条key不存在,则该条数据为插入操作。5.根据权利要求4所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:更新和插入操作的方法为:根据索引能够定位到当前这条数据所在的分区,将这该条数据直接追加到当前分区的log文件中;插入操作则是直接把这条数据追加到当前最新分区的log文件中,同时在索引库中增加该条数据的索引。6.根据权利要求1所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:文件进行合并的方法为:在每个分区文件夹中有两种不同的文件类型,根据触发机制来对分区文件夹中的文件进行合并;用log文件来存储单次合并前产生的新增数据,用parquet文件来存储合并后的数据,每次合并后都将把log文件删除。7.根据权利要求6所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:文件进行合并分位主动合并和被动合并;被动合并指当对表进行访问时对所有的分区进行合并操作,然后把合并后最新的parquet文件作为最新的数据来访问。8.根据权利要求7所述的基于分布式文件系统流式数据实时更新插入合并处理方法,其特征在于:主动合并指每创建一个分区时就对之前的所有分区进行合并。
技术总结
本发明公开了一种基于分布式文件系统流式数据实时更新插入合并处理方法,所述方法包括:步骤1、在分布式文件系统上对接入的流式数据以单个表为单位按时间间隔进行分区操作;步骤2、采用流数据中主键字段的值作为该条数据的key值;步骤3、将数据的key值和当前数据所在的分区号建立唯一映射关系,把这种映射关系存放在第三方数据库中,利用第三方数据库完成索引的构建;步骤4、当每条流式数据开始接入时,执行更新或插入操作;步骤5、根据触发机制来对分区文件夹中的文件进行合并;解决了现有技术的分布式文件系统中无法实时对流数据更新插入的合并操作。入的合并操作。入的合并操作。
技术研发人员:田钺 缪新萍 董若烟 李文科 孔庆波 李洵 孙收余 朱昌会 姚舜 王益彰
受保护的技术使用者:贵州电网有限责任公司
技术研发日:2022.11.30
技术公布日:2023/3/2
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1