计算机可读记录介质、信息处理设备和信息处理方法与流程
本文中所讨论的实施方式涉及信息处理技术。
背景技术:
1、随着人工智能(ai)技术的普及,对能够提供解释的机器学习模型的需求已经增加,这是因为在没有询问的情况下黑盒型机器学习模型的确定不能被接受的事实,并且因为希望给出人类可解释的确定的前提。因此,预先使用诸如规则列表、决策树或线性模型的白盒模型。然而,仅使用白盒型机器学习模型不能确保机器学习模型是人类可解释的或能够提供解释。
2、因此,近年来,已经实现了一种交互方法,通过该方法重复地执行机器学习模型的生成和对人的反馈,使得生成人可接受的精确的机器学习模型。在该交互方法中,例如,从机器学习模型中的特征中选择被认为是重要特征的特征;向用户询问所选择的特征是否真正重要;并且针对每个这样的特征重复询问直到用户满意。同时,机器学习模型中的特征也被称为解释变量或简称为变量。
3、随后,根据反馈,改变优化机器学习模型时使用的参数,并且因此更新机器学习模型。作为重复执行这样的操作的结果,生成了人可接受的精确的机器学习模型。
4、机器学习模型具有大量特征。因此,通过考虑用户在中途中断交互的可能性,期望用尽可能少的问题获得被回答为重要特征的最大可能数量的特征。
5、在这点上,一些方法是可用的,例如其中按照具有使用可用统计量例如相关性、相互信息内容和卡方值来计算的大的值的特征的顺序执行询问的方法;或者一种方法,其中测量关于机器学习模型的每个特征对预测分布的影响并且选择具有相对较大影响的特征用于询问目的。
6、[专利文献1]国际专利申请的日本国家公布第2016-536691号
7、[专利文献2]日本公开特许公报第2017-220238号
8、[专利文献3]美国未审查的专利申请公开第2018/0336271号
9、[专利文献4]美国未审查的专利申请公开第2019/0188585号
10、[专利文献5]日本公开特许公报第2019-169147号
11、然而,特定统计不一定与用户满意的现场知识(on-the spot knowledge)一致,并且有时需要询问大量问题直到用户满意。此外,依然在特征由机器学习模型选择的情况下,即使选择依赖于机器学习模型中的问题的特定索引,该索引也不一定与用户的现场知识一致。因此,最终,有时问题的数量变得很大。
12、因此,本发明的实施方式的一个方面的目的是提供能够以更有效的方式选择与用户的现场知识一致的特征以生成能够提供解释的机器学习模型的信息处理程序、信息处理设备和信息处理方法。
技术实现思路
1、根据实施方式的一方面,一种非暂态计算机可读记录介质,其中存储有信息处理程序,该信息处理程序使计算机执行处理,该处理包括:基于变量的优先级顺序和估计量,从多个变量中决定一个或更多个变量是关于重要性程度的问题的目标,所述变量的优先级顺序是基于指示所述多个变量的排名的多个模式确定的,所述估计量指示关于每个模式与预定条件匹配的可能性;以及基于关于所决定的变量的问题的回答结果来更新该估计量。
技术特征:
1.一种非暂态计算机可读记录介质,其中存储有信息处理程序,所述信息处理程序使计算机执行处理,所述处理包括:
2.根据权利要求1所述的非暂态计算机可读记录介质,其中,更新所述估计量包括:当所述回答结果指示所决定的变量是重要的时,进行更新以增加其中所决定的变量的优先级顺序等于或高于预定阈值的模式的估计量。
3.根据权利要求2所述的非暂态计算机可读记录介质,其中,更新所述估计量包括:当所述回答结果指示所决定的变量是不重要的时,进行更新以增加其中所决定的变量的优先级顺序不等于或高于所述预定阈值的模式的估计量。
4.根据权利要求1至3中任一项所述的非暂态计算机可读记录介质,其中,决定所述变量包括:基于基于指示根据表示所述变量的相关性、相互信息内容和卡方值中的至少一个的统计量所决定的排名的模式的优先级顺序以及所述估计量来决定所述变量。
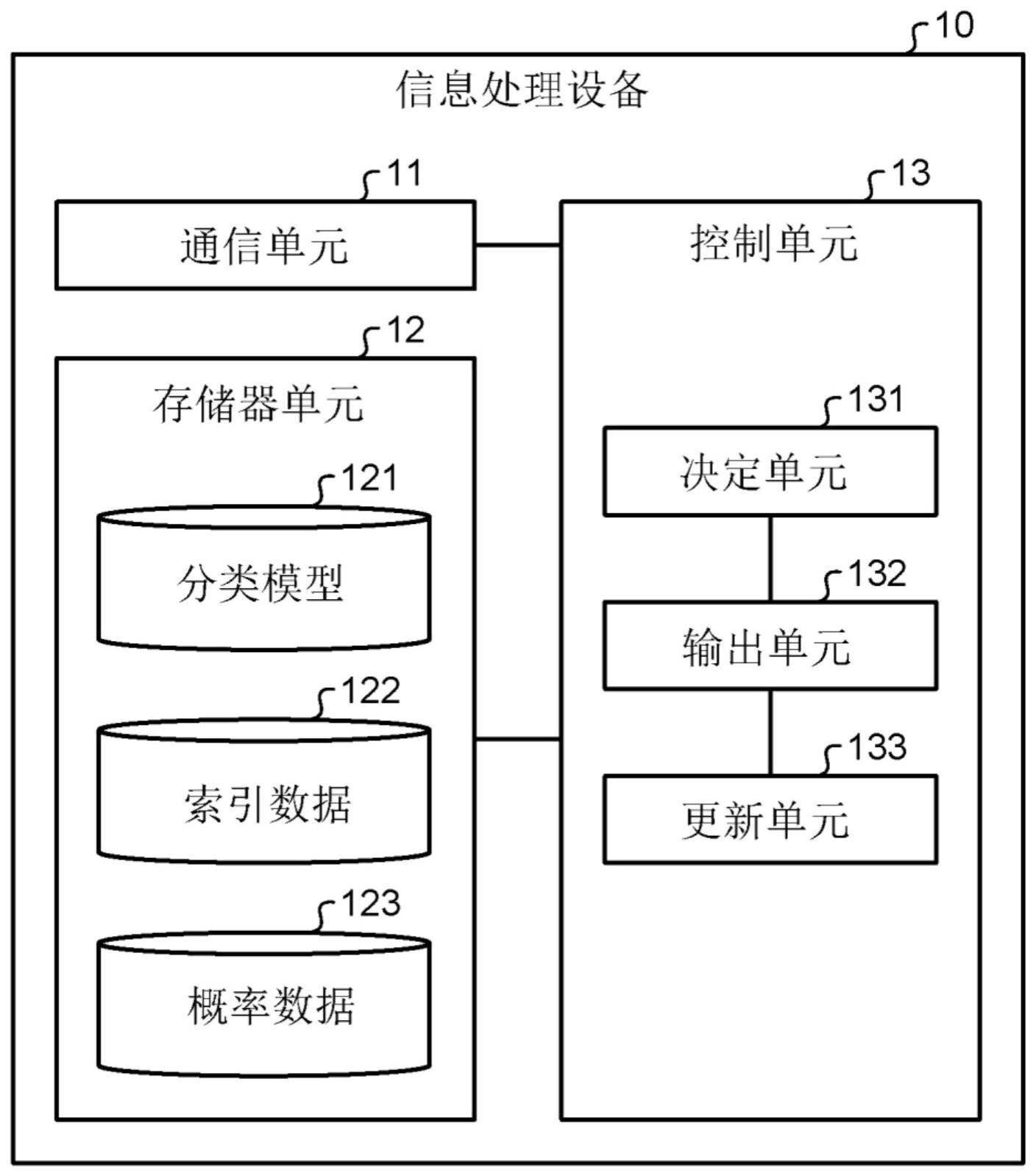
5.一种信息处理设备,其包括执行处理的控制单元,所述处理包括:
6.一种信息处理方法,其包括:
技术总结
一种非暂态计算机可读记录介质,其中存储有信息处理程序,该信息处理程序使计算机执行处理,该处理包括:基于变量的优先级顺序和估计量从多个变量中决定一个或更多个变量是关于重要性程度的问题的目标,所述变量的优先级顺序是基于指示所述多个变量的排名的多个模式确定的,所述估计量指示关于每个模式与预定条件匹配的可能性;以及基于关于所决定的变量的问题的回答结果来更新该估计量。
技术研发人员:铃木浩史,后藤启介,岩下洋哲,高木拓也,大堀耕太郎,原聪
受保护的技术使用者:富士通株式会社
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!