模型的训练方法、要素解析方法、装置、设备及可读介质与流程
本发明是关于人工智能,特别是关于一种医学文本要素解析模型的训练方法、医学文本要素解析方法、医学文本要素装置、电子设备及计算机可读介质。
背景技术:
1、随着医院信息化系统以及互联网医院在线问诊的发展和普及,积累了大量医生和患者自诉的医学文本数据。如何借助人工智能中的自然语言处理(natural languageprocessing,nlp)技术,对这些医学文本中所隐含的细粒度要素信息进行准确的解析和抽取成为一个亟待解决的问题。
2、因此,针对上述技术问题,有必要提供一种模型的训练方法、要素解析方法、装置、设备及可读介质。
技术实现思路
1、本发明的目的在于提供一种模型的训练方法、要素解析方法、装置、设备及可读介质,其能够准确的解析和抽取医学文本中的细粒度要素信息。
2、为实现上述目的,本发明提供的技术方案如下:
3、第一方面,本发明提供了一种医学文本要素解析模型的训练方法,其包括:
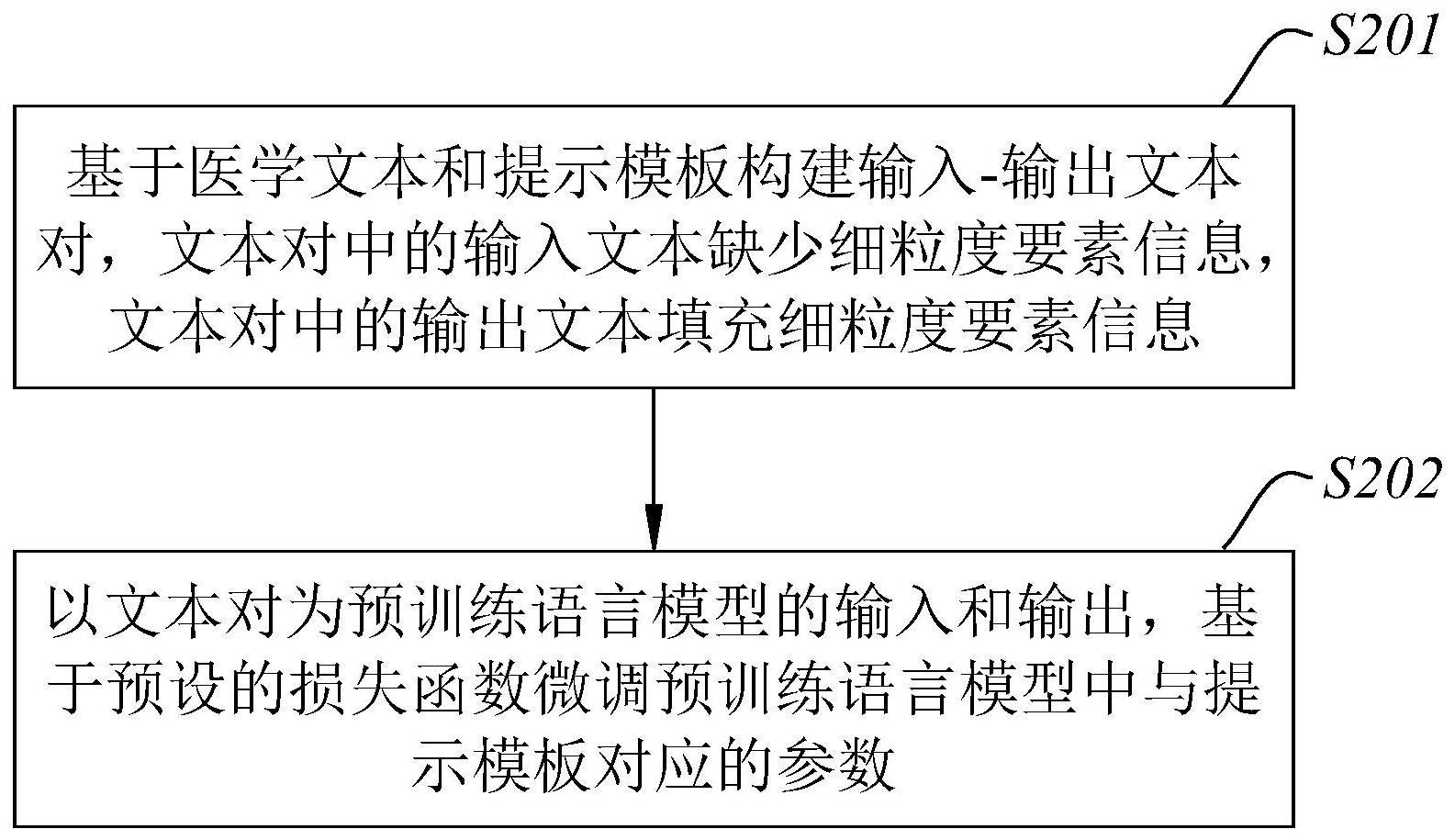
4、基于医学文本和提示模板构建输入-输出文本对,其中,所述提示模板包括细粒度分类标签,所述文本对中的输入文本缺少与所述细粒度分类标签对应的细粒度要素信息,所述文本对中的输出文本填充与所述细粒度分类标签对应的细粒度要素信息;
5、以所述文本对为预训练语言模型的输入和输出,基于预设的损失函数微调所述预训练语言模型中与所述提示模板对应的参数,所述预训练语言模型用于预测输入文本中缺失的细粒度要素信息。
6、在一个或多个实施方式中,所述训练方法具体包括:
7、构建包括细粒度分类标签的提示模板,其中,与所述细粒度分类标签对应的细粒度要素信息以掩码进行表示,所述细粒度分类标签包括疾病大类、疾病亚型、疾病分期、是否转移、转移部位、治疗方案中的至少一个;
8、将所述医学文本与所述提示模板进行拼接,得到所述输入-输出文本对中的输入文本。
9、在一个或多个实施方式中,所述训练方法具体包括:
10、提取所述医学文本中与所述细粒度分类标签对应的细粒度要素信息;
11、将所述提示模板中表示细粒度要素信息的所述掩码,替换为所述提取的细粒度要素信息;
12、将所述医学文本与所述替换后的提示模板进行拼接,得到所述输入-输出文本对中的输出文本。
13、在一个或多个实施方式中,所述训练方法还包括:
14、通过病历获取原始医学文本;
15、对所述原始医学文本进行清洗处理及纠错处理,得到所述医学文本。
16、在一个或多个实施方式中,所述清洗处理具体包括:
17、英文简写替换、阿拉伯数字到中文数字的转化、中文拼音替换、罗马数字规范化、去除重复字符、遗漏字符补齐。
18、在一个或多个实施方式中,所述纠错处理具体包括:
19、检测所述原始医学文本中的错误字词;
20、基于历史错误行为,召回所述错误字词的纠错候选字词;
21、选取所述纠错候选字词中正确概率最大的字词替换所述错误字词。
22、在一个或多个实施方式中,所述预训练语言模型包括基于transformer-encoder的bert模型、基于transformer-decoder的gpt模型和基于transformer-encoder-decoder的bart模型中的至少一种。
23、第二方面,本发明提供了一种医学文本要素解析方法,其包括:
24、对待解析医学文本进行预处理;
25、采用如前所述的训练方法训练得到的医学文本要素解析模型,对所述预处理后的待解析医学文本进行解析,得到解析结果;
26、对所述解析结果进行后处理,得到所述待解析医学文本的细粒度要素信息。
27、在一个或多个实施方式中,所述预处理包括清洗处理及纠错处理,所述后处理包括归一化处理及细粒度分类标签与细粒度要素信息之间的映射处理。
28、第三方面,本发明提供了一种医学文本要素解析装置,其包括:
29、预处理模块,用于对待解析医学文本进行预处理;
30、如前所述的训练方法训练得到的医学文本要素解析模型,用于对所述预处理模块预处理后的待解析医学文本进行解析,以得到解析结果;
31、后处理模块,用于对所述解析结果进行后处理,以得到所述待解析医学文本的细粒度要素信息输出结果。
32、第四方面,本发明提供了一种电子设备,包括存储器、处理器、以及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如前所述的方法。
33、第五方面,本发明提供了一种计算机可读介质,其特征在于,所述计算机可读介质中承载有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如前所述的方法。
34、与现有技术相比,本发明提供的医学文本要素解析模型的训练方法,基于医学文本和提示模板构建由缺失细粒度要素信息的输入文本与填充细粒度要素信息的输出文本,组成的输入-输出文本对,并利用该输入-输出文本对对预训练语言模型的参数进行提示性微调,从而可得到能够解析生成医学文本中的细粒度要素信息的模型,且得到的模型能够准确的解析和抽取医学文本中的细粒度要素信息。
技术特征:
1.一种医学文本要素解析模型的训练方法,其特征在于,包括:
2.如权利要求1所述的医学文本要素解析模型的训练方法,其特征在于,所述训练方法具体包括:
3.如权利要求2所述的医学文本要素解析模型的训练方法,其特征在于,所述训练方法具体包括:
4.如权利要求1所述的医学文本要素解析模型的训练方法,其特征在于,所述训练方法还包括:
5.如权利要求4所述的医学文本要素解析模型的训练方法,其特征在于,所述清洗处理具体包括:
6.如权利要求4所述的医学文本要素解析模型的训练方法,其特征在于,所述纠错处理具体包括:
7.如权利要求1所述的医学文本要素解析模型的训练方法,其特征在于,所述预训练语言模型包括基于transformer-encoder的bert模型、基于transformer-decoder的gpt模型和基于transformer-encoder-decoder的bart模型中的至少一种。
8.一种医学文本要素解析方法,其特征在于,包括:
9.如权利要求8所述的医学文本要素解析方法,其特征在于,所述预处理包括清洗处理及纠错处理,所述后处理包括归一化处理及细粒度分类标签与细粒度要素信息之间的映射处理。
10.一种医学文本要素解析装置,其特征在于,包括:
11.一种电子设备,包括存储器、处理器、以及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1~9中任一项所述的方法。
12.一种计算机可读介质,其特征在于,所述计算机可读介质中承载有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如权利要求1~9中任一项所述的方法。
技术总结
本发明公开了一种模型的训练方法、要素解析方法、装置、设备及可读介质;该模型的训练方法包括:基于医学文本和提示模板构建输入‑输出文本对,其中,提示模板包括细粒度分类标签,文本对中的输入文本缺少与细粒度分类标签对应的细粒度要素信息,文本对中的输出文本填充与细粒度分类标签对应的细粒度要素信息;以文本对为预训练语言模型的输入和输出,基于预设的损失函数微调预训练语言模型中与提示模板对应的参数。本发明提供的医学文本要素解析模型的训练方法,可得到能够解析生成医学文本中的细粒度要素信息的模型,且得到的模型能够准确的解析和抽取医学文本中的细粒度要素信息。
技术研发人员:王永明,赵周剑,司婧,王育清
受保护的技术使用者:浙江太美医疗科技股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!