一种票据文本识别方法、装置、计算机设备及存储介质与流程
本申请涉及人工智能,尤其涉及一种票据文本识别方法、装置、计算机设备及存储介质。
背景技术:
1、医疗账单是医疗保险报销必须提供的材料,医疗账单票面包含就诊人姓名、发票号、合计金额、费用项信息、统筹基金支付、就诊日期等关键字段。当前全国各地存在多种版式的医疗账单,这些关键字段所在位置及形式并不统一。即便当前国家推行电子票据,仍有相当高比例医院未接入电子发票,且各医院对电子发票“其他信息”区域的打印信息不一致。这些情况导致医保报销时录入人员需基于对业务的理解关注不同版式发票的不同信息。
2、医疗账单场景中的结构化识别通常有以下几种解决方案:利用ocr识别模型对医疗发票进行文本识别,基于nlp技术进行全文抽取;基于固定字段切片或固定区域,抽取所需关键字段信息;基于多个检测及分割模型,分区块进行识别与匹配;自定义大量解析模板,不同类型发票分流至对应解析流程。
3、然而,在实际应用过程中,经常出现如下问题:纸张较薄易折叠弯曲,导致账单同一费用项的多个信息不在同一水平线上,名称和金额等信息无法一一对应;部分字段出现换行,只能抽取到第一行的信息。
4、现有技术对于上述医疗票据的易折叠、部分字段换行打印等特点未做针对性优化,导致识别结果经常出现错误,使得需要人工介入的环节较多,拉长周期,同时也提高了理赔报销信息化成本。
技术实现思路
1、本申请实施例的目的在于提出一种票据文本识别方法、装置、计算机设备及存储介质,以解决现有技术中在票据存在折叠、部分字段换行等情况下文本识别容易出现错误的问题。
2、为了解决上述技术问题,本申请实施例提供一种票据文本识别方法、装置、计算机设备及存储介质,采用了如下所述的技术方案:
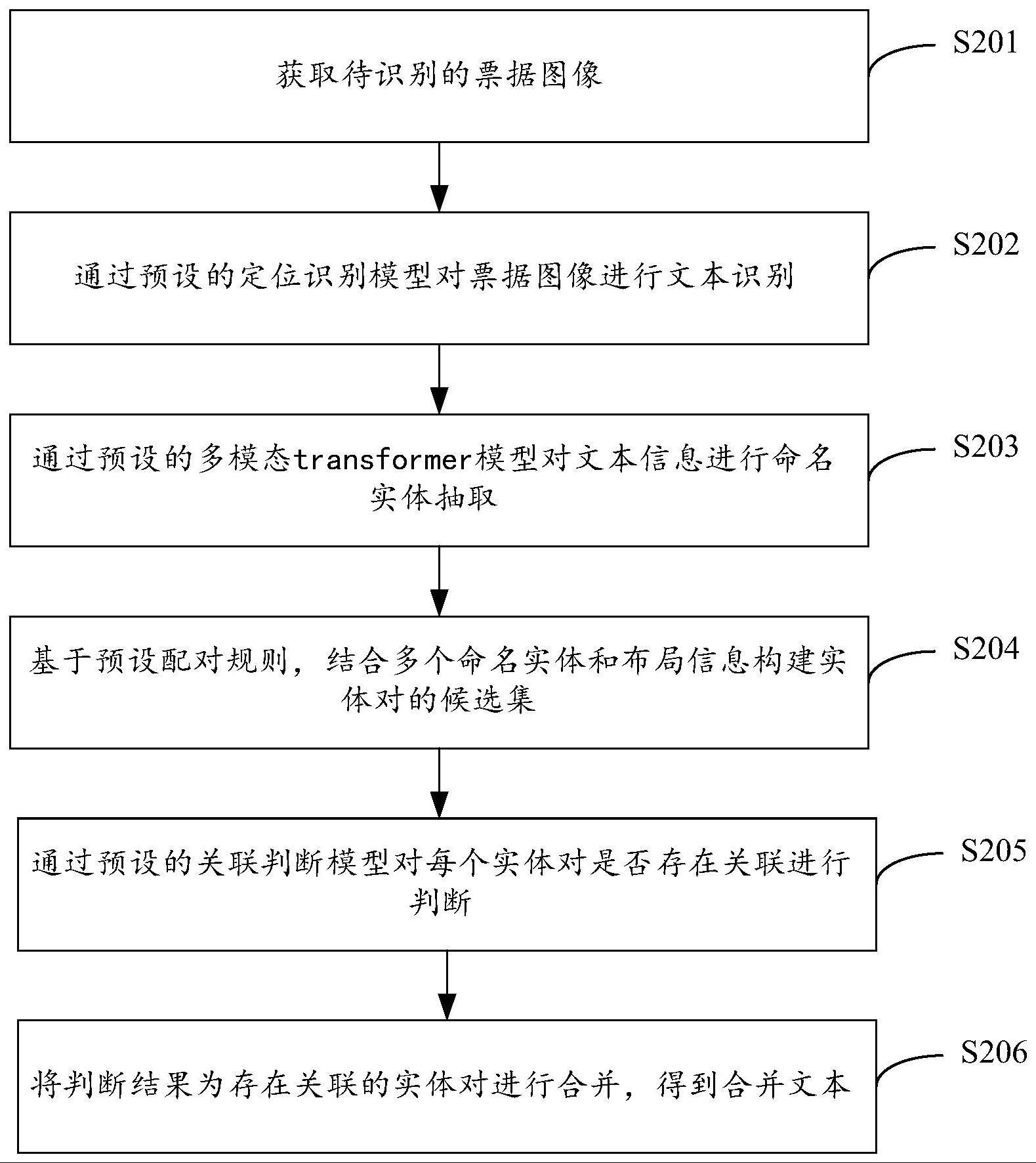
3、一种票据文本识别方法,包括下述步骤:
4、获取待识别的票据图像;
5、通过预设的识别定位模型对所述票据图像进行文本识别,得到文本信息和对应的布局信息;
6、通过预设的多模态transformer模型对所述文本信息进行命名实体抽取,得到对应的多个命名实体;
7、基于预设配对规则,结合所述多个命名实体和所述布局信息构建实体对的候选集;
8、通过预设的关联判断模型对每个所述实体对是否存在关联进行判断;
9、将判断结果为存在关联的实体对进行合并,得到合并文本。
10、进一步的,在所述通过预设的识别定位模型对所述票据图像进行文本识别的步骤之前,还包括:
11、对所述票据图像是否存在偏转进行判断;
12、若存在偏转,则对所述票据图像进行旋转操作,得到正向的所述票据图像。
13、进一步的,在所述通过预设的识别定位模型对所述票据图像进行文本识别的步骤之前,还包括:
14、将所述票据图像输入预设的语义分割模型,得到对应的掩码图;
15、提取所述掩码图的连通域的边界,设定所述边界的最小外接矩形区域;
16、对所述票据图像的所述矩形区域外的区域进行白色填充处理。
17、进一步的,所述通过预设的多模态transformer模型对所述文本信息进行命名实体抽取的步骤之前,还包括:
18、通过查询预设的同义词库,判断所述文本信息是否存在同义词;
19、在判断存在所述同义词时,对所述文本信息进行所述同义词替换。
20、进一步的,所述通过预设的多模态transformer模型对所述文本信息进行命名实体抽取的步骤,具体包括:
21、将所述票据图像、所述文本信息和所述布局信息输入所述预设的多模态transformer模型进行所述命名实体抽取,得到所述多个命名实体。
22、进一步的,在所述将判断结果为存在关联的实体对进行合并的步骤之后,还包括:
23、基于预设判断规则,生成所述合并文本可信度的目标判断结果。
24、进一步的,在所述将判断结果为存在关联的实体对进行合并,得到合并文本的步骤之后,还包括:
25、将所述票据图像输入到所述识别定位模型进行文本识别,得到文本置信率;
26、将所述文本信息输入到所述多模态transformer模型进行命名实体抽取,得到命名置信率;
27、将所述实体对输入到所述关联判断模型进行是否存在关联性判断,得到判断置信率;
28、对所述文本置信率、所述命名置信率以及所述判断置信率中的至少两个进行平均或者加权平均,生成所述合并文本的可信度目标判断结果;
29、在所述目标判断结果超过预设阀值时,直接输出所述合并文本。
30、为了解决上述技术问题,本申请实施例还提供一种票据文本识别装置,采用了如下所述的技术方案:
31、获取模块,用于获取待识别的票据图像;
32、识别模块,用于通过预设的识别定位模型对所述票据图像进行文本识别,得到文本信息和对应的布局信息;
33、抽取模块,用于通过预设的多模态transformer模型对所述文本信息进行命名实体抽取,得到对应的多个命名实体;
34、构建模块,用于基于预设配对规则,结合所述多个命名实体和所述布局信息构建实体对的候选集;
35、判断模块,用于通过预设的关联判断模型对每个所述实体对是否存在关联进行判断;
36、合并模块,用于将判断结果为存在关联的实体对进行合并,得到合并文本。
37、为了解决上述技术问题,本申请实施例还提供一种计算机设备,采用了如下所述的技术方案:
38、一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述处理器执行所述计算机可读指令时实现如上所述的票据文本识别方法的步骤。
39、为了解决上述技术问题,本申请实施例还提供一种计算机可读存储介质,采用了如下所述的技术方案:
40、一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机可读指令,所述计算机可读指令被处理器执行时实现如上所述的票据文本识别方法的步骤。
41、与现有技术相比,本申请实施例主要有以下有益效果:本申请通过对票据图像进行文本识别,再对识别得到的文本信息进行实体抽取,结合抽取得到的多个命名实体和布局信息构建实体对的候选集,通过判断各个实体对是否存在关联,对存在关联的实体对进行合并,从而可以有效将关联性高的本文信息进行合并,提高了票据在折叠、部分字段换行等情况下文本识别的精度。
技术特征:
1.一种票据文本识别方法,其特征在于,包括下述步骤:
2.根据权利要求1所述的票据文本识别方法,其特征在于,在所述通过预设的识别定位模型对所述票据图像进行文本识别的步骤之前,还包括:
3.根据权利要求1或2所述的票据文本识别方法,其特征在于,在所述通过预设的识别定位模型对所述票据图像进行文本识别的步骤之前,还包括:
4.根据权利要求1或2所述的票据文本识别方法,其特征在于,所述通过预设的多模态transformer模型对所述文本信息进行命名实体抽取的步骤之前,还包括:
5.根据权利要求1或2所述的票据文本识别方法,其特征在于,所述通过预设的多模态transformer模型对所述文本信息进行命名实体抽取的步骤,具体包括:
6.根据权利要求1或2所述的票据文本识别方法,其特征在于,在所述将判断结果为存在关联的实体对进行合并,得到合并文本的步骤之后,还包括:
7.根据权利要求1或2所述的票据文本识别方法,其特征在于,在所述将判断结果为存在关联的实体对进行合并的步骤之后,还包括:
8.一种票据识别装置,其特征在于,包括:
9.一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述处理器执行所述计算机可读指令时实现如权利要求1至7中任一项所述的票据文本识别方法的步骤。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机可读指令,所述计算机可读指令被处理器执行时实现如权利要求1至7中任一项所述的票据文本识别方法的步骤。
技术总结
本申请实施例属于人工智能中的票据文本识别技术领域,涉及一种票据文本识别方法,包括获取待识别的票据图像;通过预设的识别定位模型对票据图像进行文本识别;通过预设的多模态transformer模型对文本信息进行命名实体抽取;基于预设配对规则,结合多个命名实体和布局信息构建实体对的候选集;通过预设的关联判断模型对每个实体对是否存在关联进行判断;将判断结果为存在关联的实体对进行合并。本申请还提供一种票据识别装置、计算机设备及存储介质。此外,本申请还涉及区块链技术,用户的票据图像、文本信息等可存储于区块链中<subgt;。</subgt;本申请提高了票据在折叠、部分字段换行等情况下文本识别的精度。
技术研发人员:郭喜亚
受保护的技术使用者:平安健康保险股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!