一种基于注意力区域的DCNN加速器
本发明涉及目标检测领域,具体涉及一种基于注意力区域的dcnn加速器。
背景技术:
1、在以往的one stage目标检测中,没有针对视频流优化检测方法的硬件加速器。然而在视频目标检测中,不同于图片检测,相邻几帧具有很强的内容关联性。这意味着可以预知下一帧目标出现的位置并判断出视野中哪些区域是没有价值的。此外,以往的工作中,可重配置计算精度的加速器往往是先对dcnn模型离线进行精度需求量化,并且量化的粒度仅仅是层级粒度layer level。这种方法有一定的缺点:第一,layer level的精度量化无法区别同一层中不同卷积核的重要程度,显得比较粗糙;第二,离线的精度量化无法在模型运行中动态地对各层特征图feature map的不同区域(卷积窗口集,conv windows set)进行量化。这些缺点使得这些加速器面临一些局限性:第一,加速器可能要做更多没有必要的高精度计算,增加了计算资源开销。第二,无法针对不同的视频流进行动态的计算精度调整,缺乏灵活性。
2、在硬件方面,gpu的并行能力主要体现在利用大量的流处理器,进行多个图片并行处理,因此gpu适合批量图片的训练。但在视频目标实时识别任务中,视频帧是顺序到来的,对单张图片的计算时间非常敏感,加速器必须按顺序处理视频帧。特别是在帧率要求极高的场景下(60fps、120fps),比如自动驾驶中对危险目标的提前识别预测对于驾驶安全至关重要,毫秒级的提前识别预测可以缩短几米乃至数十米的刹车距离。很多论文的背景介绍中都提出了gpu在这方面的缺陷,即无法发挥其批量图片的并行处理能力。因此以往的设计中,往往通过提高单个核心的处理性能来提高视频目标实时识别能力,例如设计多个pile提升卷积核级并行。此外,对地面目标识别的无人机往往拥有高分辨率的航拍视频,这种应用对实时处理性能提出了更高的要求。
技术实现思路
1、针对上述背景技术中存在的问题,提出一种基于注意力区域的dcnn加速器,从两大方向对计算量进行修剪:一是减少参与计算的图像区域,减少可能没有目标的区域的计算量;二是细粒度地进行计算精度量化,减少不必要的高精度计算。其次,在硬件上将gpu的多张并行处理的优势带入加速器。综上,结合多个改进方式来实现高效率的视频流目标检测和动态精度重配置计算。
2、一种基于注意力区域的dcnn加速器,基于多核心架构,每个核心处理一个子图像;当子图像较大时,将其分解为两个部分交给两个核心进行处理;核心之间进行数据的通信;
3、加速器进行目标识别时,核心的并行方式首先为子图像并行,在子图像重新组合后,完整特征图被广播到所有node中,不同的node获得不同的卷积核,node之间转变为卷积核级并行;
4、对于待目标识别的视频流,每隔固定时间对其中完整的帧图像进行检测识别,加速器根据检测结果更新注意力区域;在其他时间,加速器只检测注意力区域;其中注意力区域包括比被识别的目标框长与宽稍大的区域和图像的边缘区域;
5、加速器中,分别对于子图像的weight数据和activation数据进行细粒度精度量化的处理,包括对于weight数据的基于零率占比标记计算精度及排序输出的卷积核粒度分析、以及对于activation数据的基于零率阈值标记计算精度及排序输出的卷积窗口集粒度量化。
6、本发明达到的有益效果为:
7、1)提出了注意力机制。大部分时候加速器只检测注意力区域的图像,通过对注意力区域周期性的更新,从而既可获得较高的识别准确率,又大大降低了需要的计算量。在硬件上,芯片中设计了多个计算核心,加速器为这些核心动态分配子图片以应对「计算不同大小的注意力区域」和「计算整张图像」两种计算场景。
8、2)对dcnn模型进行离线的卷积核级的细粒度精度量化,提出卷积核/输出通道重排列的方法来支持加速器对不同精度卷积核的计算;
9、3)在线对featuremap的各个分区即卷积窗口集进行实时精度量化,提出了一种在线零率检测器,可以实时对输出特征图进行零率检测。并设计了适应于这种方法的pe与pearray。
10、4)设计的8个pearray与weightregfiles、rightregfiles和bottomregfiles组成了具有“二维数据滑动”功能的os数据流体系,可以将数据最大程度保留在pe内部从而在时间和空间上复用weight和activation数据,从而减少数据传输带宽和重复数据传输造成的额外功耗;同时可以很好地支持在线卷积窗口集实时零率检测。
技术特征:
1.一种基于注意力区域的dcnn加速器,其特征在于:
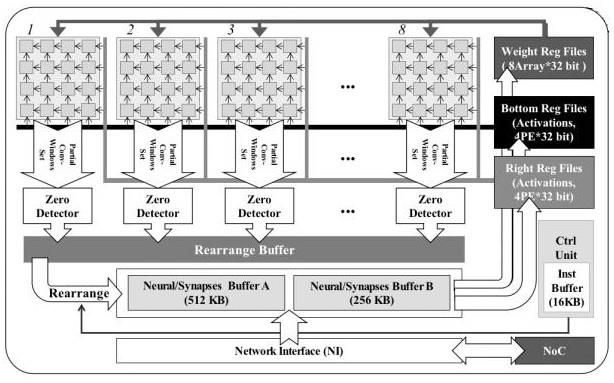
2.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:加速器由多个核心node和一个中心核心centralnode组成;node之间通过片上网络noc相互连接与通信;
3.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:当加速器进行子图像并行时,利用512kb的synapses/neuralbuffer用于存储权重weight数据,256kb的synapses/neuralbuffer用于存储激活activation数据;当加速器由子图像并行转变为卷积核级并行时,512kb的synapses/neuralbuffer用于存储activation数据,256kb的synapses/neuralbuffer用于存储weight数据。
4.根据权利要求2所述的一种基于注意力区域的dcnn加速器,其特征在于:pearrays从regfiles读取参与计算的数据;每个pe array的输出数据经过一个zerodetector,zerodetector用于检测输出数据的零率;经过zerodetector的数据存入rearrangebuffer,成为下一层的输入特征图并存入synapses/neuralbuffer;network interface用于将node接入片上网络noc。
5.根据权利要求2所述的一种基于注意力区域的dcnn加速器,其特征在于:pearray中的数据从右侧相邻的pe流向左侧相邻的pe,或从下方相邻的pe流向上方相邻的pe。
6.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:weightregfiles中的8个寄存器分别给8个pearray提供权重weight数据,权重数据在每个pearray中广播给64个pe;rightregfiles与各个pearray最右侧的pe相连;bottomregfiles与各个pearray最底部的pe相连,即每张pearray同时获得相同的activation数据。
7.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:检测注意力区域时,当目标框与图像的边缘区域重叠的时候,目标框延伸到图像边沿作为注意力区域,此时图像边缘区域会被切分;当一个目标框与另外的目标框重叠时,将这些目标框合并为一个大的矩形目标框,大的矩形目标框包含原来的所有目标。
8.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:检测注意力区域时,加速器为每个node分配单个注意力区域;如果注意力区域较大,并且有空闲的node,那么取空闲node数量相等数量的注意力区域进行拆分;拆分后的两部分图像交付给两个node处理,两个node之间在每一层计算前传输切割面的边缘数据;如果目标数量超过node数量,依次把最小的两个注意力区域分配给一个node。
9.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:细粒度精度量化处理中,weight数据进行卷积核粒度的分析,在线下对卷积核逐一进行零率检测;先统计dcnn加速器中所有weight数据绝对值的分布情况,并记录下绝对值在[0,0.0125]内的数据的占比g;当某个卷积核的零率高于g时,则标记其计算精度为4bit;当某个卷积核的零率低于g时,则标记其计算精度为8bit;
10.根据权利要求1所述的一种基于注意力区域的dcnn加速器,其特征在于:细粒度精度量化处理中,activation数据进行卷积窗口集粒度的量化;每个node拥有8个pearray和8个zero detector,8个zero detctor分别检测相应的pearray的输出数据的零率,8个zerodetector的结果被综合后进行判断下一层卷积窗口集的零率;
技术总结
一种基于注意力区域的DCNN加速器,通过对注意力区域周期性的更新,识别准确率高,计算量低;在硬件上设计多个计算核心,并动态分配子图片以应对不同的计算场景;进行卷积核级的细粒度精度量化,提出卷积核/输出通道重排列的方法支持不同精度卷积核的计算;对卷积窗口集进行实时精度量化,可以实时对输出特征图进行零率检测,并设计适应性的PE与PE Array;设计具有“二维数据滑动”功能的OS数据流体系,可以将数据最大程度保留在PE内部从而在时间和空间上复用Weight和Activation数据,从而减少数据传输带宽和重复数据传输造成的额外功耗,同时可以很好地支持在线卷积窗口集实时零率检测。
技术研发人员:陈小柏,胡秋润
受保护的技术使用者:南京邮电大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!