可解释的文本语义匹配方法、装置、电子设备及存储介质与流程
本申请涉及人工智能,具体涉及一种可解释的文本语义匹配方法、装置、电子设备及存储介质。
背景技术:
1、目前的语义匹配方法,一般上是分为三种实现范式:第一种是基于字符串的方法,只计算字符串的匹配程度,不考虑语义信息,通过计算句子之间的海明距离来判断文本是否相似;第二种是基于语料库的方法,将输入的句子进行分词,然后计算句子中每个词与其他句子的相似度,最后进行加权求和;第三种是基于深度学习的方法,可以将语义匹配问题直接视为一个二分类问题,类别可以分为“匹配”和“不匹配”,然后在预训练模型下进行微调,最后得到结果。
2、但是对长文本(即文本的字符数大于阈值)的语义匹配而言,基于现有的语义匹配方法,如深度学习算法,虽然最终的匹配结果可以判断两个长文本相似或者不相似,但是不能解释为什么这两个长文本相似或者不相似,使得用户对匹配结果不理解。因此,在长文本的语义匹配上如何增加用户对匹配结果的理解,进而提升用户的体验感是亟待解决的问题。
技术实现思路
1、本申请实施例提供了一种可解释的文本语义匹配方法、装置、电子设备及存储介质,通过确定出解释信息来解释待识别文本和目标文本相似的原因,增加了用户对匹配结果(即待识别文本语义匹配到最相似的文本是目标文本)的理解,进而提升了用户的体验感。
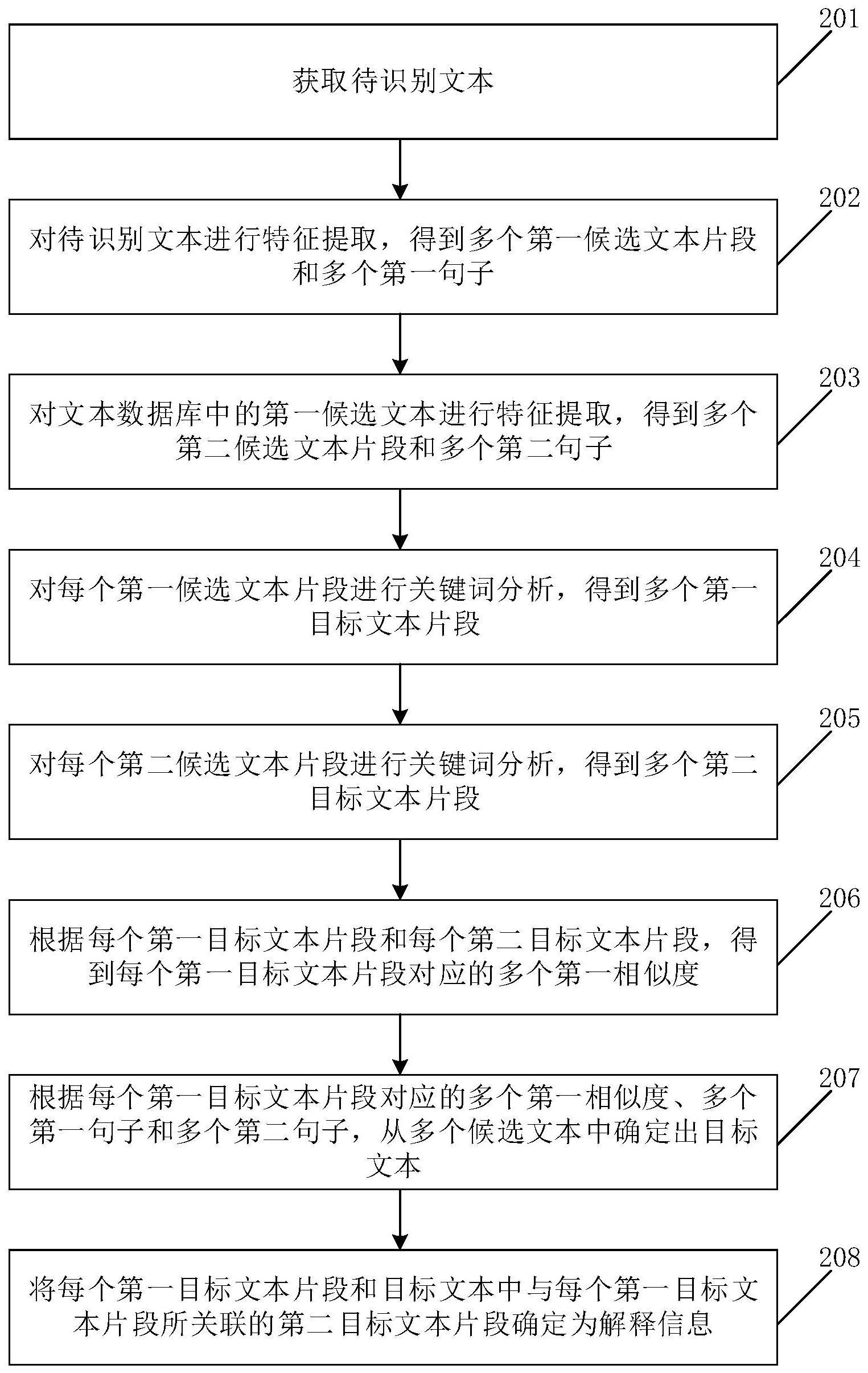
2、第一方面,本申请实施例提供一种可解释的文本语义匹配方法,该方法包括:
3、获取待识别文本,其中,待识别文本的字符数大于阈值;
4、对待识别文本进行特征提取,得到多个第一候选文本片段和多个第一句子;
5、对文本数据库中的第一候选文本进行特征提取,得到多个第二候选文本片段和多个第二句子,其中,第一候选文本为文本数据库中多个候选文本中的任意一个;
6、对每个第一候选文本片段进行关键词分析,得到多个第一目标文本片段;
7、对每个第二候选文本片段进行关键词分析,得到多个第二目标文本片段;
8、根据每个第一目标文本片段和每个第二目标文本片段,得到每个第一目标文本片段对应的多个第一相似度;
9、根据每个第一目标文本片段对应的多个第一相似度、多个第一句子和多个第二句子,从多个候选文本中确定出目标文本;
10、将每个第一目标文本片段和目标文本中与每个第一目标文本片段所关联的第二目标文本片段确定为解释信息,其中,与每个第一目标文本片段所关联的第二目标文本片段为该第一目标文本片段对应的多个第一相似度中最大的第一相似度所对应的第二目标文本片段,解释信息用于解释待识别文本和目标文本相似的原因。
11、第二方面,本申请实施例提供一种可解释的文本语义匹配装置,该装置包括:获取单元和处理单元;
12、获取单元,用于获取待识别文本,其中,待识别文本的字符数大于阈值;
13、处理单元,用于对待识别文本进行特征提取,得到多个第一候选文本片段和多个第一句子;
14、处理单元,用于对文本数据库中的第一候选文本进行特征提取,得到多个第二候选文本片段和多个第二句子,其中,第一候选文本为文本数据库中多个候选文本中的任意一个;
15、处理单元,用于对每个第一候选文本片段进行关键词分析,得到多个第一目标文本片段;
16、处理单元,用于对每个第二候选文本片段进行关键词分析,得到多个第二目标文本片段;
17、处理单元,用于根据每个第一目标文本片段和每个第二目标文本片段,得到每个第一目标文本片段对应的多个第一相似度;
18、处理单元,用于根据每个第一目标文本片段对应的多个第一相似度、多个第一句子和多个第二句子,从多个候选文本中确定出目标文本;
19、处理单元,用于将每个第一目标文本片段和目标文本中与每个第一目标文本片段所关联的第二目标文本片段确定为解释信息,其中,与每个第一目标文本片段所关联的第二目标文本片段为该第一目标文本片段对应的多个第一相似度中最大的第一相似度所对应的第二目标文本片段,解释信息用于解释待识别文本和目标文本相似的原因。
20、第三方面,本申请实施例提供一种电子设备,包括:处理器和存储器,处理器与存储器相连,存储器用于存储计算机程序,处理器用于执行存储器中存储的计算机程序,以使得电子设备执行如第一方面的方法。
21、第四方面,本申请实施例提供一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序使得计算机执行如第一方面的方法。
22、第五方面,本申请实施例提供一种计算机程序产品,计算机程序产品包括存储了计算机程序的非瞬时性计算机可读存储介质,计算机可操作来使计算机执行如第一方面的方法。
23、实施本申请实施例,具有如下有益效果:通过获取待识别文本,其中,待识别文本的字符数大于阈值;然后对待识别文本进行特征提取,得到多个第一候选文本片段和多个第一句子,以及对文本数据库中的第一候选文本进行特征提取,得到多个第二候选文本片段和多个第二句子,其中,第一候选文本为文本数据库中多个候选文本中的任意一个;然后对每个第一候选文本片段进行关键词分析,得到多个第一目标文本片段,以及对每个第二候选文本片段进行关键词分析,得到多个第二目标文本片段;然后根据每个第一目标文本片段和每个第二目标文本片段,得到每个第一目标文本片段对应的多个第一相似度;然后根据每个第一目标文本片段对应的多个第一相似度、多个第一句子和多个第二句子,从多个候选文本中确定出目标文本,提升了匹配的精度;并将每个第一目标文本片段和目标文本中与每个第一目标文本片段所关联的第二目标文本片段确定为解释信息,其中,与每个第一目标文本片段所关联的第二目标文本片段为该第一目标文本片段对应的多个第一相似度中最大的第一相似度所对应的第二目标文本片段,解释信息用于解释待识别文本和目标文本相似的原因,使得用户理解为何待识别文本和目标文本相似,进而提升了用户的体验感。
技术特征:
1.一种可解释的文本语义匹配方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述根据每个第一目标文本片段对应的多个第一相似度、所述多个第一句子和所述多个第二句子,从所述多个候选文本中确定出目标文本,包括:
3.根据权利要求1或2所述的方法,其特征在于,所述可解释的文本语义匹配是通过多任务模型执行的,所述多任务模型包括特征提取网络、第一子任务网络、第二子任务网络和第三子任务网络,所述方法还包括:
4.根据权利要求3所述的方法,其特征在于,所述基于所述多个第三候选文本片段、所述多个第四候选文本片段、所述多个第三句子和所述多个第四句子,得到与所述第一子任务网络对应的第一损失、与所述第二子任务网络对应的第二损失以及与所述第三子任务网络对应的第三损失,包括:
5.根据权利要求4所述的方法,其特征在于,所述基于每个第一候选文本片段的第一预测值和每个第二候选文本片段的第二预测值,得到所述第一损失,包括:
6.根据权利要求4或5所述的方法,其特征在于,所述根据每个第一候选文本片段的第一预测值、每个第二候选文本片段的第二预测值、所述多个第三句子和所述多个第四句子,得到所述第二损失和所述第三损失,包括:
7.根据权利要求3-6任一项所述的方法,其特征在于,所述基于所述第一损失、所述第二损失以及所述第三损失,得到目标损失,包括:
8.一种可解释的文本语义匹配装置,其特征在于,所述装置包括:获取单元和处理单元;
9.一种电子设备,其特征在于,包括:处理器和存储器,所述处理器与所述存储器相连,所述存储器用于存储计算机程序,所述处理器用于执行所述存储器中存储的计算机程序,以使得所述电子设备执行如权利要求1-7中任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行以实现如权利要求1-7中任一项所述的方法。
技术总结
本申请实施例公开了一种可解释的文本语义匹配方法、装置、电子设备及存储介质。该方法包括:获取待识别文本;对待识别文本和第一候选文本进行特征提取,得到多个第一候选文本片段和多个第一句子、多个第二候选文本片段和多个第二句子;对每个第一候选文本片段和每个第二候选文本片段进行关键词分析得到多个第一目标文本片段和多个第二目标文本片段;根据每个第一目标文本片段和每个第二目标文本片段得到每个第一目标文本片段对应的多个第一相似度;根据多个第一相似度、多个第一句子和多个第二句子,确定目标文本;将每个第一目标文本片段和目标文本中与每个第一目标文本片段所关联的第二目标文本片段确定为解释信息。
技术研发人员:周倚文,张云云,何剑涛,魏志辉,张文锋,王福海
受保护的技术使用者:招联消费金融有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!