基于知识蒸馏的轻量级神经机器翻译系统构建方法与流程
本发明涉及一种压缩神经机器翻译模型的技术,具体为基于知识蒸馏的轻量级神经机器翻译系统构建方法。
背景技术:
1、现实中,为了获得较高的翻译质量,开发者往往需要使用参数量上亿级别的大型神经机器翻译模型,甚至还会利用集成学习(ensemble)等手段同时运行多个大型模型进行翻译。在云计算高速发展的今天,这些大型模型的训练、运行可以在高性能gpu服务器上完成,但是对于一些需要离线使用机器翻译的用户来说,将大型神经机器翻译系统部署在用户终端等推断设备上是非常困难的,原因在于这些设备几乎不具备高性能gpu服务器的并行计算能力,最终导致神经机器翻译系统在用户终端推断设备上运行缓慢甚至无法运行。由此引出了神经机器翻译的推断设备受限问题。
2、对于神经机器翻译的推断设备受限问题,最直接也最通用的解决方案是使用小模型部署到推断设备上。由于部署的需求,因此需要小模型具有体积小、速度快、翻译质量较高、鲁棒性较好的特点。小模型的获取通常使用一些模型压缩技术来获得比从头训练小模型更强的翻译性能,包括模型剪枝、模型量化、知识蒸馏、参数共享等。
技术实现思路
1、针对现有技术中面对推断设备受限时神经机器翻译解码效率低下等不足,本发明要解决的技术问题是提供一种压缩神经机器翻译模型的基于知识蒸馏的轻量级神经机器翻译系统构建方法。
2、为解决上述技术问题,本发明采用的技术方案是:
3、本发明提供一种基于知识蒸馏的轻量级神经机器翻译系统构建方法,包括以下步骤:
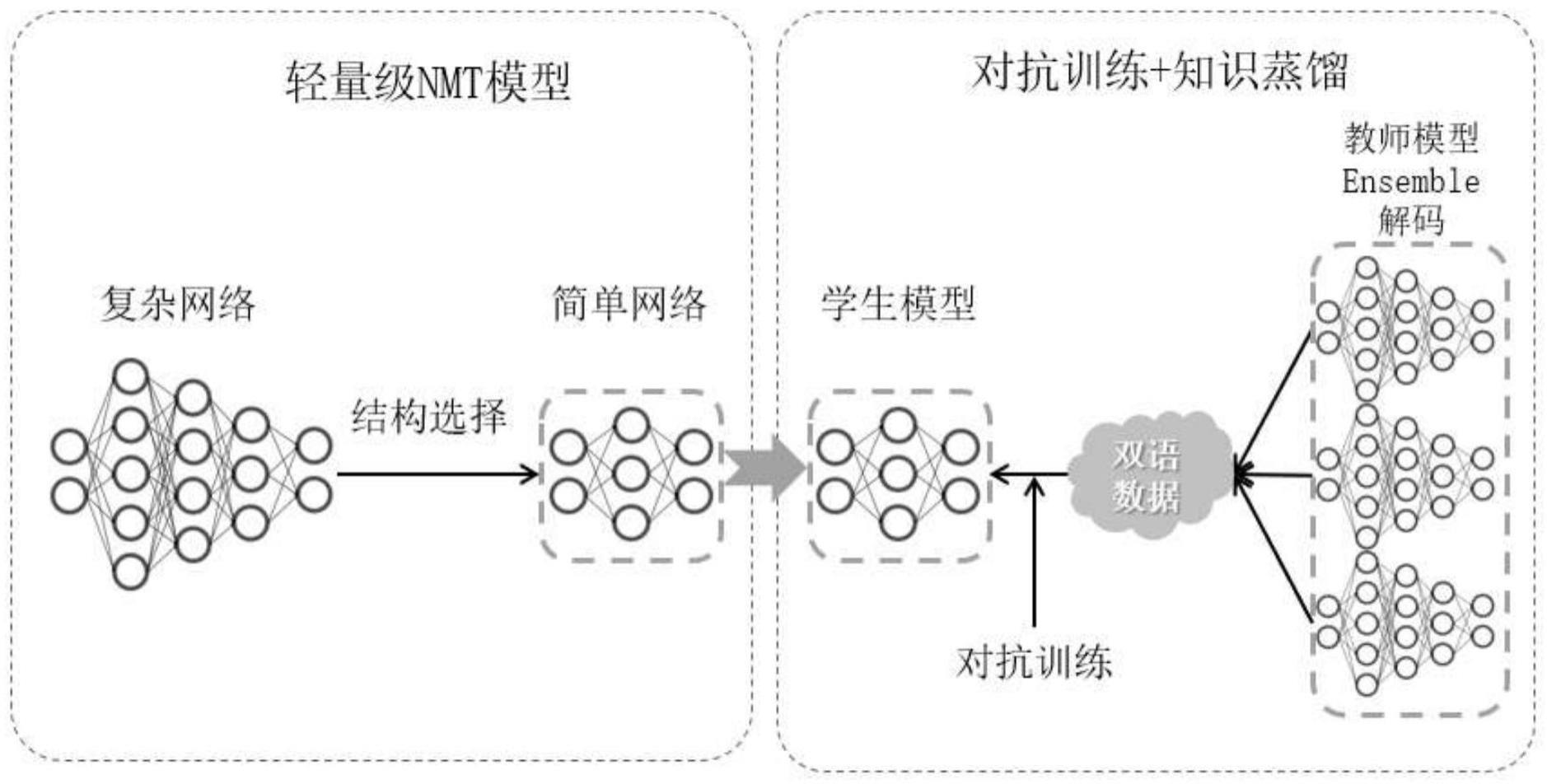
4、1)在网络上获取开源的训练神经机器翻译所需的数据集,并对该数据集进行清洗;
5、2)采用参数量大、结构复杂的大模型作为知识蒸馏必须的教师模型,采用参数量少、结构简单的轻量级transformer模型作为学生模型;
6、3)使用步骤1)中获得开源数据集训练教师模型;
7、4)使用训练好的教师模型解码训练数据,将清洗后的数据集中的源语作为训练输入,将解码出来的译文作为训练目标,重新构造训练数据;
8、5)使用cutoff对抗训练方法和步骤4)构造的训练数据训练学生模型,实现知识蒸馏;
9、6)将步骤5)蒸馏得到的学生模型作为轻量级神经机器翻译模型部署在服务器上,并开发前端html界面、使用tornado框架搭建后端处理程序,构建整个机器翻译系统。
10、步骤2)中,使用神经机器翻译常用的大模型transformer dlcl35、dense768作为教师模型的结构,使用轻量级的transformer 3-1、6-1作为学生模型的结构。
11、步骤5)中,使用cutoff对抗训练方法和步骤4)构造的训练数据训练学生模型,具体步骤为:
12、501)去掉步骤4)构造的新的数据集中长度大于k的句子;
13、502)使用处理好的数据集训练学生模型;
14、503)使用完整的输入数据让模型前向计算一次,并得到结果a;
15、504)使用token cutoff随机掩码掉部分送给模型编码器的数据,让模型前向传播一次,并得到结果b;
16、505)使用token cutoff随机掩码掉部分送给模型解码器的数据,让模型前向传播一次,并得到结果c;
17、506)计算结果a的交叉熵损失并且计算结果a、b、c的对比学习损失,使用两个损失同时对模型参数进行更新。
18、步骤6)中,将蒸馏得到的学生模型作为轻量级神经机器翻译模型部署在服务器上,并开发前端html界面、使用tornado框架搭建后端,构建整个机器翻译系统,具体为:
19、601)搭建输入文本处理接口;
20、602)搭建模型输出的译文文本处理接口;
21、603)搭建前端html交互页面;
22、604)使用tornado框架搭建后端;
23、605)将轻量级神经机器翻译模型上传至服务器,测试整个机器翻译系统。
24、步骤2)中参数量大、结构复杂的大模型为参数量在3亿以上、transformer总层数在24以上的模型;参数量少、结构简单的轻量级transformer模型为参数量在5千万以下、transformer总层数在7以下的transformer模型。
25、本发明具有以下有益效果及优点:
26、1.本发明通过对学生模型结构进行研究和优化,能够非常明显地减少知识蒸馏过程中的性能损失,通过大量实验探索了自然语言处理领域标杆模型transformer可以压缩哪些结构以获得推断速度快、质量较好的轻量级模型结构,并且这些结构可以被运用到其他需要使用轻量级transformer模型的任务上。
27、2.本发明通过在知识蒸馏过程中融入对抗训练,能够有效减少学生模型在蒸馏过程中的性能损耗、明显提升学生模型的鲁棒性,并且不会带来对抗训练难以接受的高额训练代价。此方法可以被运用到其他需要蒸馏小模型的任务中。
技术特征:
1.一种基于知识蒸馏的轻量级神经机器翻译系统构建方法,其特征在于包括以下步骤:
2.按权利要求1所述的基于知识蒸馏的轻量级神经机器翻译系统构建方法,其特征在于:步骤2)中,使用神经机器翻译常用的大模型transformer dlcl35、dense768作为教师模型的结构,使用轻量级的transformer 3-1、6-1作为学生模型的结构。
3.按权利要求1所述的基于知识蒸馏的轻量级神经机器翻译系统构建方法,其特征在于:步骤5)中,使用cutoff对抗训练方法和步骤4)构造的训练数据训练学生模型,具体步骤为:
4.按权利要求1所述的基于知识蒸馏的轻量级神经机器翻译系统构建方法,其特征在于:步骤6)中,将蒸馏得到的学生模型作为轻量级神经机器翻译模型部署在服务器上,并开发前端html界面、使用tornado框架搭建后端,构建整个机器翻译系统,具体为:
5.按权利要求1所述的基于知识蒸馏的轻量级神经机器翻译系统构建方法,其特征在于:步骤2)中参数量大、结构复杂的大模型为参数量在3亿以上、transformer总层数在24以上的模型;参数量少、结构简单的轻量级transformer模型为参数量在5千万以下、transformer总层数在7以下的transformer模型。
技术总结
本发明公开一种基于知识蒸馏的轻量级神经机器翻译系统构建方法,步骤为:获取训练神经机器翻译所需的数据集并进行清洗;采用大模型作为知识蒸馏必须的教师模型,采用轻量级Transformer模型作为学生模型;使用数据集训练教师模型;使用训练好的教师模型解码训练数据,重新构造训练数据;训练学生模型;将学生模型作为轻量级神经机器翻译模型部署在服务器上,并开发前端Html界面、使用Tornado框架搭建后端处理程序,构建整个机器翻译系统。本发明减少了知识蒸馏过程中的性能损失,减少学生模型在蒸馏过程中的性能损耗,提升学生模型的鲁棒性,不会带来对抗训练难以接受的高额训练代价,可被运用到需要蒸馏小模型的任务中。
技术研发人员:杨迪,王之光
受保护的技术使用者:沈阳雅译网络技术有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!