智能建造目标计数方法、电子设备及存储介质与流程
本发明涉及图像处理,具体而言,涉及一种智能建造目标计数方法、电子设备及存储介质。
背景技术:
1、传统的计数,通常是人工计数,存在计数效率低的问题。随着深度学习技术的发展,目前已经可以利用resnext101网络、fasterr-cnn算法等深度学习算法,对图片进行识别,从而进行计数。例如,在钢筋的计数方式上,可以利用resnext101网络、fasterr-cnn算法来实现钢筋的计数。然而,现有的模型算法需要的模型参数的数量多,数据运算量大,对硬件设备的性能要求高。
技术实现思路
1、有鉴于此,本申请实施例的目的在于提供一种智能建造目标计数方法、电子设备及存储介质,能够改善计数的数据运算量大、对硬件设备性能要求高的问题。
2、为实现上述技术目的,本申请采用的技术方案如下:
3、第一方面,本申请实施例提供了一种智能建造目标计数方法,所述方法包括:
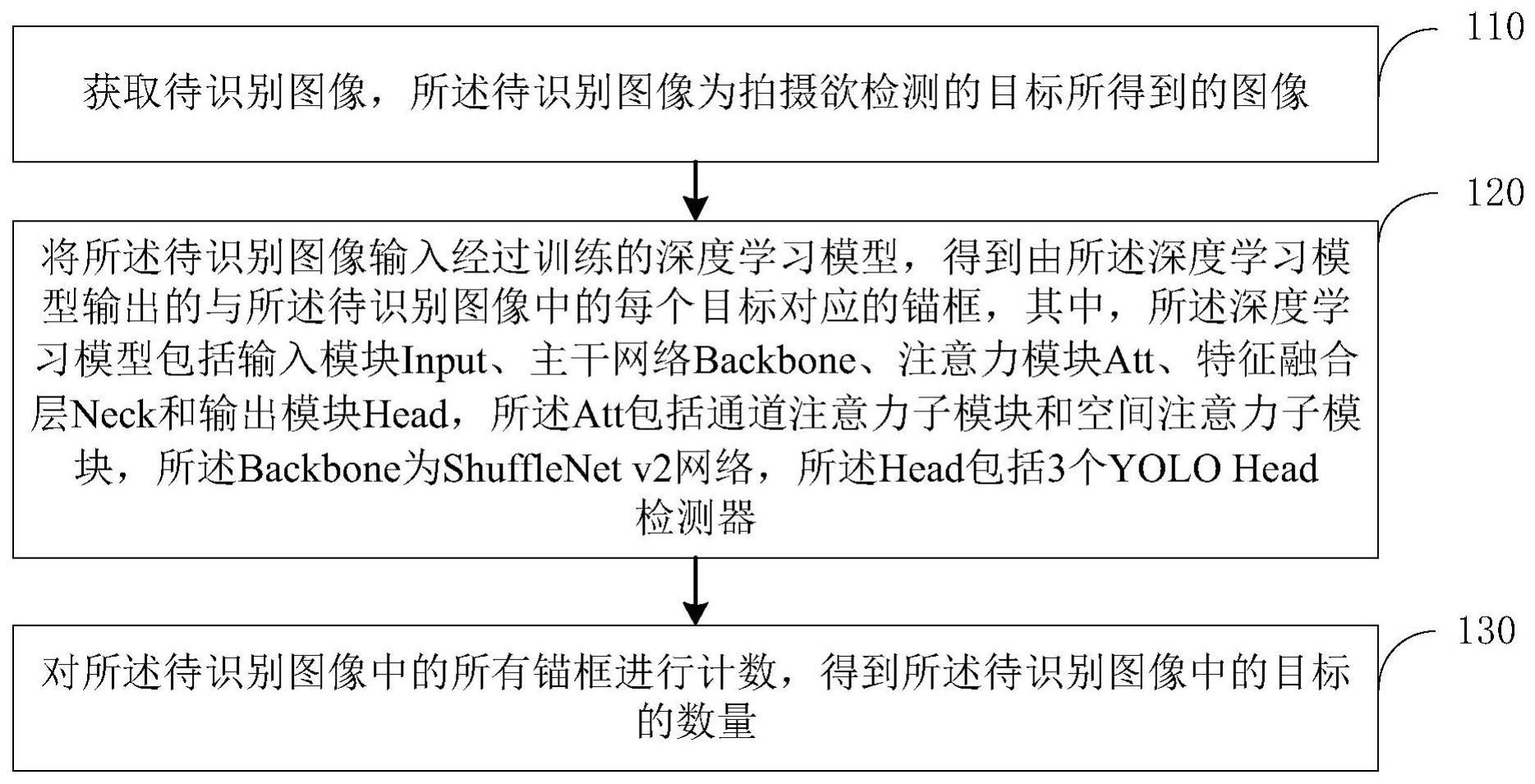
4、获取待识别图像,所述待识别图像为拍摄欲检测的目标所得到的图像;
5、将所述待识别图像输入经过训练的深度学习模型,得到由所述深度学习模型输出的与所述待识别图像中的每个目标对应的锚框,其中,所述深度学习模型包括输入模块input、主干网络backbone、注意力模块att、特征融合层neck和输出模块head,所述att包括通道注意力子模块和空间注意力子模块,所述backbone为shufflenet v2网络,所述head包括3个yolo head检测器;
6、对所述待识别图像中的所有锚框进行计数,得到所述待识别图像中的目标的数量。
7、结合第一方面,在一些可选地实施方式中,将所述待识别图像输入经过训练的深度学习模型,得到由所述深度学习模型输出的与所述待识别图像中的每个目标对应的锚框,包括:
8、通过所述深度学习模型中的所述input将所输入的具有三通道的所述待识别图像,输出至所述shufflenet v2网络;
9、通过所述shufflenet v2网络对所述待识别图像进行特征提取,得到提取的第一类图像特征;
10、通过所述att中的所述通道注意力子模块和所述空间注意力子模块,对所述第一类图像特征进行卷积,得到第二类图像特征;
11、通过所述neck对所述第一类图像特征和所述第二类图像特征进行融合,得到第三类图像特征;
12、通过所述3个yolo head检测器,对所述第三类图像特征进行目标预测,并在所述待识别图像中对预测的目标通过锚框进行标记。
13、结合第一方面,在一些可选地实施方式中,通过所述att中的所述通道注意力子模块和所述空间注意力子模块,对所述第一类图像特征进行卷积,得到第二类图像特征,包括:
14、通过所述通道注意力子模块对所述第一类图像特征进行多频率特征融合,得到融合后的第一类图像特征;
15、通过所述空间注意力子模块对所述融合后的第一类图像特征进行多尺度可变形卷积,得到所述第二类图像特征。
16、结合第一方面,在一些可选地实施方式中,通过所述通道注意力子模块对所述第一类图像特征进行多频率特征融合,得到融合后的第一类图像特征,包括:
17、将所述第一类图像特征依据通道划分成为n个部分,表示为[x0,x1,…,xn-1],其中,n的取值为被所述第一类图像特征的通道数所整除的值;
18、对划分的xi,分配相应的二维dct频率分量,表示为:
19、
20、其中,i取值为0至n-1中的任一整数;frei∈rc为xi经过处理后的多频率向量,h为输入x的高度;w为输入x的宽度;为二维离散余弦变换的基函数;[u,v]指xi的频率分量二维指数;[h,w]指所述基函数中的参数;
21、通压缩函数fsq(x),将n个部分x的频率分量进行合并,得到所述融合后的第一类图像特征,其中,所述压缩函数表示为:fsq(x)=cat([fre0,fre1,…,fren-1])。
22、结合第一方面,在一些可选地实施方式中,通过所述空间注意力子模块对所述融合后的第一类图像特征进行多尺度可变形卷积,得到所述第二类图像特征,包括:
23、通过所述空间注意力子模块对所述融合后的第一类图像特征,采用三种的卷积核并行卷积,得到中间图像特征,其中,三种卷积核的大小分别为1×1,3×3,5×5;
24、通过所述空间注意力子模块,对所述中间图像特征进行3×3卷积,并将卷积后的中间图像特征经过sigmod激活函数处理并输出,得到所述第二类图像特征。
25、结合第一方面,在一些可选地实施方式中,所述neck包括路径聚合网络panet,通过所述neck对所述第一类图像特征和所述第二类图像特征进行融合,得到第三类图像特征,包括:
26、通过路径聚合网络panet,对所述第一类图像特征和所述第二类图像特征进行信息交融,得到所述第三类图像特征。
27、结合第一方面,在一些可选地实施方式中,在获取待识别图像之前,所述方法还包括:
28、获取训练数据集,所述训练数据集包括多张图像,所述多张图像中的每张图像具有期望检测的目标,且设置有与目标对应的标签;
29、利用训练数据集,对预先搭建的深度学习模型进行训练,得到所述经过训练的深度学习模型。
30、结合第一方面,在一些可选地实施方式中,所述目标包括钢筋、木柱、管材中的任一种。
31、第二方面,本申请实施例还提供一种电子设备,所述电子设备包括相互耦合的处理器及存储器,所述存储器内存储计算机程序,当所述计算机程序被所述处理器执行时,使得所述电子设备执行上述的方法。
32、第三方面,本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当所述计算机程序在计算机上运行时,使得所述计算机执行上述的方法。
33、采用上述技术方案的发明,具有如下优点:
34、在本申请提供的技术方案中,将待识别图像输入经过训练的深度学习模型,得到由深度学习模型输出的与待识别图像中的每个目标对应的锚框,然后,对待识别图像中的所有锚框进行计数,得到待识别图像中的目标的数量。由于深度学习模型包括输入模块input、主干网络backbone、注意力模块att、特征融合层neck和输出模块head,att包括通道注意力子模块和空间注意力子模块,backbone为shufflenet v2网络,head包括3个yolohead检测器。由于主干网络是轻量级的shufflenet v2网络,相比于传统的yolov5s主干网络,有利于减少模型参数,降低运算量;另外,引入融合通道和空间的注意机制,可以更有效地学习提取图像特征,有利于提高模型检测的准确性。
技术特征:
1.一种智能建造目标计数方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,将所述待识别图像输入经过训练的深度学习模型,得到由所述深度学习模型输出的与所述待识别图像中的每个目标对应的锚框,包括:
3.根据权利要求2所述的方法,其特征在于,通过所述att中的所述通道注意力子模块和所述空间注意力子模块,对所述第一类图像特征进行卷积,得到第二类图像特征,包括:
4.根据权利要求3所述的方法,其特征在于,通过所述通道注意力子模块对所述第一类图像特征进行多频率特征融合,得到融合后的第一类图像特征,包括:
5.根据权利要求3所述的方法,其特征在于,通过所述空间注意力子模块对所述融合后的第一类图像特征进行多尺度可变形卷积,得到所述第二类图像特征,包括:
6.根据权利要求2所述的方法,其特征在于,所述neck包括路径聚合网络panet,通过所述neck对所述第一类图像特征和所述第二类图像特征进行融合,得到第三类图像特征,包括:
7.根据权利要求1所述的方法,其特征在于,在获取待识别图像之前,所述方法还包括:
8.根据权利要求1-7中任一项所述的方法,其特征在于,所述目标包括钢筋、木柱、管材中的任一种。
9.一种电子设备,其特征在于,所述电子设备包括相互耦合的处理器及存储器,所述存储器内存储计算机程序,当所述计算机程序被所述处理器执行时,使得所述电子设备执行如权利要求1-8中任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,当所述计算机程序在计算机上运行时,使得所述计算机执行如权利要求1-8中任一项所述的方法。
技术总结
本申请提供一种智能建造目标计数方法、电子设备及存储介质。方法包括:获取待识别图像;将待识别图像输入经过训练的深度学习模型,得到由深度学习模型输出的与待识别图像中的每个目标对应的锚框,其中,深度学习模型包括输入模块Input、主干网络Backbone、注意力模块Att、特征融合层Neck和输出模块Head,Att包括通道注意力子模块和空间注意力子模块,Backbone为ShuffleNet v2网络,Head包括3个YOLO Head检测器;对待识别图像中的所有锚框进行计数,得到待识别图像中的目标的数量,如此,有利于减少模型参数,降低运算量。
技术研发人员:李顺祥,周伯成,邓曦,熊伶,黄才生,蒋有高,刘寿松,钱琪,王楷
受保护的技术使用者:重庆市西部水资源开发有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!