数据读取的最优路径的确定方法、确定装置和电子设备与流程
本申请涉及k8s数据处理,具体而言,涉及一种数据读取的最优路径的确定方法、确定装置和电子设备。
背景技术:
1、在大规模presto集群部署中,由于presto读取数据的最优路径仅仅通过机架位置(机房内安装有多个物理机,每个物理机的安装位置不同,机架位置即为物理机的位置)来判断,同时还会存在数据仓库工具(例如hive)在资源管理器(yet another resourcenegotiator,简称yarn)上执行任务对读取数据造成影响,以上都会让容器(worker)无法分配到最适合的分片数据进行读取和计算,因此,目前的方案中,由于计算presto读取数据的最优路径的效率较低,会导致最优路径的准确率较低,这样会导致读写成本过高,最终造成sql语句的查询效率较低。
技术实现思路
1、本申请的主要目的在于提供一种数据读取的最优路径的确定方法、确定装置和电子设备,以解决现有技术中由于计算presto读取数据的最优路径的效率较低,会导致最优路径的准确率较低,这样会导致读写成本过高,最终造成sql语句的查询效率较低的问题。
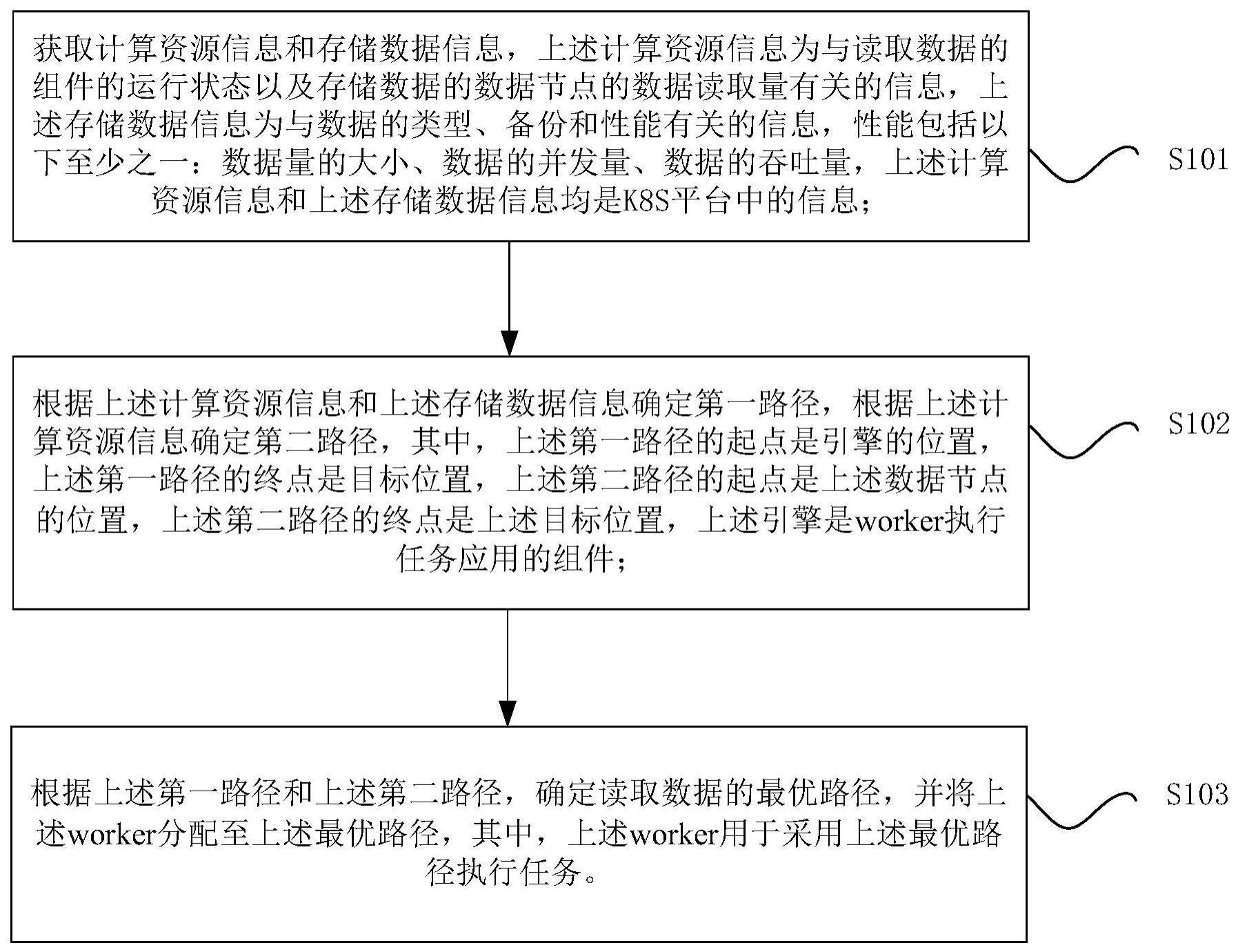
2、根据本发明实施例的一个方面,提供了一种数据读取的最优路径的确定方法,包括:获取计算资源信息和存储数据信息,所述计算资源信息为与读取数据的组件的运行状态以及存储数据的数据节点的数据读取量有关的信息,所述存储数据信息为与数据的类型、备份和性能有关的信息,性能包括以下至少之一:数据量的大小、数据的并发量、数据的吞吐量,所述计算资源信息和所述存储数据信息均是k8s平台中的信息;根据所述计算资源信息和所述存储数据信息确定第一路径,根据所述计算资源信息确定第二路径,其中,所述第一路径的起点是引擎的位置,所述第一路径的终点是目标位置,所述第二路径的起点是所述数据节点的位置,所述第二路径的终点是所述目标位置,所述引擎是worker执行任务应用的组件;根据所述第一路径和所述第二路径,确定读取数据的最优路径,并将所述worker分配至所述最优路径,其中,所述worker用于采用所述最优路径执行任务。
3、可选地,根据所述计算资源信息和所述存储数据信息确定第一路径,根据所述计算资源信息确定第二路径,包括:采用决策树算法、加权统计算法和k-means算法,对所述计算资源信息和所述存储数据信息进行处理,得到所述第一路径;采用边缘算法对所述计算资源信息进行处理,得到所述第二路径。
4、可选地,采用决策树算法、加权统计算法和k-means算法,对所述计算资源信息和所述存储数据信息进行处理,得到所述第一路径,包括:将所述计算资源信息和所述存储数据信息输入至决策树中进行分类,得到分类结果,确定所述分类结果中符合预定条件的目标分类结果,根据所述目标分类结果确定多个所述worker,其中,任意两个所述worker的位置不同;根据所述加权统计算法获取多个权重信息,一个所述权重信息对应一个所述worker在数据读取中的重要程度;根据所述worker以及与所述worker对应的所述权重信息,将所述引擎分配给与所述引擎距离最近的所述worker,并确定从多个所述引擎的位置到所述目标位置的多个路径中最短的路径为所述第一路径。
5、可选地,采用边缘算法对所述计算资源信息进行处理,得到所述第二路径,包括:根据所述计算资源信息确定多个所述数据节点的位置;确定从多个所述数据节点的位置到所述目标位置的多个路径;确定多个所述路径中最短的路径为所述第二路径。
6、可选地,根据所述第一路径和所述第二路径,确定读取数据的最优路径,包括:比较所述第一路径的长度和所述第二路径的长度;确定所述第一路径和所述第二路径中长度最短的路径为所述最优路径。
7、可选地,将所述worker分配至所述最优路径,包括:对目标数据进行拆分,得到多个分片数据,所述目标数据为所述目标位置处的数据;根据多个所述分片数据,生成多个分片任务,并且将多个所述分片任务分配至对应的所述worker;控制各所述worker执行对应的所述分片任务,其中,各所述worker执行所述分片任务采用的路径为最优子路径,所述最优子路径是指所述worker执行所述分片任务的最优路径;将多个所述分片任务聚合得到目标任务,确定所述目标任务对应的目标worker,其中,所述目标worker执行所述目标任务采用的路径为最优路径。
8、可选地,所述方法还包括:确定所述worker执行的所述任务的数量是否大于或者等于数量阈值;在所述worker执行的所述任务的数量大于或者等于所述数量阈值的情况下,将所述worker添加至队列中;在所述worker执行的所述任务的数量小于所述数量阈值的情况下,为所述worker添加新的任务。
9、可选地,在获取计算资源信息和存储数据信息之前,所述方法还包括:确定强制调度功能是否有效;在所述强制调度功能有效的情况下,遍历所有的所述worker的位置,在有所述worker的位置与所述目标位置相同的情况下,将所述worker添加至队列中;在所述强制调度功能失效的情况下,获取所述计算资源信息和所述存储数据信息。
10、根据本发明实施例的另一方面,还提供了一种数据读取的最优路径的确定装置,包括:第一获取单元,用于获取计算资源信息和存储数据信息,所述计算资源信息为与读取数据的组件的运行状态以及存储数据的数据节点的数据读取量有关的信息,所述存储数据信息为与数据的类型、备份和性能有关的信息,性能包括以下至少之一:数据量的大小、数据的并发量、数据的吞吐量,所述计算资源信息和所述存储数据信息均是k8s平台中的信息;第一确定单元,用于根据所述计算资源信息和所述存储数据信息确定第一路径,根据所述计算资源信息确定第二路径,其中,所述第一路径的起点是引擎的位置,所述第一路径的终点是目标位置,所述第二路径的起点是所述数据节点的位置,所述第二路径的终点是所述目标位置,所述引擎是worker执行任务应用的组件;第二确定单元,用于根据所述第一路径和所述第二路径,确定读取数据的最优路径,并将所述worker分配至所述最优路径,其中,所述worker用于采用所述最优路径执行任务。
11、根据本发明实施例的又一方面,还提供了一种电子设备,包括:一个或多个处理器,存储器以及一个或多个程序,其中,所述一个或多个程序被存储在所述存储器中,并且被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行任意一种所述的方法。
12、在本发明实施例中,首先获取计算资源信息和存储数据信息,之后根据计算资源信息和存储数据信息确定第一路径,最后根据第一路径和第二路径,确定读取数据的最优路径,并将worker分配至最优路径。该方案中,通过在k8s平台中部署presto,可以获取计算资源信息和存储数据信息,根据计算资源信息和存储数据信息可以确定读取数据的最优路径,本方案通过多种信息来确定的最优路径的准确率较高,进而可以降低数据的读写成本,从而提高了sql语句的查询效率。
技术特征:
1.一种数据读取的最优路径的确定方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,根据所述计算资源信息和所述存储数据信息确定第一路径,根据所述计算资源信息确定第二路径,包括:
3.根据权利要求2所述的方法,其特征在于,采用决策树算法、加权统计算法和k-means算法,对所述计算资源信息和所述存储数据信息进行处理,得到所述第一路径,包括:
4.根据权利要求2所述的方法,其特征在于,采用边缘算法对所述计算资源信息进行处理,得到所述第二路径,包括:
5.根据权利要求1所述的方法,其特征在于,根据所述第一路径和所述第二路径,确定读取数据的最优路径,包括:
6.根据权利要求1所述的方法,其特征在于,将所述worker分配至所述最优路径,包括:
7.根据权利要求1所述的方法,其特征在于,所述方法还包括:
8.根据权利要求1所述的方法,其特征在于,在获取计算资源信息和存储数据信息之前,所述方法还包括:
9.一种数据读取的最优路径的确定装置,其特征在于,包括:
10.一种电子设备,其特征在于,包括:一个或多个处理器,存储器以及一个或多个程序,其中,所述一个或多个程序被存储在所述存储器中,并且被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行权利要求1至7中任意一项所述的方法。
技术总结
本申请提供了一种数据读取的最优路径的确定方法、确定装置和电子设备。该方法包括:获取计算资源信息和存储数据信息;根据计算资源信息和存储数据信息确定第一路径,根据计算资源信息确定第二路径;根据第一路径和第二路径,确定读取数据的最优路径,并将worker分配至最优路径,其中,worker用于采用最优路径执行任务。该方案中,通过在K8S平台中部署Presto,可以获取计算资源信息和存储数据信息,根据计算资源信息和存储数据信息可以确定读取数据的最优路径,本方案通过多种信息来确定的最优路径的准确率较高,进而可以降低数据的读写成本,从而提高了SQL语句的查询效率。
技术研发人员:谢伟,吴佳华,侯小月,苏威,任帅
受保护的技术使用者:中国邮政储蓄银行股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!