一种视频实例分割方法、装置及介质
本发明涉及视频处理,特别是关于一种视频实例分割方法、装置及计算机可读存储介质。
背景技术:
1、视频实例分割任务是继图像的目标检测、语义分割、实例分割以及目标跟踪之后,被提出的一项相对较新的计算机视觉任务。视频实例分割任务旨在对视频帧的视频内容进行实例的识别和分割,同时在不同的视频帧之间实现相同实例的匹配。视频实例分割任务,相对于图像的目标跟踪任务,可以实现更为明确的实例划分。
2、视频实例分割任务被提出以后,主流的算法模型以两阶段的方式实现任务。第一阶段是实现帧内图像的实例分割,第二阶段再实现帧与帧之间的实例匹配。
3、然而,本申请的发明人在研究中发现,现有技术的第二阶段在实现帧与帧进行实例匹配时,其提取的实例图像的特征的表征能力还有待增强,即现有技术提取的实例匹配的效果存在着提高的空间。并且,第二阶段的帧与帧之间的实例匹配的结果,依赖于第一阶段的帧内图像的实例分割的结果,如果第一阶段的实例分割的结果更为准确,第二阶段的匹配结果才能更好。
技术实现思路
1、针对上述问题,本发明的目的是提供一种视频实例分割方法、装置及计算机可读存储介质,能够提取更好表征实例的特征向量,实现帧与帧之间的更好的实例匹配。
2、为实现上述目的,本发明采取以下技术方案:
3、第一方面,本申请提供视频实例分割方法,所述方法包括:
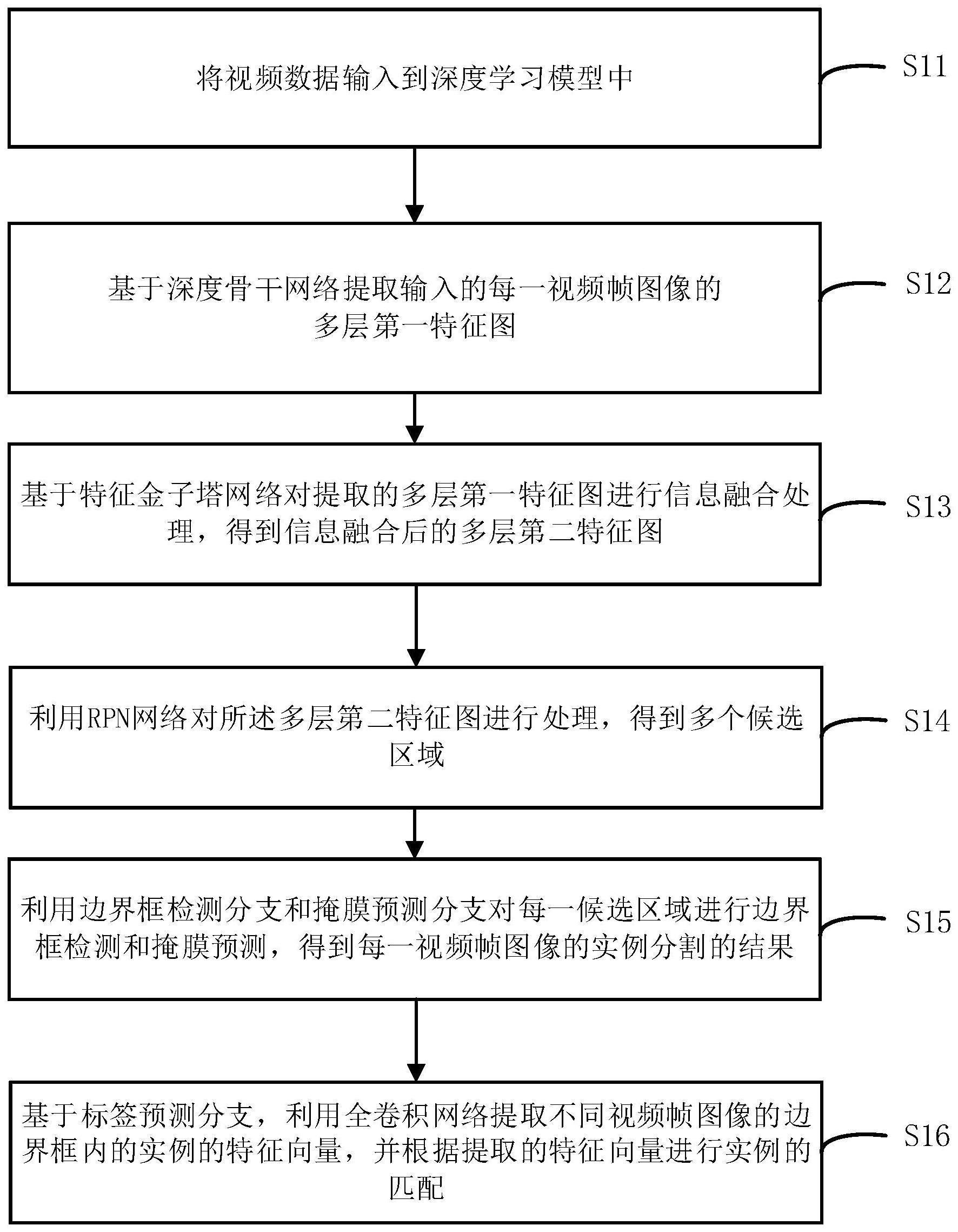
4、将视频数据输入到深度学习模型中,所述深度学习模型包括深度骨干网络、特征金子塔网络、rpn网络、边界框检测分支、掩膜预测分支以及标签预测分支;
5、基于所述深度骨干网络提取输入的每一视频帧图像的多层第一特征图;
6、基于所述特征金子塔网络对提取的多层第一特征图进行信息融合处理,得到信息融合后的多层第二特征图;
7、利用所述rpn网络对所述多层第二特征图进行处理,得到多个候选区域;
8、利用所述边界框检测分支和所述掩膜预测分支对每一所述候选区域进行边界框检测和掩膜预测,得到每一所述视频帧图像的实例分割的结果;
9、基于所述标签预测分支,利用全卷积网络提取不同视频帧图像的边界框内的实例的特征向量,并根据提取的特征向量进行实例的匹配。
10、在本申请的一种实现方式中,所述方法还包括:对输入的视频数据的每一视频帧图像进行预处理,再输入所述深度学习模型中。
11、在本申请的一种实现方式中,所述基于所述深度骨干网络提取输入的每一视频帧图像的多层第一特征图,包括:基于resnet骨干残差网络提取输入的每一视频帧图像的多层第一特征图。
12、在本申请的一种实现方式中,所述基于所述特征金子塔网络对提取的多层第一特征图进行信息融合处理,包括:
13、对提取的多层第一特征图进行自上而下的信息融合处理,并将每一层第一特征图与其之上的一层第一特征图进行信息融合。
14、在本申请的一种实现方式中,所述利用全卷积网络提取不同视频帧图像的边界框内的实例的特征向量,包括:
15、利用全卷积递归网络结构提取不同视频帧图像的边界框内的实例的特征向量。
16、在本申请的一种实现方式中,所述利用全卷积递归网络结构提取不同视频帧图像的边界框内的实例的特征向量,包括:
17、将边界框内图像输入到预测层级的的卷积层中进行特征提取;
18、将经过所述预测层级的卷积层特征提取的结果再次递归输入到所述预测层级的卷积层中进行特征提取;
19、将所述递归输入到所述预测层级的卷积层中进行特征提取的结果,经过全局平均池化获取到边界框内的实例的特征向量。
20、在本申请的一种实现方式中,所述方法还包括:预先对所述深度学习模型进行循环训练,直至所述深度学习模型收敛。
21、在本申请的一种实现方式中,所述对所述深度学习模型进行循环训练,包括:
22、采用随机梯度下降优化算法对所述深度学习网络的权重进行学习和更新,直至所述深度学习模型收敛。
23、第二方面,本申请提供一种视频实例分割装置,所述视频实例分割装置,包括深度骨干网络、特征金子塔网络、rpn网络、边界框检测分支、掩膜预测分支以及标签预测分支;
24、所述深度骨干网络,用于提取输入的每一视频帧图像的多层第一特征图;
25、所述特征金子塔网络,用于对提取的多层第一特征图进行信息融合处理,得到信息融合后的多层第二特征图;
26、所述rpn网络,用于对所述多层第二特征图进行处理,得到多个候选区域;
27、所述边界框检测分支和所述掩膜预测分支,用于对每一所述候选区域进行边界框检测和掩膜预测,得到每一所述视频帧图像的实例分割的结果;
28、所述标签预测分支,用于利用全卷积网络提取不同视频帧图像的边界框内的实例的特征向量,并根据提取的特征向量进行实例的匹配。
29、第三方面,本申请提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述第一方面所述的视频实例分割方法。
30、本发明由于采取以上技术方案,其具有以下优点:本发明申请方案中将视频数据输入到深度学习模型中,基于深度骨干提取每一帧视频图像的多层第一特征图,并基于特征金字塔网络对提取的第一特征图进行信息融合处理,得到第二特征图,由于第二特征图是由信息融合处理后得到的,既兼顾到高层特征的语义信息,又具有低层特征定位准确性高的优势,再进一步利用rpn网络进行候选区域的生成,以及利用边界框检测分支和掩膜预测分支进行处理时,就可以得到质量更高的实例分割结果。同时,本申请基于所述标签预测分支,利用全卷积网络提取不同视频帧图像的边界框内的实例的特征向量,并根据提取的特征向量进行实例的匹配,由此可以提取到具有到更好表征实例的特征向量,实现帧与帧之间的更好的实例匹配。
技术特征:
1.一种视频实例分割方法,其特征在于,所述方法包括:
2.根据权利要求1所述的视频实例分割方法,其特征在于,所述方法还包括:对输入的视频数据的每一视频帧图像进行预处理,再输入所述深度学习模型中。
3.根据权利要求2所述的视频实例分割方法,其特征在于,所述基于所述深度骨干网络提取输入的每一视频帧图像的多层第一特征图,包括:基于resnet骨干残差网络提取输入的每一视频帧图像的多层第一特征图。
4.根据权利要求3所述的视频实例分割方法,其特征在于,所述基于所述特征金子塔网络对提取的多层第一特征图进行信息融合处理,包括:
5.根据权利要求1所述的视频分割方法,其特征在于,所述利用全卷积网络提取不同视频帧图像的边界框内的实例的特征向量,包括:
6.根据权利要求1所述的视频分割方法,其特征在于,所述利用全卷积递归网络结构提取不同视频帧图像的边界框内的实例的特征向量,包括:
7.根据权利要求1所述的实例分割方法,其特征在于,所述方法还包括:预先对所述深度学习模型进行循环训练,直至所述深度学习模型收敛。
8.根据权利要求7所述的实例分割方法,其特征在于,所述对所述深度学习模型进行循环训练,包括:
9.一种视频实例分割装置,其特征在于,所述视频实例分割装置,包括深度骨干网络、特征金子塔网络、rpn网络、边界框检测分支、掩膜预测分支以及标签预测分支;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,所述计算机程序运行时控制所述计算机可读存储介质所在设备执行权利要求1至8任一项所述的视频实例分割方法。
技术总结
本发明涉及一种视频实例分割方法、装置及存储介质,所述方法包括:将视频数据输入到深度学习模型中;基于所述深度骨干网络提取输入的每一视频帧图像的多层第一特征图;基于所述特征金子塔网络对提取的多层第一特征图进行信息融合处理,得到信息融合后的多层第二特征图;利用所述RPN网络对所述多层第二特征图进行处理,得到多个候选区域;利用所述边界框检测分支和所述掩膜预测分支对每一所述候选区域进行边界框检测和掩膜预测,得到每一所述视频帧图像的实例分割的结果;基于所述标签预测分支,利用全卷积网络提取不同视频帧图像的边界框内的实例的特征向量,并根据提取的特征向量进行实例的匹配。
技术研发人员:胡坚明,石运达,李力,姚丹亚
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!