文本聚类方法、装置、电子设备和计算机可读存储介质
本申请涉及数据处理领域,尤其涉及一种文本聚类方法、装置、电子设备和计算机可读存储介质。
背景技术:
1、随着信息技术的快速发展,作为信息载体的文本以远超人们所能处理的速度爆炸式的快速增长,为了从海量的文本中获得人们需要的文本,往往需要对多个文本进行聚类处理,而对多个文本进行聚类处理的过程中可能会存在将同一类别的文本分配至不同类别中,使得对多个文本进行聚类的过程中准确率不高。
技术实现思路
1、本申请实施例提供一种文本聚类方法、装置、电子设备和计算机可读存储介质,可以解决对多个文本进行聚类过程中准确性不高的技术问题。
2、第一方面,本申请实施例提供一种文本聚类方法,所述方法包括:
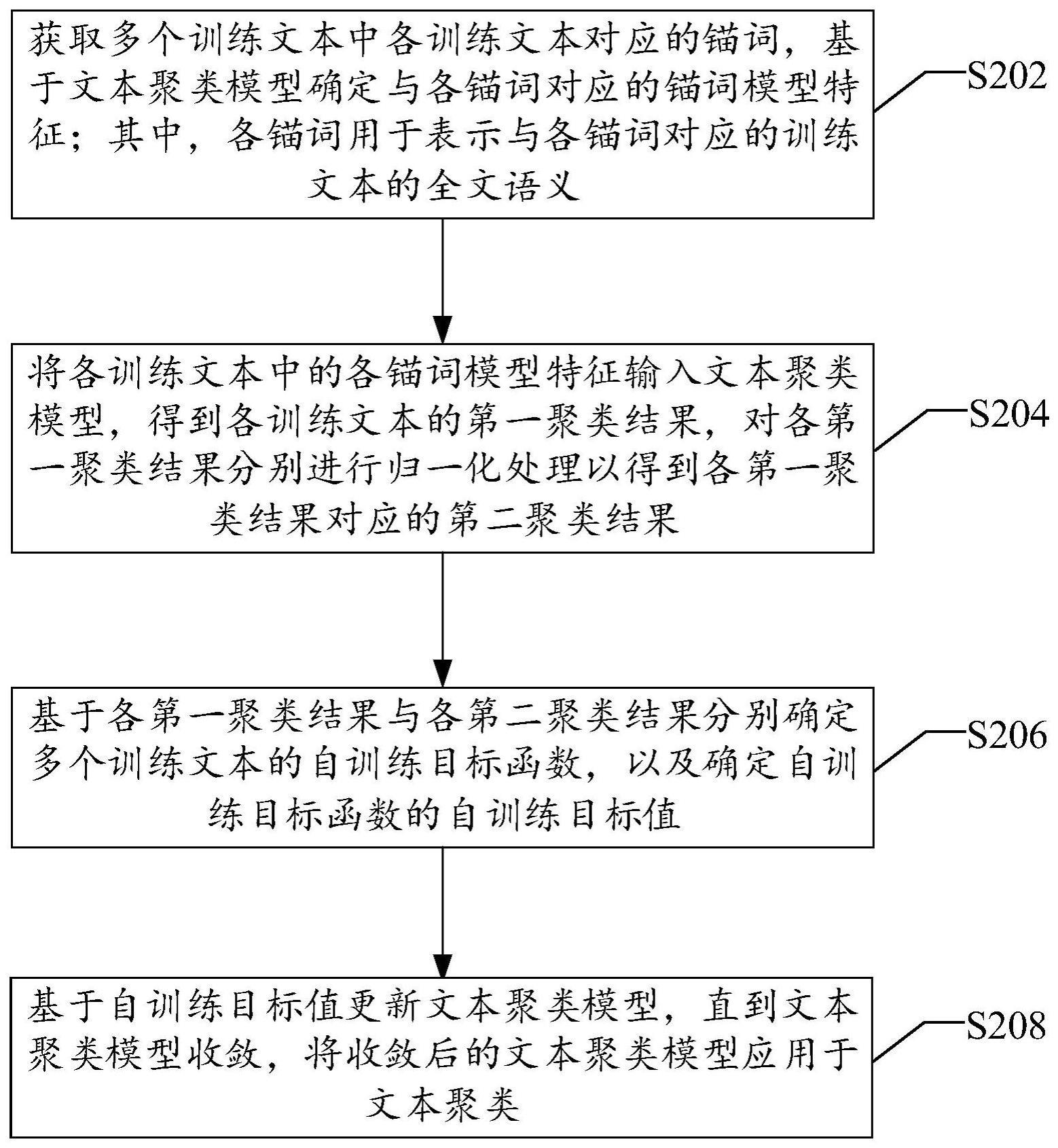
3、获取多个训练文本中各训练文本对应的锚词,基于文本聚类模型确定与各锚词对应的锚词模型特征;其中,各锚词用于表示与各锚词对应的训练文本的全文语义;
4、将各训练文本中的各锚词模型特征输入所述文本聚类模型,得到各训练文本的第一聚类结果,对各第一聚类结果分别进行归一化处理以得到各第一聚类结果对应的第二聚类结果;
5、基于各第一聚类结果与各第二聚类结果分别确定所述多个训练文本的自训练目标函数,以及确定所述自训练目标函数的自训练目标值;
6、基于所述自训练目标值更新所述文本聚类模型,直到所述文本聚类模型收敛,将收敛后的文本聚类模型应用于文本聚类。
7、可选地,所述获取多个训练文本中各训练文本对应的锚词包括:
8、基于多个训练文本中每个训练文本中的组成词,确定每个训练文本中各组成词的信息量权重;
9、将每个训练文本对应的各组成词的信息量权重分别由大至小进行排序,获得每个训练文本对应的排序在前的预设锚词数量的信息量权重;
10、基于所述预设锚词数量的信息量权重对应的组成词,得到每个训练文本中对应的所述预设锚词数量的锚词。
11、可选地,所述将各训练文本中的各锚词模型特征输入所述文本聚类模型,得到各训练文本的第一聚类结果包括:
12、将每个训练文本中的各锚词模型特征分别输入所述文本聚类模型,得到每个训练文本中各锚词模型特征的预聚类结果;
13、将每个训练文本中的各锚词模型特征对应的预聚类结果进行加权平均,得到每个训练文本的第一聚类结果。
14、可选地,所述基于各第一聚类结果与各第二聚类结果分别确定所述多个训练文本的自训练目标函数包括:
15、基于每个训练文本中各锚词模型特征的预聚类结果与每个训练文本对应的第二聚类结果,得到每个训练文本中各锚词模型特征的损失函数;
16、基于每个训练文本中各锚词模型特征的损失函数,得到每个训练文本的加权损失函数;
17、基于每个训练文本的加权损失函数,确定所述多个训练文本的自训练目标函数。
18、可选地,所述基于每个训练文本中各锚词模型特征的损失函数,得到每个训练文本的加权损失函数,包括:
19、基于每个训练文本中各锚词的信息量权重,确定对应各锚词模型特征的第一系数;其中,所述第一系数包括所述各锚词的注意力权重和锚词模型特征的乘积的范数;
20、累加每个训练文本中各锚词模型特征的第一系数,获得每个训练文本中所有锚词模型特征对应的第二系数;
21、根据每个训练文本中各第一系数在每个训练文本中所有锚词模型特征对应的第二系数中的占比,确定每个训练文本中各锚词模型特征的损失函数对应的加权系数;
22、基于每个训练文本中各锚词模型特征的损失函数以及各锚词模型特征的加权损失函数对应的加权系数,确定每个训练文本的加权损失函数。
23、可选地,在对各第一聚类结果分别进行归一化处理以得到各第一聚类结果对应的第二聚类结果之后,还包括:
24、基于各锚词模型特征、所述多个训练文本的第二聚类结果中的目标集群,确定锚词模型特征扩充函数;其中所述锚词模型特征扩充函数包括高斯分布函数,所述高斯分布函数的均值包括所述锚词模型特征,所述高斯分布函数的方差包括所述目标集群;
25、基于各锚词模型特征和对应各锚词模型特征的各锚词模型特征扩充函数扩充锚词模型特征。
26、可选地,所述基于各第一聚类结果与各第二聚类结果分别确定所述多个训练文本的自训练目标函数包括:
27、基于每个训练文本中各锚词模型特征的预聚类结果与每个训练文本对应的第二聚类结果,得到每个训练文本中各锚词模型特征的损失函数;
28、基于每个训练文本中各锚词模型特征的损失函数,确定各训练文本的加权期望函数;
29、基于各训练文本的加权期望函数,确定所述多个训练文本的自训练目标函数。
30、第二方面,本申请实施例还提供了一种文本聚类装置,所述装置包括:
31、获取模块,适于获取多个训练文本中各训练文本对应的锚词,基于文本聚类模型确定与各锚词对应的锚词模型特征;其中,各锚词用于表示与各锚词对应的训练文本的全文语义;
32、计算模块,适于将各训练文本中的各锚词模型特征输入所述文本聚类模型,得到各训练文本的第一聚类结果,对各第一聚类结果分别进行归一化处理以得到各第一聚类结果对应的第二聚类结果;
33、确定模块,适于基于各第一聚类结果与各第二聚类结果分别确定所述多个训练文本的自训练目标函数,以及确定所述自训练目标函数的自训练目标值;
34、文本聚类模块,适于基于所述自训练目标值更新所述文本聚类模型,直到所述自训练目标值收敛,将收敛后的自训练目标值对应的文本聚类模型应用于文本聚类。
35、第三方面,本申请实施例还提供了一种电子设备,该电子设备包括:
36、处理器;以及
37、被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器执行上诉中任一项所述的方法。
38、第四方面,本申请实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储一个或多个程序,所述一个或多个程序当被处理器执行时,实现上述中任一项所述的方法。
39、本申请实施例提供一种文本聚类方法,基于用以表示各训练文本的全文语义对应的锚词,得到与锚词相应的锚词模型特征,避免额外嘈杂特征的引入,之后,基于锚词模型特征得到各训练文本的第一聚类结果和第二聚类结果,并基于各第一聚类结果与各第二聚类结果分别确定多个训练文本的自训练目标函数,以及确定自训练目标函数的自训练目标值;最后基于自训练目标值更新文本聚类模型,直到文本聚类模型收敛,将收敛后的文本聚类模型应用于文本聚类,经过不断训练直到收敛的文本聚类模型的准确性和稳定性均在不断提高,并且避免了文本聚类的准确率受到额外嘈杂特征的影响。
技术特征:
1.一种文本聚类方法,其特征在于,所述方法包括:
2.如权利要求1所述的文本聚类方法,其特征在于,所述获取多个训练文本中各训练文本对应的锚词包括:
3.如权利要求1所述的文本聚类方法,其特征在于,所述将各训练文本中的各锚词模型特征输入所述文本聚类模型,得到各训练文本的第一聚类结果包括:
4.如权利要求3所述的文本聚类方法,其特征在于,所述基于各第一聚类结果与各第二聚类结果分别确定所述多个训练文本的自训练目标函数包括:
5.如权利要求4所述的文本聚类方法,其特征在于,所述基于每个训练文本中各锚词模型特征的损失函数,得到每个训练文本的加权损失函数,包括:
6.如权利要求1所述的文本聚类方法,其特征在于,在对各第一聚类结果分别进行归一化处理以得到各第一聚类结果对应的第二聚类结果之后,还包括:
7.如权利要求1至6任一项所述的文本聚类方法,其特征在于,所述基于各第一聚类结果与各第二聚类结果分别确定所述多个训练文本的自训练目标函数包括:
8.一种文本聚类装置,其中,所述装置包括:
9.一种电子设备,其中,该电子设备包括:
10.一种计算机可读存储介质,其中,所述计算机可读存储介质存储一个或多个程序,所述一个或多个程序当被处理器执行时,实现权利要求1至7中任一项所述的方法。
技术总结
本申请通过提供一种文本聚类方法、装置、电子设备和计算机可读存储介质,基于用以表示各训练文本的全文语义对应的锚词,得到与锚词相应的锚词模型特征,避免额外嘈杂特征的引入,之后,基于锚词模型特征得到各训练文本的第一聚类结果和第二聚类结果,并基于各第一聚类结果与各第二聚类结果分别确定多个训练文本的自训练目标函数,以及确定自训练目标函数的自训练目标值;最后基于自训练目标值更新文本聚类模型,直到文本聚类模型收敛,将收敛后的文本聚类模型应用于文本聚类,经过不断训练直到收敛的文本聚类模型的准确性和稳定性均在不断提高,并且避免了文本聚类的准确率受到额外嘈杂特征的影响。
技术研发人员:程博,李熙铭,常毅
受保护的技术使用者:吉林大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!