用于文件的数据处理方法及系统与流程
本发明涉及文件数据处理领域,具体来说涉及一种用于文件的数据处理方法及数据处理系统。
背景技术:
1、投标文件数据处理是指从投标文件中提取出分项报价表、企业基本情况等结构化的数据。如今市场竞争激烈,每次招标都会遇到海量的投标文件,要从海量的数据中过滤出重要信息,采用传统的人工阅读的方式不仅效率低,有时甚至是不切实际的。
2、现有文档数据处理的方法主要可以分为两种:1.文本提取法:直接提取文档中的多个文本行的文本信息以及对应的位置信息,对文本信息和位置信息进行编码、解码等操作,得到非结构化数据。2.图像提取法:将文档页面提取为图像文件,采用计算机视觉识别技术提取页面内容,并用版面识别技术对数据结构进行还原,得到结构化数据。一般来说,文本提取法提取速度快,准确率较高,不会受其他因素(例如水印)影响。而图像提取法则应用范围广,通过将文档转化为图像文件,可以处理所有类型的pdf文档。
3、但是,文本提取法只能处理采用标准字符编码的普通pdf文档,且无法处理扫描版pdf文档;至于图像提取法,投标文件一般页数众多,且每页都包含水印,若直接采用图像识别和版面识别技术对每页内容进行提取,提取效率和提取精度都很低,且识别精度容易受到其他类型因素(例如水印)影响,难以满足大规模应用需求。
4、本发明试图解决以上问题,提出一种用于投标文件的数据处理方法和数据处理系统,其综合利用了文本提取法和图像提取法的优点,同时避免文本提取法和图像提取法的缺点。
技术实现思路
1、本发明提出一种用于投标文件的数据处理方法及系统,能够高效地从投标文件的非结构化数据中提取出结构化数据,提高评标效率。
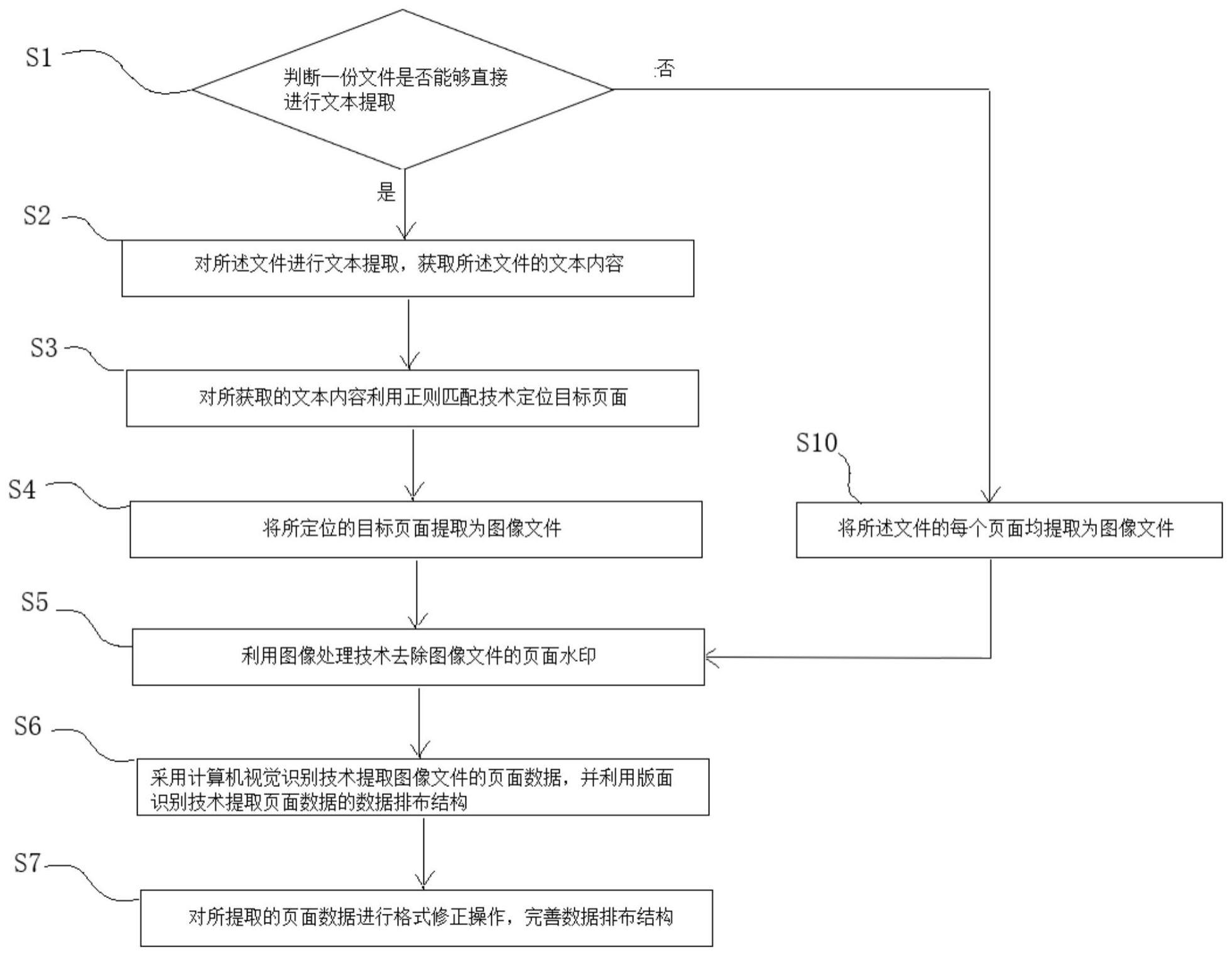
2、本发明第一方面实施例提供一种用于文件的数据处理方法,包括:步骤1:判断一份文件是否能够直接进行文本提取,若能,则进入下一步;步骤2:对所述文件进行文本提取,获取所述文件的文本内容;步骤3:对所获取的文本内容利用正则匹配技术定位目标页面;步骤4:将所定位的目标页面提取为图像文件;步骤5:利用图像处理技术去除图像文件的页面水印;步骤6:采用计算机视觉识别技术提取图像文件的页面数据,并利用版面识别技术提取页面数据的数据排布结构;以及步骤7:对所提取的页面数据进行格式修正操作,完善数据排布结构。
3、进一步地,所述步骤1还包括:判断一份文件是否能够直接进行文本提取,若不能,则将所述文件的每个页面均提取为图像文件,再进入步骤5。
4、进一步地,所述步骤1可还包括:步骤8:提取所述文件前n页文本内容,n为正整数;以及步骤9:判断所提取的前n页文本内容中是否包含m个以上字符,若是,则判定能对所述文件采用文本提取技术,若否,则判定不能对所述文件采用文本提取技术。所述字符可以是中文或外文字符。进一步地,n等于10,m等于10。
5、根据本发明一些实施例,所述文件可以是pdf文档。
6、进一步地,在所述步骤7中,所述格式修正操作包括对所提取的页面数据进行填充、移位、补全操作。
7、进一步地,所述图像处理技术包括光学字符识别技术(ocr),所述计算机视觉识别技术包括光学字符识别技术(ocr)。
8、本发明第二方面实施例提供一种数据处理系统,包括处理器和存储器,所述存储器存储有用于执行根据前述任一第一方面实施例所述的用于文件的数据处理方法的指令,所述处理器执行所述存储器中所存储的所述指令。
9、本发明通过将pdf文档转化为图像文件,利用图像处理技术去除页面水印,能够过滤掉干扰图像,提升图像识别精确度;对于可以采用文本提取方法的投标文件,首先利用正则提取技术先定位目标页面,再进行图像识别和版面分析,相较于对全部页面进行图像识别定位目标页面后再进行文本提取,能够大大提升投标文件数据提取效率。
技术特征:
1.一种用于文件的数据处理方法,包括:
2.根据权利要求1所述的用于文件的数据处理方法,其特征在于,所述步骤1,还包括:判断一份文件是否能够直接进行文本提取,若不能,则将所述文件的每个页面均提取为图像文件,再进入步骤5。
3.根据权利要求1所述的用于文件的数据处理方法,其特征在于,所述步骤1还包括:
4.根据权利要求1所述的用于文件的数据处理方法,其特征在于,所述文件为pdf文档。
5.根据权利要求1所述的用于文件的数据处理方法,其特征在于,所述格式修正操作包括对所提取的页面数据进行填充、移位、补全操作。
6.根据权利要求3所述的用于文件的数据处理方法,其特征在于,所述字符为中文或外文字符。
7.根据权利要求3所述的用于文件的数据处理方法,其特征在于,n等于10,m等于10。
8.根据权利要求1所述的用于文件的数据处理方法,其特征在于,所述图像处理技术包括光学字符识别技术(ocr)。
9.根据权利要求1所述的用于文件的数据处理方法,其特征在于,所述计算机视觉识别技术包括光学字符识别技术(ocr)。
10.一种数据处理系统,包括处理器和存储器,所述存储器存储有用于执行根据权利要求1-9中任一项所述的用于文件的数据处理方法的指令,所述处理器执行所述存储器中所存储的所述指令。
技术总结
本发明提供一种用于文件的数据处理方法及系统,所述用于文件的数据处理方法包括:判断一份文件是否能够直接进行文本提取,若能,则进入下一步;对所述文件进行文本提取,获取所述文件的文本内容;对所获取的文本内容利用正则匹配技术定位目标页面;将所定位的目标页面提取为图像文件;利用图像处理技术去除图像文件的页面水印;采用计算机视觉识别技术提取图像文件的页面数据,并利用版面识别技术提取页面数据的数据排布结构;以及对所提取的页面数据进行格式修正操作,完善数据排布结构。根据本发明实施例的用于文件的数据处理方法及系统,相较于单纯的文本提取法和图像提取法,能够大大提升提取效率和提取精度,并能生成结构化的页面数据。
技术研发人员:童禹臻,程常清,刘福娟,邓洁芃
受保护的技术使用者:山西金蝉电子商务有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!