一种深度伪造视频检测方法、装置、设备及介质
本发明涉及视频检测,尤其涉及一种深度伪造视频检测方法、装置、设备及介质。
背景技术:
1、视频媒体是重要信息的载体,对获取信息起着重要的作用。如利用深度学习技术生成的换脸视频近年来在网络上涌现,随着伪造视频质量的不断提高,深度伪造技术的恶意应用有着巨大的危害。
2、目前,深度伪造视频检测技术主要可分为两类:基于特定伪影的检测方法和基于深度学习的检测方法。其中,基于特定伪影的检测方法关注于视频伪造过程中产生的特定视觉伪影,这些伪影对于人类来说可能是明显或微弱的,但通过机器学习和取证分析技术却有能力将其检测出来。同时,基于深度学习的检测方法将深度伪造视频检测任务视为寻常的图像或视频分类任务,训练精心设计的深度神经网络自动提取有用的特征从而实现对真实视频和伪造视频的区分。
3、然而,以上现有的检测方法均基于单一模态即图片或视频进行检测,而现有的深度伪造视频往往伴有伪造的音频。因此,如何有效利用视频中的视觉信息和听觉信息是尚未解决的问题,虽然,有基于视听觉的深度伪造视频检测算法根据视觉模态和听觉模态之间的一致性(如视频中人物的面部情感和语音内容的情感)进行检测,而忽略了单一模态中的伪造特征。此外,当前检测算法忽略了视觉模态和听觉模态之间的关系,没有对视音频特征进行有效融合。导致现有的基于视听觉的深度伪造视频检测方法对视频进行检测时,检测的准确率不足的情况。
技术实现思路
1、本发明提一种深度伪造视频检测方法、装置、设备及介质,用以解决现有技术中无法对深度伪造视频中的伪造的音频和视频进行分别检测的缺陷,导致对深度伪造视频进行检测的准确率不足的问题。
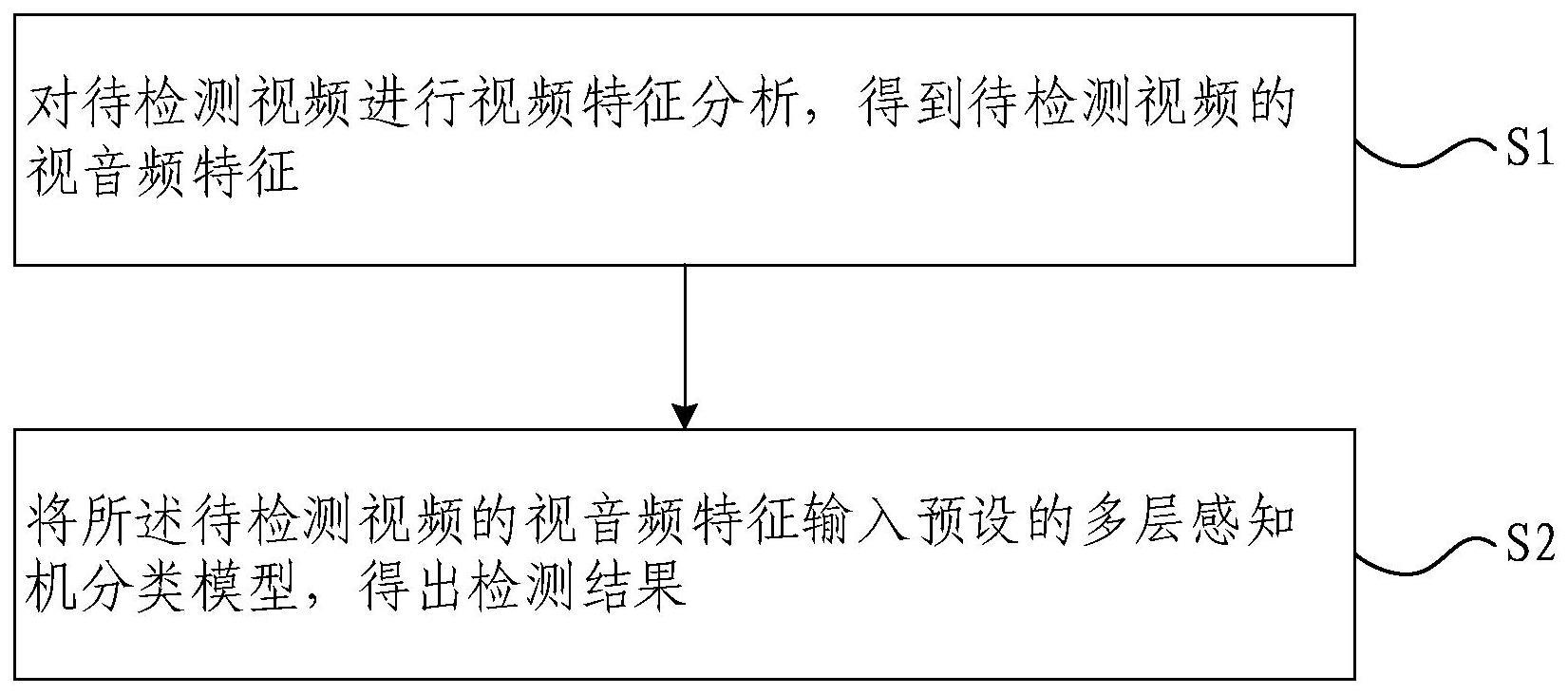
2、本发明提供一种深度伪造视频检测方法,包括:
3、对待检测视频进行视频特征分析,得到待检测视频的视音频特征;
4、将所述待检测视频的视音频特征输入预设的多层感知机分类模型,得出检测结果;
5、其中,所述视音频特征包括视觉特征和音频特征,所述预设的多层感知机分类模型以深度伪造视频的视音频特征和真实视频的视音频特征为样本,以及与深度伪造视频的视音频特征和真实视频的视音频特征各自对应的标签训练得到。
6、根据本发明提供的一种深度伪造视频检测方法深度伪造视频检测方法,所述对待检测视频进行视频特征分析,得到待检测视频的视音频特征,包括:
7、对待检测视频进行视频初步特征分析,得到视音频初步特征;
8、利用复合注意力模块,将所述视音频初步特征进行视觉和听觉的信息交互,得到视音频特征;
9、其中,所述视音频初步特征包括具有视频帧的视觉初步特征和具有梅尔倒谱系数的音频初步特征;
10、所述复合注意力模块以残差神经网络的残差模块为骨架,将位于所述残差模块中的中间卷积层替换为复合注意力层后得到。
11、根据本发明提供的一种深度伪造视频检测方法深度伪造视频检测方法,所述对待检测视频进行视频初步特征分析,获取视音频初步特征,包括:
12、提取待检测视频中的人脸区域的视频帧和梅尔倒谱系数;
13、根据所述视频帧和梅尔倒谱系数,利用残差神经网络,分别得出所述视觉初步特征和音频初步特征。
14、根据本发明提供的一种深度伪造视频检测方法深度伪造视频检测方法,所述提取待检测视频中的人脸区域的视频帧的步骤,包括:
15、利用多任务卷积神经网络模型,提取待检测视频的视频帧中每一帧中的人脸区域图片,得到所述视频帧。
16、根据本发明提供的一种深度伪造视频检测方法深度伪造视频检测方法,所述提取待检测视频中的梅尔倒谱系数的步骤,包括:
17、利用音频分析工具,对待检测视频中的音频进行分帧和加窗处理后,得到所述梅尔倒谱系数。
18、根据本发明提供的一种深度伪造视频检测方法深度伪造视频检测方法,所述利用复合注意力模块,将所述视音频初步特征进行视觉和听觉的信息交互,得到视音频特征,包括:
19、将所述视觉初步特征和音频初步特征分别输入复合注意力模块中的卷积层进行卷积;
20、沿所述复合注意力模块的通道维度,将卷积后的所述视觉初步特征和音频初步特征各自划分成自注意力特征和跨模态注意力特征;
21、将所述自注意力特征和跨模态注意力特征输入所述复合注意力模块中的复合注意力层,得到自注意力特征的自注意力权重和跨模态注意力特征的跨模态注意力权重;
22、将所述自注意力特征与自注意力权重相乘,以及跨模态注意力特征与跨模态注意力权重相乘后进行拼接,得到所述视音频特征。
23、根据本发明提供的一种深度伪造视频检测方法深度伪造视频检测方法,所述深度伪造视频的视音频特征和真实视频的视音频特征各自对应的标签与深度伪造视频的视音频特征和真实视频的视音频特征,具体对应关系包括:
24、深度伪造视频的视音频特征标签对应的深度伪造视频的视音频特征包括:真实的视觉特征与伪造的音频特征、伪造的视频特征与真实的音频特征及伪造的视频特征与伪造的音频特征;
25、真实视频的视音频特征标签对应的真实视频的视音频特征包括:真实的视觉特征与真实的音频特征。
26、本发明还提供一种深度伪造视频检测装置,包括:
27、分析模块:用于对待检测视频进行视频特征分析,得到待检测视频的视音频特征;
28、检测模块:将所述待检测视频的视音频特征输入预设的多层感知机分类模型,得出检测结果;
29、其中,所述视音频特征包括视觉特征和音频特征,所述预设的多层感知机分类模型以深度伪造视频的视音频特征和真实视频的视音频特征为样本,以及与深度伪造视频的视音频特征和真实视频的视音频特征各自对应的标签训练得到。
30、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述的深度伪造视频检测方法。
31、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述的深度伪造视频检测方法。
32、本发明提供的一种深度伪造视频检测方法、装置、设备及介质,通过深度伪造视频检测方法,对待检测视频进行视频特征分析后得到包括视觉特征和音频特征的视音频特征,通过预设的多层感知机分类模型对视觉特征和音频特征分别进行检测,通过区分真实和伪造视频特征和音频特征,实现对深度伪造视频更加有效和准确的检测。
技术特征:
1.一种深度伪造视频检测方法,其特征在于,包括:
2.根据权利要求1所述的深度伪造视频检测方法,其特征在于,
3.根据权利要求2所述的深度伪造视频检测方法,其特征在于,所述对待检测视频进行视频初步特征分析,获取视音频初步特征,包括:
4.根据权利要求3所述的深度伪造视频检测方法,其特征在于,
5.根据权利要求3所述的深度伪造视频检测方法,其特征在于,
6.根据权利要求2至5中任一项中的深度伪造视频检测方法,其特征在于,所述利用复合注意力模块,将所述视音频初步特征进行视觉和听觉的信息交互,得到视音频特征,包括:
7.根据权利要求1所述的深度伪造视频检测方法,其特征在于,
8.一种深度伪造视频检测装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7中任一项所述的深度伪造视频检测方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的深度伪造视频检测方法。
技术总结
本发明提供一种深度伪造视频检测方法、装置、设备及介质,该方法包括:对待检测视频进行视频特征分析,得到待检测视频的视音频特征;将所述待检测视频的视音频特征输入预设的多层感知机分类模型,得出检测结果;其中,所述视音频特征包括视觉特征和音频特征,所述预设的多层感知机分类模型以深度伪造视频的视音频特征和真实视频的视音频特征为样本,以及与深度伪造视频的视音频特征与真实视频的视音频特征各自对应的标签训练得到。本发明的目的是解决现有技术中无法对深度伪造视频中的伪造的音频和视频进行分别检测的缺陷,导致对深度伪造视频进行检测的准确率不足的问题。
技术研发人员:喻民,姜建国,梁亚超,刘超,李敏,黄伟庆
受保护的技术使用者:中国科学院信息工程研究所
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!