一种基于Spark技术的数据模转迁移方法、服务器及存储介质与流程
本发明属于网络数据迁移,具体涉及一种基于spark技术的数据模转迁移方法、服务器及存储介质。
背景技术:
1、在国家推动企业上云发展战略的大背景下,中国电信信息化企业对于it系统解耦上云的需求日趋迫切,业务系统解耦上云必然伴随着数据模型转换及数据迁移处理,为此能够支撑中国电信长途网络资源复杂业务场景的数据模转、数据迁移工具对骨干资源系统it上云具有重大意义,现阶段市面上的数据迁移在技术仍有许多不足,如:
2、1、反复修改代码,迁移应用不够灵活:市面上的数据迁移工具,应用到长途资源迁移场景规则变化时,往往需要修改迁移代码,重新打包发版后方可实现数据迁移功能,不是足够的灵活,遇到迁移规则不明确的时候,应对的灵活性不足。
3、2、不能支撑复杂业务,迁移局限性较高:市面上数据迁移工具仅支持新老模型之间一对一的简单数据迁移,遇到长途资源模型改造,涉及表间关系复杂的数据模型转换迁移场景时,不能够很好的应对,表现出工具的高局限性。
4、3、海量数据场景下的迁移效率不足:传统的数据迁移工具在迁移少量数据时体现高效的数据迁移性能,当遇到长途网络资源海量数据、复杂场景的数据迁移时,会存在应用相应不及时,数据迁移效率低下的问题,往往不能及时高效的完成用户所需。
技术实现思路
1、本发明的目的是为了解决背景技术中提及的问题,提供一种基于spark技术的数据模转迁移方法、服务器及存储介质,能简化数据迁移流程,且提升数据迁移效率和覆盖面。
2、为实现上述技术目的,本发明采取的技术方案为:
3、一种基于spark技术的数据模转迁移方法,包括以下步骤:
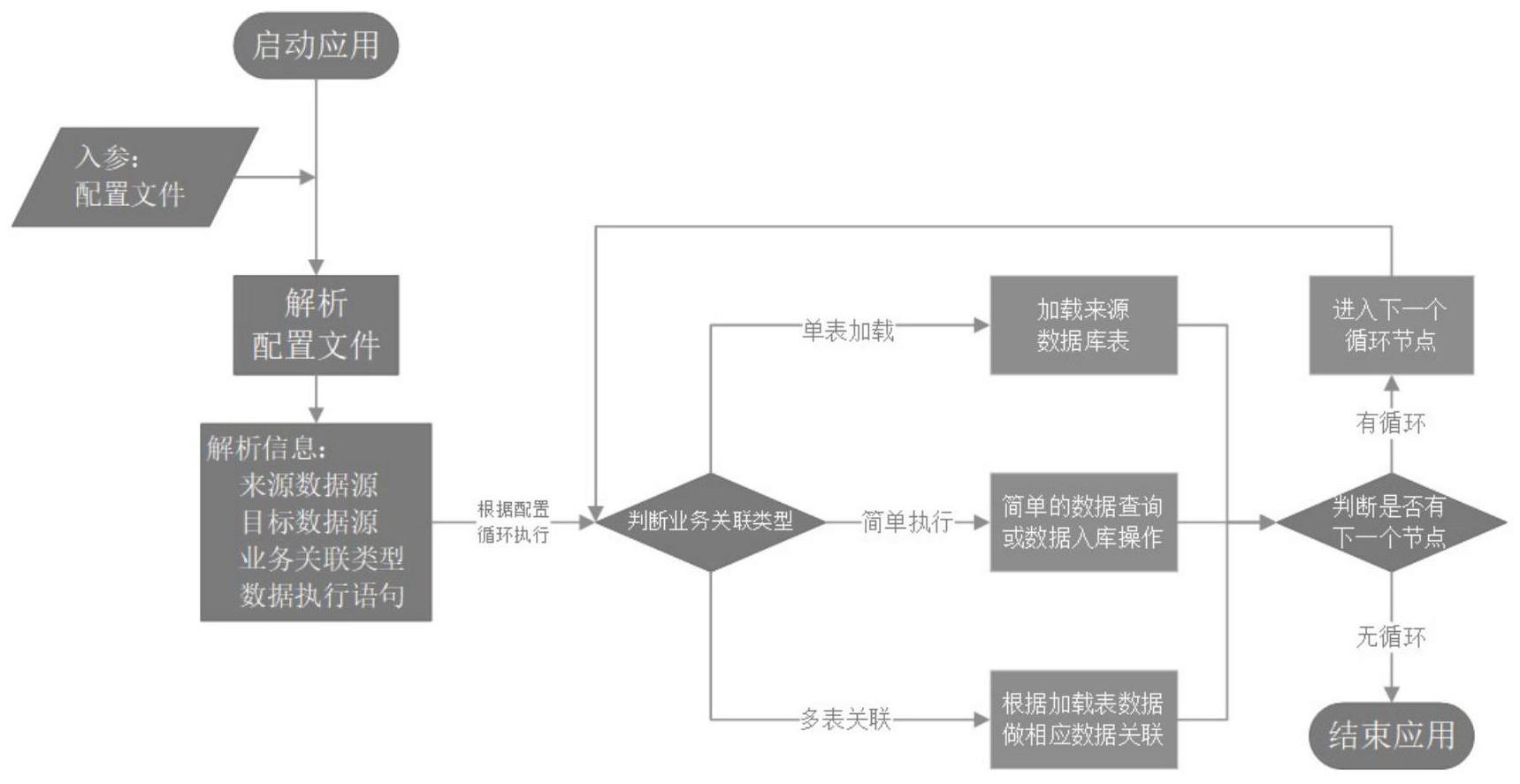
4、s1、预配置若干json文件,每个json文件包括若干节点,每个节点包含数据模转规则以及数据连接信息;按照每个节点的数据模转规则转换后的数据作为下一节点的输入数据;
5、s2、启动spark应用程序,输入参数,所述输入参数与预配置的json文件单独对应;
6、s3、根据输入参数匹配对应的json预配置文件,spark应用程序对该json配置文件进行解析;
7、s4、根据解析结果对长途网络资源数据进行模转,并根据数据连接信息,对数据进行迁移。
8、作为优选,步骤s1中json文件每个节点包含的数据模转规则包括以下三种:
9、规则一、简单转换,数据按照字段对应直接转换;
10、规则二、单表关联,数据按照单张映射关系表进行转换;
11、规则三、多表关联,数据按照多张映射关系表依次进行转换。
12、作为优选,步骤s1中json文件每个节点包含的数据连接信息,包括长途网络资源的来源数据源名称或目标数据源名称。
13、作为优选,步骤s2中输入参数为json文件的文件名,每个json文件的文件名互不重复。
14、作为优选,所述spark应用程序中预配置了所有长途网络资源的来源数据源和目标数据源的网络连接信息。
15、进一步,为了实现上述任一方法,提供一种服务器,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于:所述处理器执行所述计算机程序时实现上述任一种基于spark技术的数据模转迁移方法。
16、进一步,为了实现上述任一方法,提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于:该程序被处理器执行时实现上述任一种基于spark技术的数据模转迁移方法。
17、本发明的有益效果是:
18、1、采用预配置的json文件,实现了数据迁移逻辑即用即配,根据长途网络资源不同的转换场景,匹配相应的json文件,spark应用程序即可根据此json文件,实现对应的数据模转迁移功能。
19、2、统一的spark调用方法,一次发版终生使用,将逻辑变更放在json文件配置环节,从而避免反复修改迁移的代码程序,简化了需求变更流程,降低运营成本。
20、3、基于原生spark的运行原理,将数据提取到hdfs集群,所有关联计算任务均放在集群执行,提升长途网络资源数据模转的计算性能,提高迁移效率;。
21、4、spark应用程序预配置了所有长途网络资源的来源数据源和目的数据源的网络连接信息,从而可以支持跨数据库平台的数据模转迁移,支持sybase数据库、oracle数据库、mysql数据库、postgresdb数据库等不同数据库平台之间的跨平台数据迁移。
技术特征:
1.一种基于spark技术的数据模转迁移方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于spark技术的数据模转迁移方法,其特征在于:步骤s1中json文件每个节点包含的数据模转规则包括以下三种:
3.根据权利要求2所述的一种基于spark技术的数据模转迁移方法,其特征在于:步骤s1中json文件每个节点包含的数据连接信息,包括长途网络资源的来源数据源名称或目标数据源名称。
4.根据权利要求3所述的一种基于spark技术的数据模转迁移方法,其特征在于:步骤s2中输入参数为json文件的文件名,每个json文件的文件名互不重复。
5.根据权利要求4所述的一种基于spark技术的数据模转迁移方法,其特征在于:所述spark应用程序中预配置了所有长途网络资源的来源数据源和目标数据源的网络连接信息。
6.一种服务器,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于:所述处理器执行所述计算机程序时实现如权利要求1至5中任一项所述的基于spark技术的数据模转迁移方法。
7.一种计算机可读存储介质,其上存储有计算机程序,其特征在于:该程序被处理器执行时实现如权利要求1至5中任一项所述的基于spark技术的数据模转迁移方法。
技术总结
本发明提供一种基于Spark技术的数据模转迁移方法、服务器及存储介质,属于网络数据迁移技术领域,包括以下步骤:S1、预配置若干json文件,每个json文件包括若干节点,每个节点包含数据模转规则以及数据连接信息;按照每个节点的数据模转规则转换后的数据作为下一节点的输入数据;S2、启动Spark应用程序,输入参数,所述输入参数与预配置的json文件单独对应;S3、根据输入参数匹配对应的json预配置文件,Spark应用程序对该json配置文件进行解析;S4、根据解析结果对长途网络资源数据进行模转,并根据数据连接信息,对数据进行迁移,本发明能简化数据迁移流程,且提升数据迁移效率和覆盖面。
技术研发人员:党咏欣,张彬,郭建章,李斌,曲欣,傅博
受保护的技术使用者:中电信数智科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!