一种基于SUMO的多智能体强化学习自主开发接口
本申请属于智能交通规划决策以及强化学习算法领域,具体涉及一种基于sumo的多智能体强化学习自主开发接口。
背景技术:
1、在目前的智能交通规划与决策领域,对于车辆规划与决策的研究往往停留于单智能体层面,即在算法评估的环节只涉及个体的利益得失,这种研究可以实现个体利益的最优化,但是如果推广到交通的高交互性场景中会暴露出群体效益不足的问题,往往会形成零和博弈的局面,即某一个体的最优化意味着其他个体利益受损的情况。
2、因此,对于智能交通系统来说,研究多智能体的协同规划决策是必要的。多智能体的协同控制可以通过个体之间的合作实现更高的群体收益,例如在拥堵的路口如果添加统筹管理的交警会显著提高群体车流的通过效率。强化学习是目前主流采取的规划决策研究方法,其与基于规则的算法相比具有显著的探索性强、理解性强等优点,而且可以充分利用大数据技术的优势。但是考虑到强化学习算法在学习过程中具有明显的不稳定性,因此无法通过实车试验的方式实行,需要依托于成熟的仿真平台进行。
3、sumo是目前公开可用并广受研究者选取进行多智能体规划决策研究的智能化交通仿真平台。目前场景的构建目前主要基于flow库函数通过代码行的形式进行,这样构建的场景更容易与强化学习算法结合。但是该种方式存在明显的弊端,即基于flow库的sumo场景构建完全基于代码行的方式进行,使用者在构建场景的过程中对于场景的观察是不直接的,也是不直观的,从而导致场景构建难度较高并且容易出现程序报错。
4、sumo官方提供了一种构建场景地图的方式,通过可视化界面进行场景的自由构建,并能生成对应的场景.xml文件。但是该文件无法直接与python进行关联,与强化学习的结合也更加困难。
技术实现思路
1、本申请提出了一种基于sumo的多智能体强化学习自主开发接口,旨在解决场景构建便利性与强化学习程序实现无法同时实现的矛盾,为广大研究者提供一个便利的程序接口进行基于sumo自构建场景的强化学习相关研究。
2、为实现上述目的,本申请提供了如下方案:
3、一种基于sumo的多智能体强化学习自主开发接口,包括以下步骤:
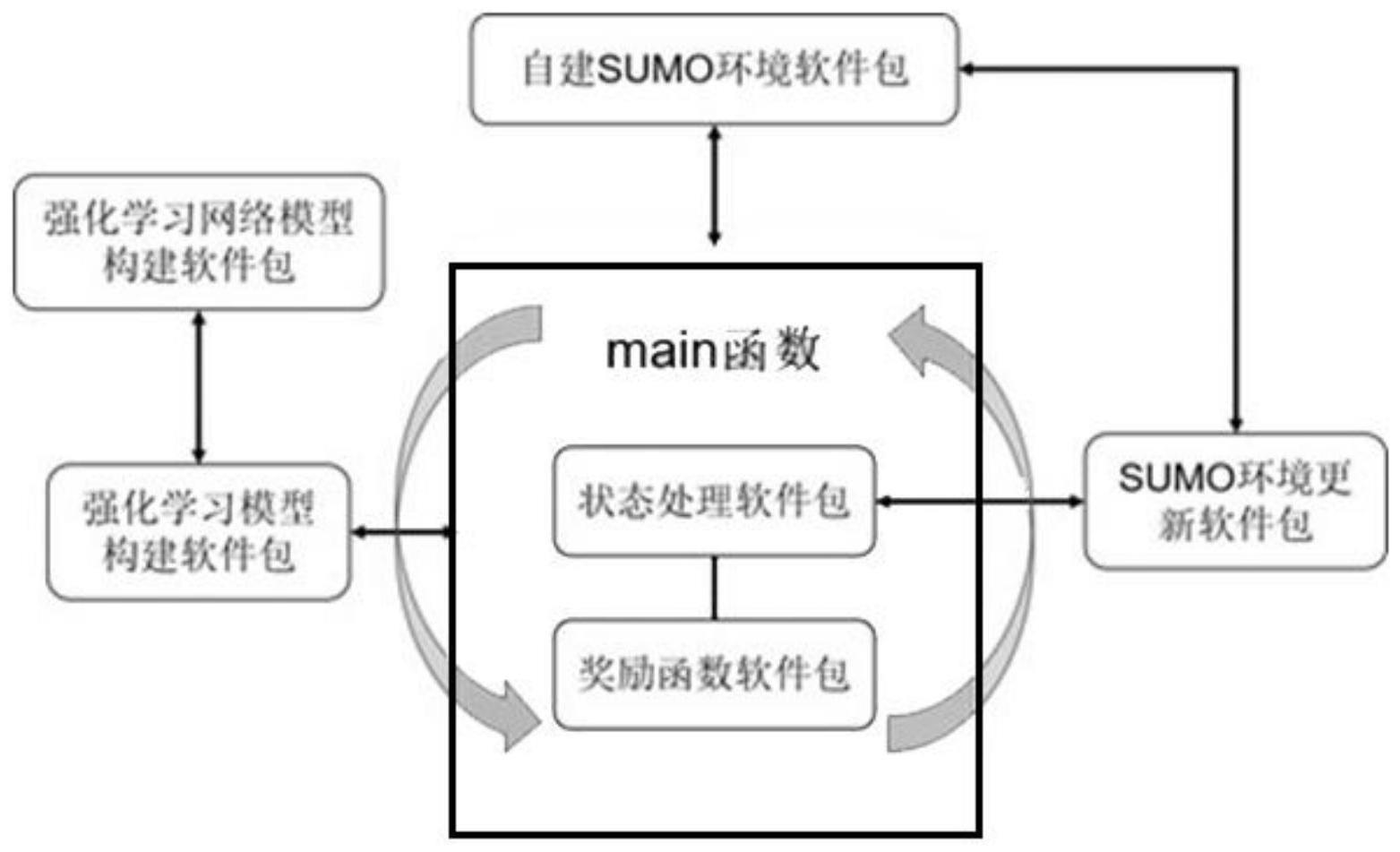
4、搭建main函数主体;
5、基于所述main函数主体,搭建强化学习网络模型构建软件包;
6、基于所述强化学习网络模型构建软件包,搭建强化学习模型构建软件包;
7、基于所述main函数主体,构建sumo环境软件包;
8、基于所述sumo环境软件包,搭建sumo环境更新软件包;
9、基于所述sumo环境更新软件包,搭建状态处理软件包;
10、基于所述main函数主体,搭建奖励函数软件包。
11、优选的,所述main函数主体主要由强化学习的主进程组成,其中包括基本超参数的设置、场景加载、强化学习模型初始化以及强化学习主循环-次循环进程。
12、优选的,所述强化学习模型初始化包括:网络以及buffer的初始化构建,为后续的学习过程提供数据承载点。
13、优选的,所述搭建强化学习网络模型构建软件包储存的是网络构建函数,可以根据实际需求对网络的每一层以及每一层的节点数量进行编辑,同时也可以定义网络层的类型。
14、优选的,所述搭建强化学习模型构建软件包包括:优化器的设定、replay_buffer的设定以及探索性算法的设定,最后定义了网络的更新方式。
15、优选的,所述构建sumo环境软件包包括:以sumo场景构建伴随生成的.xml文件为数据源,在python项目进程中形成仿真数据环境。
16、优选的,所述搭建sumo环境更新软件包包括:通过check_state函数对于sumo仿真平台内的状态进行提取,在状态提取过程中结合了sumo自带的traci库函数,将所需的所有参数进行打包、存储以及更新。
17、优选的,所述搭建状态处理软件包包括:通过get_step函数对于状态空间进行整体排布,最终形成两个矩阵量——特征矩阵以及邻接矩阵,分别表征场景内多智能体的状态信息以及相互间的关联信息。
18、优选的,所述搭建奖励函数软件包的方法包括:
19、rt=ω1·rv+ω2·rc+ω3·rs(加权计算得到总奖励,ωk为各项权重)
20、(δ为速度奖励增幅系数),计算获得速度奖励
21、(vi为当前车速,vlow为预期最低速度,vup为预期最高速度)
22、计算获得碰撞奖励
23、(μ为加速度奖励增幅系数),计算获得舒适性奖励
24、(ai为当前加速度,alow为预期最低加速度,aup为预期最高加速度)
25、其中,ωk为各项权重,δ为速度奖励增幅系数,vi为当前车速,vlow为预期最低速度,vup为预期最高速度,μ为加速度奖励增幅系数,ai为当前加速度,alow为预期最低加速度,aup为预期最高加速度。
26、本申请的有益效果为:
27、本申请为多智能体强化学习算法在智能交通场景上的应用提供了新的研究方式,为研究者自主设计场景的建立提供了可视化、便捷化的软件接口,同时保证了新场景能够与基于强化学习的算法结构相连通,本技术方案的优点以及积极效果具体如下:
28、利用现有的sumo软件构建场景过程中伴随产生的.xml文件,将其与python代码结构相结合,通过自主编写的程序对文件信息进行读取并同步到python进程内,从而同时实现可视化的场景建立及其与主程序的连通性。通过该方面的优点,研究者可以在可视化软件窗格内自由构建所需的场景内容,后续仅需要将原项目的相关文件进行替换即可实现场景的自助构建及转变。
29、为python强化学习项目提供了强化学习模型构建软件包,目前的模型基于dqn进行开发,研究者可在此基础上进行扩充,构建其他的变种算法,最后只需在函数调用环节进行替换即可实现算法的转换;
30、将强化学习的网络结构构建函数单独分离出软件包进行封装从而便于进行网络结构的编辑改进,该结构使得整个修改自适应过程更加便捷直观;
31、传统的基于flow库的相关调用函数结构较为复杂,不利于研究者进行相关修改。本申请基于sumo与python的原有traci接口,编写了相关的状态采集函数,可以对于sumo仿真内部的相关状态信息进行实时采集并生成状态矩阵可以作为网络模型的输入;
32、通过一个main函数将上述所有的模块进行集成,研究者可以对于整个强化学习过程进行整体的修改,便于进行自主研究的开展。
技术特征:
1.一种基于sumo的多智能体强化学习自主开发接口,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述main函数主体主要由强化学习的主进程组成,其中包括基本超参数的设置、场景加载、强化学习模型初始化以及强化学习主循环-次循环进程。
3.根据权利要求2所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述强化学习模型初始化包括:网络以及buffer的初始化构建,为后续的学习过程提供数据承载点。
4.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述搭建强化学习网络模型构建软件包储存的是网络构建函数,可以根据实际需求对网络的每一层以及每一层的节点数量进行编辑,同时也可以定义网络层的类型。
5.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述搭建强化学习模型构建软件包包括:优化器的设定、replay_buffer的设定以及探索性算法的设定,最后定义了网络的更新方式。
6.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述构建sumo环境软件包包括:以sumo场景构建伴随生成的.xml文件为数据源,在python项目进程中形成仿真数据环境。
7.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述搭建sumo环境更新软件包包括:通过check_state函数对于sumo仿真平台内的状态进行提取,在状态提取过程中结合了sumo自带的traci库函数,将所需的所有参数进行打包、存储以及更新。
8.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述搭建状态处理软件包包括:通过get_step函数对于状态空间进行整体排布,最终形成两个矩阵量——特征矩阵以及邻接矩阵,分别表征场景内多智能体的状态信息以及相互间的关联信息。
9.根据权利要求1所述的基于sumo的多智能体强化学习自主开发接口,其特征在于,所述搭建奖励函数软件包的方法包括:
技术总结
本申请公开了一种基于SUMO的多智能体强化学习自主开发接口,包括以下步骤:搭建main函数主体;搭建强化学习网络模型构建软件包;基于强化学习网络模型构建软件包,搭建强化学习模型构建软件包;基于main函数主体,构建SUMO环境软件包;基于SUMO环境软件包,搭建SUMO环境更新软件包;基于SUMO环境更新软件包,搭建状态处理软件包;基于main函数主体,搭建奖励函数软件包。本申请利用现有的SUMO软件构建场景过程中伴随产生的.xml文件,将其与python代码结构相结合,通过自主编写的程序对文件信息进行读取并同步到python进程内,从而同时实现可视化的场景建立及其与主程序的连通性。
技术研发人员:李雪原,杨帆,刘琦,高鑫
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!