一种基于改进YOLOv3网络的眼底图像视盘检测方法
本发明属于医学影像人工智能目标检测,尤其涉及一种基于改进yolov3网络的眼底图像视盘检测方法。
背景技术:
1、数字眼底图像在医学研究以及临床诊疗中都起到非常重要的作用,它不仅可以用于诊断眼底疾病,还能为诊疗高血压、糖尿病、中风等全身性疾病提供参考依据。利用计算机视觉技术来测量眼底图像中的形态参数,能够客观、准确、迅速地为临床诊断提供更可靠的依据。在眼底图像辅助诊断系统中,视盘的各个参数是衡量眼底健康状况和病灶的重要指标,而视盘目标检测是实现辅助诊断和其他眼底结构识别的前提和关键步骤。
2、对于传统的视盘目标检测方法主要有三种,分别是:基于亮度、形状和面积特征的视盘检测、基于血管特征的视盘检测和基于多特征融合的视盘检测。但是,这三种方法分别存在对眼底图像灰度值的差值要求高、算法的复杂度高、特征提取时间较长等问题,这就导致眼底图像视盘检测效率低。
3、最近,深度学习在图像目标检测领域已经得到了广泛应用,尤其是yolov3网络性能优异。凭借深度学习强大的自学习能力,可以解决传统视盘检测效率低的问题。但是原yolov3网络是针对多类别的目标检测,所以它并不完全适配于眼底图像的视盘目标检测。当对数字眼底图像视盘目标检测时,原yolov3的backbone网络过于冗余复杂,这就增加了训练时间,减小检测速度;原yolov3中用于特征检测的特征金字塔网络(featurepyramidnetwork,fpn)是3尺度特征融合的,当对视盘目标检测时,由于尺度较少,所以对浅层特征信息利用较少。因此特征金字塔的表征能力较低,会出现部分误检和漏检现象。
技术实现思路
1、针对上述问题,本发明提供一种基于改进yolov3网络的眼底图像视盘检测方法。
2、一种基于改进yolov3网络的眼底图像视盘检测方法,包括以下步骤:
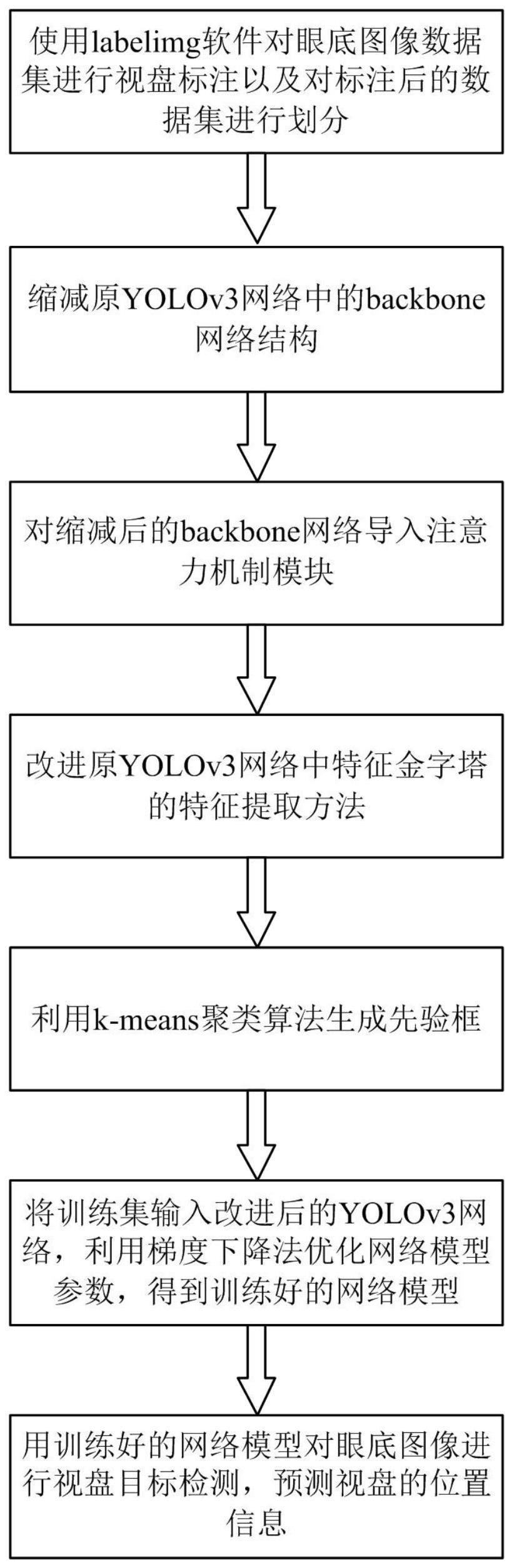
3、步骤1):获取眼底图像数据集,使用labelimg软件对眼底图像数据集进行视盘标注以及对标注后的数据集进行划分,得到训练集、验证集和测试集;
4、步骤2):缩减原yolov3网络中的backbone网络结构:将backbone网络中输出尺寸为52×52的残差块由原来的8块修改为4块;将backbone网络中输出尺寸为26×26的残差块由原来的8块修改为4块;将backbone网络中输出尺寸为13×13的残差块由原来的4块修改为2块;
5、步骤3):对缩减后的backbone网络导入注意力机制模块:在缩减后的backbone网络中的每个残差块后面连接senet模块,所述senet模块包括squeeze部分和excitation部分,squeeze部分利用globalaveragepooling2d将h×w×c的特征信息压缩为1×1×c,excitation部分将1×1×c的特征信息加入全连接层,对每个通道的重要性进行预测,得到不同通道的重要性,最后将该重要性信息作用到初始h×w×c的特征信息上;
6、步骤4):改进原yolov3网络中特征金字塔的特征提取方法:引入一个104×104的检测尺度,将3尺度的检测网络修改成4尺度的检测网络,新增的104×104的检测尺度包括四个模块:第一个模块是连接模块,它将缩减后的backbone网络中通道数为128的残差块连接到多尺度融合特征检测网络上;第二个模块是卷积模块,卷积核的数量为64,尺度为1×1;第三个模块是上采样模块,利用双线性插值算法将上一层输出尺寸52×52扩大为104×104;第四个模块是张量融合模块,上采样模块的输出作为融合通道1,backbone网络低层104×104同等尺寸大小作为融合通道2,将两者进行通道拼接;
7、步骤5):利用k-means聚类算法生成先验框,采用边界框均方误差、置信度交叉熵和类别交叉熵的总和作为损失函数;
8、步骤6):将训练集输入改进后的yolov3网络,利用梯度下降法优化网络模型参数,得到训练好的网络模型;
9、步骤7):用训练好的网络模型对眼底图像进行视盘目标检测,预测视盘的位置信息。
10、本发明由于采用了以上方法,具有以下优点:
11、1.通过对原yolov3网络中的backbone网络的缩减,减少残差块的数量,减小backbone网络复杂度,在充分提取图像特征信息的前提下,减少训练时间,增加检测速度;
12、2.导入注意力机制(squeeze-and-excitationnetworks,senet)模块,利用senet模块去学习眼底图像中重点要处理的部分,从而减少需要处理的像素数量,进而降低了检测任务的复杂度;
13、3.改进后的多尺度目标检测网络充分融合多尺度的浅层特征信息,增强了特征金字塔的表征能力,提高了视盘的目标检测精度,降低了漏检率;
14、4.相比于现有的基于深度学习的眼底视盘检测算法,本发明具有较高的检测精度和速度,能够辅助眼底医学诊断。
技术特征:
1.一种基于改进yolov3网络的眼底图像视盘检测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于改进yolov3网络的眼底图像视盘检测方法,其特征在于,在步骤5)中利用k-means聚类算法生成先验框时,根据k-means聚类算法选取合适的重叠度分数,再根据重叠度分数和先验框的关系生成12个先验框,分别为(152,156),(168,181),(193,170),(194,200),(210,249),(234,226),(245,272),(278,269),(282,222),(308,309),(336,263),(358,356)。
3.根据权利要求1所述的一种基于改进yolov3网络的眼底图像视盘检测方法,其特征在于,步骤6)包括以下步骤:
技术总结
本发明提出一种基于改进YOLOv3网络的眼底图像视盘检测方法,属于医学影像人工智能目标检测技术领域,包括以下步骤:缩减backbone网络并在缩减后的backbone网络中的每个残差块后面连接SENet模块;引入一个104×104的检测尺度,将3尺度的检测网络修改成4尺度的检测网络;利用k‑means聚类算法生成先验框,采用边界框均方误差、置信度交叉熵和类别交叉熵的总和作为损失函数;利用梯度下降法优化网络模型参数,得到训练好的网络模型;用训练好的网络模型对眼底图像进行视盘目标检测,预测视盘的位置信息。本发明具有较高的检测精度和速度,能够辅助眼底医学诊断。
技术研发人员:徐伟,陶淑苹,刘帅,李宗轩
受保护的技术使用者:中国科学院长春光学精密机械与物理研究所
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!