一种基于抽象语法树的软件缺陷预测方法
本发明涉及深度学习领域和软件缺陷预测领域,可以帮助软件工程师和测试人员合理分配资源来定位错误,快速缩小软件代码库中最有可能存在缺陷的部分。
背景技术:
1、随着软件系统在社会各个领域扮演着重要的角色,软件产生的缺陷对商业和人们的生活产生了重大的影响。然而,由于软件代码库在规模和复杂性上的显著增长,识别软件代码中的缺陷变得越来越困难。传统软件缺陷预测是以手工获取软件度量特征的基础进行分类学习,如机器学习技术已被广泛用于建立缺陷预测模型,这些技术从软件代码中提取出许多特征,并将它们输入到常见的分类器中,比较有代表性的如svm支持向量机、随机森林、朴素贝叶斯和逻辑回归等。但是传统软件缺陷预测方法使用静态代码度量作为特征,这些特性并不能真正反映代码的语法和语义,这无疑会对缺陷预测造成影响。
2、随着深度学习的发展,人们发现它在捕获源代码的语法和语义特征方面表现的很好。前人大量的实验已经证明,将代码转换成抽象语法树的形式能够很好的保留代码的结构,目前主流的软件缺陷预测模型都有这一步,该类方法的关键思想是将源代码的抽象语法树中提取的token向量用来生成源代码的语义特征表示,并利用生成的特征建立更精确的分类模型。然而要获取更精准的语义特征以使模型更准确,还需要一种方法来更好的利用抽象语法树中定义良好的结构信息和丰富的语义。
技术实现思路
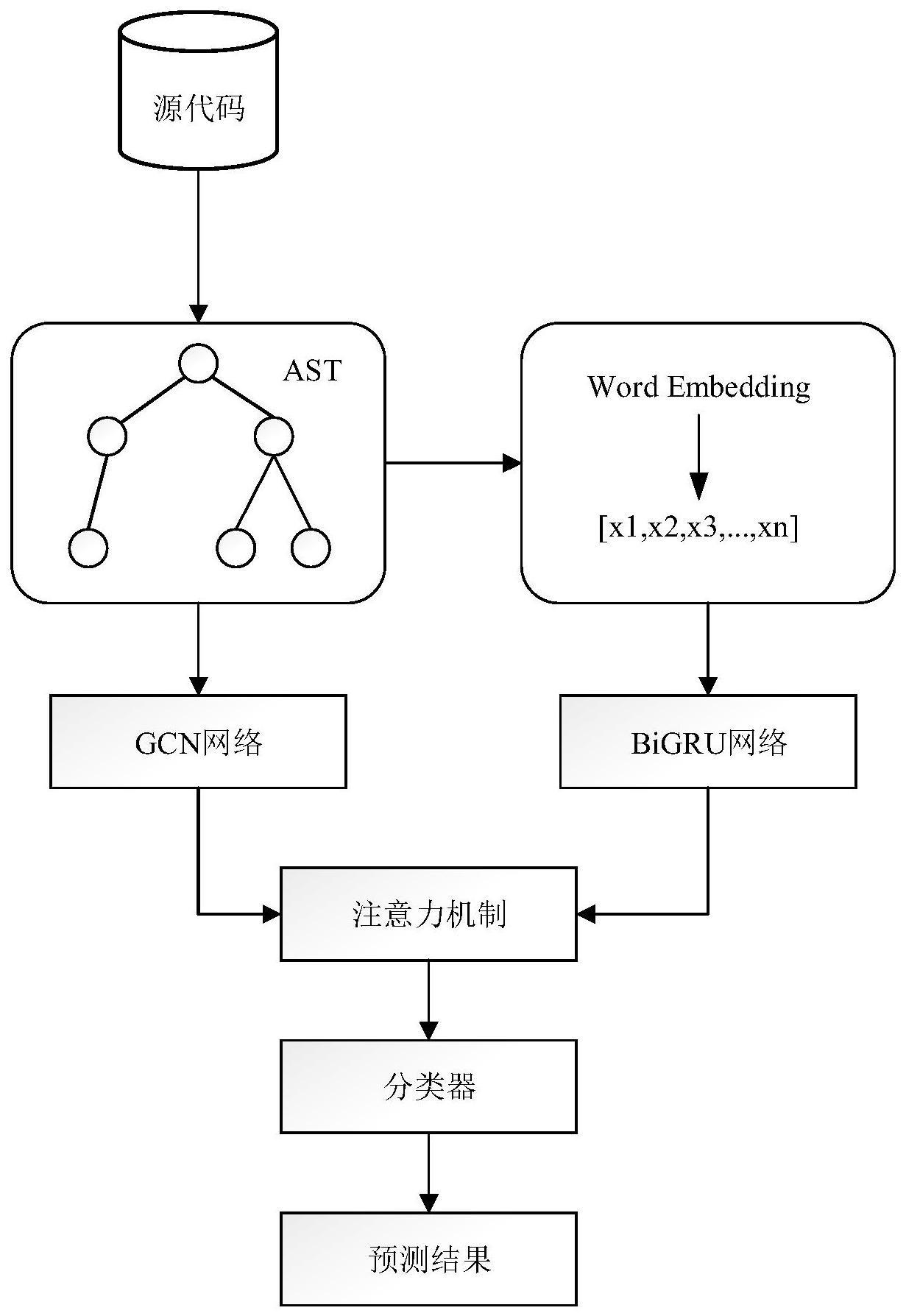
1、本发明基于抽象语法树的表现形式,提供一种基于gcn网络和双向gru网络结合的方法获取源代码的语义特征,并加入了注意力机制来提高模型的性能。
2、本发明提供的技术方案如下:
3、一种基于抽象语法树的软件缺陷预测方法,包括如下步骤:
4、1)解析源代码为抽象语法树;
5、2)使用深度遍历算法将抽象语法树转换成文本向量,如果抽象语法树的大小为n,则获得一个关于y的文本向量:
6、y=[y1 ,y2 ,y3,...,yn ] (1)
7、3)为抽象语法树的每个代码片段生成节点关系图,ast上的每个节点都有自己的特征,设这些节点的特征组成一个n×d维的矩阵,然后各个节点间的关系也会形成一个n×n维的邻接矩阵a:
8、
9、图用g=(s,e)表示,其中s中元素为顶点,e中元素为边;
10、4)词嵌入过程。使用gensim库将文本向量转换为可以输入gru的数字向量,建立一个映射字典表,将向量中的每个文本元素链接到一个整数,这些整数充当标记,唯一地标识ast中的每个文本元素。通过这种方法,可以将节点序列中的每个元素都被替换成数字符号,并且保持它们的顺序不变。通过步骤(2)给定的文本向量,最终可以得到相应的嵌入矩阵x。
11、x=[x1,x2,x3,...xn] (3)
12、对于数据中的类不平衡问题,使用随机过采样-smote方法来处理。
13、5)将步骤3)中得到的数据输入图卷积网络中,在gcn网络中,节点关系图和相对应的节点作为其输入,对于gcn网络中的每个节点,需要考虑其所有邻居以及自身所包含的特征信息。它的层与层之间的传播方式是:
14、
15、其中hl为gcn网络每一层生成的隐藏表示,i为单位矩阵,是的度矩阵,σ为非线性激活函数,wl是第l层神经网络的权重矩阵,bl为偏置矩阵,通过层与层之间的传播最后得到gcn网络的输出表示
16、6)是bigru网络每一层生成的隐藏表示,它使用步骤4)中得到的嵌入矩阵x作为输入:
17、
18、bigru可以表示为两个单向的gru网络,bigru()函数是对输入的嵌入矩阵x的非线性变换,将其编码成bigru网络的输出表示hc。
19、7)获得了gcn层的输出表示和bigru网络的输出表示hc,然后使用注意力机制来聚合获取的两种特征,从源代码中捕获着重的情感特征:
20、
21、
22、公式(6)为计算注意力系数,||表示向量拼接操作,旨在将获取的两种特征进行拼接,w表示权重矩阵。其中是隐藏状态的第i个节点,是图隐藏表示的第j个节点,a为非线性激活函数leakyrelu。
23、因此,经过对数据的一系列处理,最终可以得到源代码的表达形式为:
24、
25、8)将源代码的表达形式r输入分类器,使用逻辑回归算法得到软件缺陷预测,即逻辑回归是一种预测二元结果的算法,得到的结果为negative和positive两种,在软件缺陷预测中应用非常广泛。它使用交叉熵作为损失函数,计算每个类别对应的两个标签的概率,对应类别的预测标签即为有高概率得分的标签。
26、本发明的技术效果是:
27、本发明考虑到使用传统机器学习方法来预测软件缺陷问题的不足,难以获取代码真正的语义和语法特征,使用了抽象语法树方法来获取代码特征。本发明以图卷积网络(gcn)和双向gru网络为核心模型,将抽象语法树转换为向量节点后,利用gcn通过整合每个节点自身及其邻居节点包含的特征信息来获取本节点的隐藏表示。利用bigru将通过词嵌入获取的数字向量转换成节点的隐藏表示,以此来捕捉序列之间的关系特征,解决了rnn不能长期记忆和反向传播的梯度问题。同时将两种网络得到的特征进行聚合,使用了注意力机制来为不同特征赋予不同的权重,从而体现不同特征的重要性。并在此基础上对得到的源代码特征进行计算,预测其缺陷率。
技术特征:
1.一种基于抽象语法树的软件缺陷预测方法,其特征在于,包括如下步骤:
2.如权利要求1所述的基于抽象语法树的软件缺陷预测方法,其特征在于,步骤1)中使用python的javalang库解析源代码为抽象语法树。
3.如权利要求1所述的基于抽象语法树的软件缺陷预测方法,其特征在于,步骤4)中使用gensim库将文本向量转换为可以输入gru的数字向量。
技术总结
本发明提供了一种基于抽象语法树的软件缺陷预测方法,属于深度学习领域和软件缺陷预测领域。本发明通过将源代码转换为抽象语法树的形式,保留其定义良好的结构信息与语义信息,使用图卷积网络(GCN)来学习语法树结构中的节点的特征和网络结构的信息;使用词嵌入将抽象语法树的节点序列转换成文本向量,然后使用BiGRU网络来学习上下文直接的语义关系以提取语义特征,最后将得到的两类特征基于注意力机制进行聚合得到代码的特征,将其输入分类器中以预测缺陷率。本发明充分利用了代码的语义和语法特征使用注意力机制为不同变量赋予不同的权重,减少了噪声干扰,提高了软件缺陷预测的准确率。
技术研发人员:鲁书勉,刘一非,刘宏志
受保护的技术使用者:北京工商大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!