基于深度学习自编码的脑部疾病MRI影像的多病灶识别方法
本发明涉及人工智能结合临床医学影像处理领域,具体是一种基于深度学习自编码的脑部疾病mri影像的多病灶识别方法。
背景技术:
1、脑部核磁共振成像(mri)是脑部疾病诊断的重要影像学依据,包括t1wi、t2wi、dwi、flair、swi等序列。目前大部分脑部疾病的临床影像诊断仍主要依赖于医师的主观判断,不但难以确保客观性和准确性,而且诊断时间过久、过程冗长繁杂的问题也急需解决。
2、深度学习(deep learning)是机器学习(machine learning)领域基于人工神经网络的表征学习方法的扩展,具有高准确率、高效率、可移植性等优势。并已应用于例如视网膜血管底图像、头颈部血管造影和心脏ct血管造影图等多个医学领域的图像分割任务,在一些公开数据集上取得了和专业医生相匹配甚至更优异的性能。
3、用于病灶识别的深度学习方法往往依赖于医生的手动标注作为模型训练的基准。医学影像数据集获取代价高、处理难度大,带有医生标注的数据稀缺的问题普遍存在,限制了有监督的深度学习方法的发展。针对医学图像数据的稀缺性,基于迁移学习的技术得到广泛应用,大多数已有工作使用imagenet等大规模公开数据集预训练的模型再进行微调,但也存在预训练模型参数量过大、结构难以修改、性能提升有限等问题。此外,当前已有的基于深度学习的脑部影像诊断方法大多数使用卷积神经网络只针对单一病灶进行检测和分割,不能有效学习和判断多种病灶的不同特征,难以提高多病灶脑部疾病的诊断准确率。
技术实现思路
1、本发明的目的在于针对上述现有技术的缺陷,提出了一种基于深度学习的脑部疾病mri影像的多病灶识别方法。通过采集真实数据集并进行预处理,提高深度学习方法的准确性;针对脑部mri数据量少的特点,引入自编码网络对原始mri图像进行无监督学习,减少整体方法对医生人工标注的数据的需求量。
2、本发明的技术解决方案如下:
3、一种基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特点在于,该方法包括:
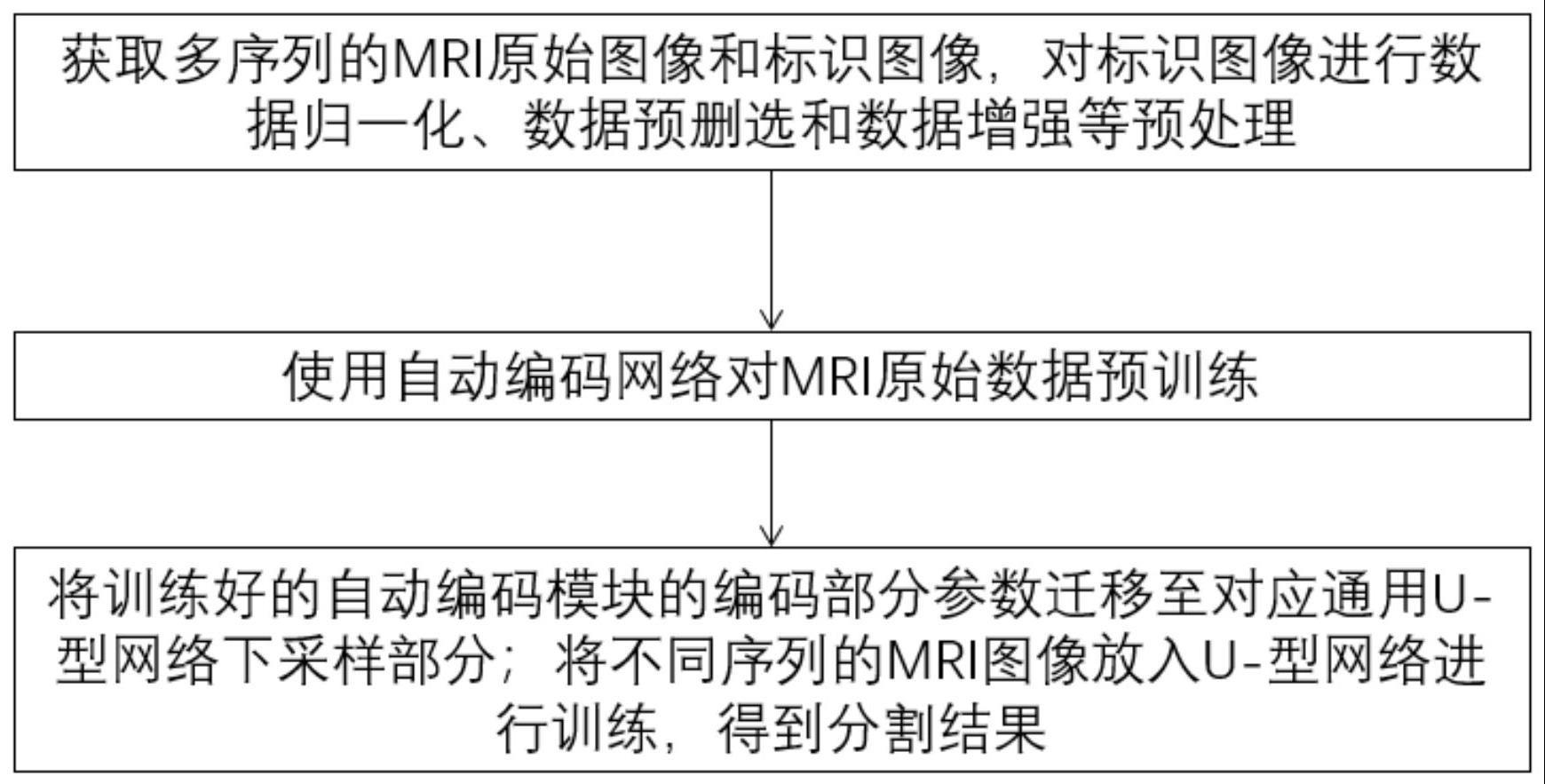
4、步骤s1.获取患者的mri原始图像和对应带医生标注的mri病灶标识图像,并对所述的mri病灶标识图像进行预处理;
5、步骤s2.采用自编码网络对所述的多序列mri原始图像进行预训练;
6、步骤s3.将预训练后的mri原始图像和预处理后的mri病灶标识图像输入u型网络进行训练分割处理,从而获取病灶分割结果。
7、进一步,所述步骤s1.获取患者的mri原始图像和对应带医生标注的mri病灶标识图像,具体是:利用核磁共振机获得患者的mri原始图像;利用itk-snap进行医生标注,获得对应的mri病灶标识图像。
8、进一步,所述步骤s1.对所述的mri病灶标识图像进行预处理,具体包括:
9、图像分割处理,利用阈值算法确定所述的mri病灶标识图像的脑部区域,并将mri原始图像转变为分割病灶区域、脑部区域和背景区域的mri灰度图像,其中,所述的病灶区域根据不同病灶按不同索引index值编号;
10、数据预删选处理,根据预删选和累加所述的mri灰度图像中脑部区域的像素数量的比例,确定其脑部区域的大小,并根据病灶特征,通过阈值删除造成歧义的mri灰度图像和与之对应的原始图像,得到预删选后的mri原始图像;
11、数据增强处理,分别对所述预删选后的mri原始图像和mri灰度图像进行增强变换,使所述的mri原始图像和mri灰度图像增加至原有的五倍以上。
12、进一步,所述步骤s2采用自编码网络对所述的mri原始图像进行预训练,具体包括:
13、s2.1采用编码函数将所述的mri原始图像维度特征值进行下采样,得到降维特征值;
14、s2.2采用解码函数将所述的降维特征值进行上采样,得到与所述的mri原始图像维度值相等的维度特征值;
15、s2.3将mri原始图像作为自编码网络的输入端和输出端放入网络中,经s2.1与s2.2后得到预测灰度值与实际灰度值的均方差值,通过反向传播逐步减少均方差值,当均方差值小于预设均方差阈值2*10-4时停止训练,作为对mri原始图像的预训练自编码模型。
16、进一步,所述的损失函数为均分误差,具体公式为:
17、
18、其中,n代表原始图像与预测图像的像素个数,xi代表实际灰度值;yi代表预测灰度值。
19、进一步,所述步骤s3.将预训练后的mri原始图像和预处理后的mri病灶标识图像输入u型网络进行训练分割处理,从而获取病灶分割结果,具体包括:
20、采用n个编码函数将所属的mri原始图像维度特征值进行下采样,编码函数的超参数由自编码网络中同层的超参数迁移而来,得到降维特征值;
21、采用残差函数作为中间模块,连接编码函数和解码函数,得到中间模块的特征值;
22、采用选择函数将得到的降维特征值根据输入mri原始图像的序列不同,开放不同的解码函数通道,同时锁住其余解码函数通道,以此训练时的损失函数只会受到开放的解码函数通道的影响;
23、采用解码函数将所述的降维特征值进行上采样,得到与所述的mri原始图像维度值相等的维度特征值;
24、采用输出函数,将所述的与mri原始图像维度值相等的维度特征值判定为不同的index值,得到预测的mri分割结果;
25、将mri原始图像与预处理后mri病灶标识图像作为通用u型网络的输入端和输出端放入网络中,经上述步骤后得到预测标识图像与实际标识图像的损失函数数值,通过反向传播逐步减少该损失函数;迭代上述过程50次,迭代收敛,取损失函数最小时的权重值作为训练好的分割网络,完成对多序列mri的图像分割训练,得到脑部病灶的分割预测图。
26、进一步,所述的损失函数为1-dice loss与focal loss之和,具体公式为:
27、
28、其中,tp代表真阳率、fp代表假阳率、fn代表假阴率,gt代表事实值、pr代表预测值、α代表权重参数、γ代表聚焦参数。
29、与现有技术相比,本发明的有益效果是:
30、1.、针对脑部mri图像多病灶、少数据量的特点设计与训练方法,提高了脑部mri图像的使用效率。
31、2.、针对脑部mri图像数据不足的问题,在正式模型训练前使用无监督自编码网络预训练,并使用迁移学习将训练好的编码模块架构及相关超参数迁移至u-型网络中,加快了网络拟合速率,提高了识别准确率。
技术特征:
1.一种基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,该方法包括:
2.根据权利要求1所述的基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,所述步骤s1.获取患者的mri原始图像和对应带医生标注的mri病灶标识图像,具体是:利用核磁共振机获得患者的mri原始图像;利用itk-snap进行医生标注,获得对应的mri病灶标识图像。
3.根据权利要求1所述的基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,所述步骤s1.对所述的mri病灶标识图像进行预处理,具体包括:
4.根据权利要求1所述的基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,所述步骤s2采用自编码网络对所述的mri原始图像进行预训练,具体包括:
5.根据权利要求4所述的基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,所述的损失函数为均分误差,具体公式为:
6.根据权利要求1所述的基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,所述步骤s3.将预训练后的mri原始图像和预处理后的mri病灶标识图像输入u型网络进行训练分割处理,从而获取病灶分割结果,具体包括:
7.根据权利要求6所述的基于深度学习自编码的脑部疾病mri影像的多病灶识别方法,其特征在于,所述的损失函数为1-dice loss与focal loss之和,具体公式为:
技术总结
一种基于深度学习自编码的脑部疾病MRI影像的多病灶识别方法,包括:对脑部磁共振成像数据进行预处理;使用自编码网络预训练,对MRI数据进行特征提取;将自编码网络编码器的参数迁移至U‑型深度学习网络,进一步学习图像的特征,输出病灶的识别和预测结果。本发明将深度学习算法引入到脑部疾病MRI诊断中,通过迁移学习方法将使用真实数据训练的无监督自动编码器的部分参数迁移至通用U‑型深度学习网络中,降低了对标记数据的需求量并提高了训练效率;本发明较传统单一U‑型网络可进一步提升模型的性能指标,实现更精准的病灶识别,对临床医学领域快速诊断有重大意义。
技术研发人员:邹卫文,赵麾宇,靳渌渊
受保护的技术使用者:上海交通大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!