通过对齐词义库来衔接词语和定义之间的语义的制作方法
本公开的实施例指向自然语言处理(nlp)领域,更具体地,涉及词义消歧(wsd),wsd旨在在词语在句子或表述中使用的语境中自动地理解词语的确切含义。
背景技术:
1、人类语言在某种程度上是模棱两可的,原因是词语在不同的语境中可具有多种含义。wsd旨在在词语使用的语境(通常是语境句子)中自动地识别词语的确切含义。在词语的语境中识别词语的正确含义对于许多下游任务(例如机器翻译、信息提取和自然语言处理中的其它任务)而言是必不可少的。
2、本公开所解决的问题之一是由于针对罕见词义有限的训练数据,导致监督模型在尝试预测那些罕见词义的正确含义时所面临的问题。由于大多数模型基于根据预定义的词义库进行训练来预测词语的含义,因此在预测词语的含义时,通常会忽略不出现或不是非常频繁地出现的罕见词。
3、许多方法包括使用特定于任务的数据集上的大量文本数据对语言模型进行微调。然而,这些方法往往限制已训练模型的适用性,并导致重大问题。首先,由于训练数据中的样本不足,导致在预测罕见和零样本词义时模型的性能显著下降。另一个问题是模型的特定于任务的微调通常使模型依赖于词库,其中模型只能从一个预定词义库(例如wordnet)中选择最佳定义,而不能更一般地选择。
技术实现思路
1、本公开解决一个或多个技术问题。为了解决正确地预测罕见词义的含义的问题,即数据稀疏性问题,并将模型泛化为独立于一个预定库,本公开提出一种注释对齐算法,该注释对齐算法将来自不同词义库的具有相同含义的注释对齐,以收集丰富的词汇知识。对模型进行训练或微调以使用这些已对齐库识别语境中的词语及其一个注释之间的语义等价,解决了数据稀疏性和泛化问题,改善了对频繁词义和罕见词义的预测。
2、本公开的实施例提供一种用于预测词义的方法和装置。
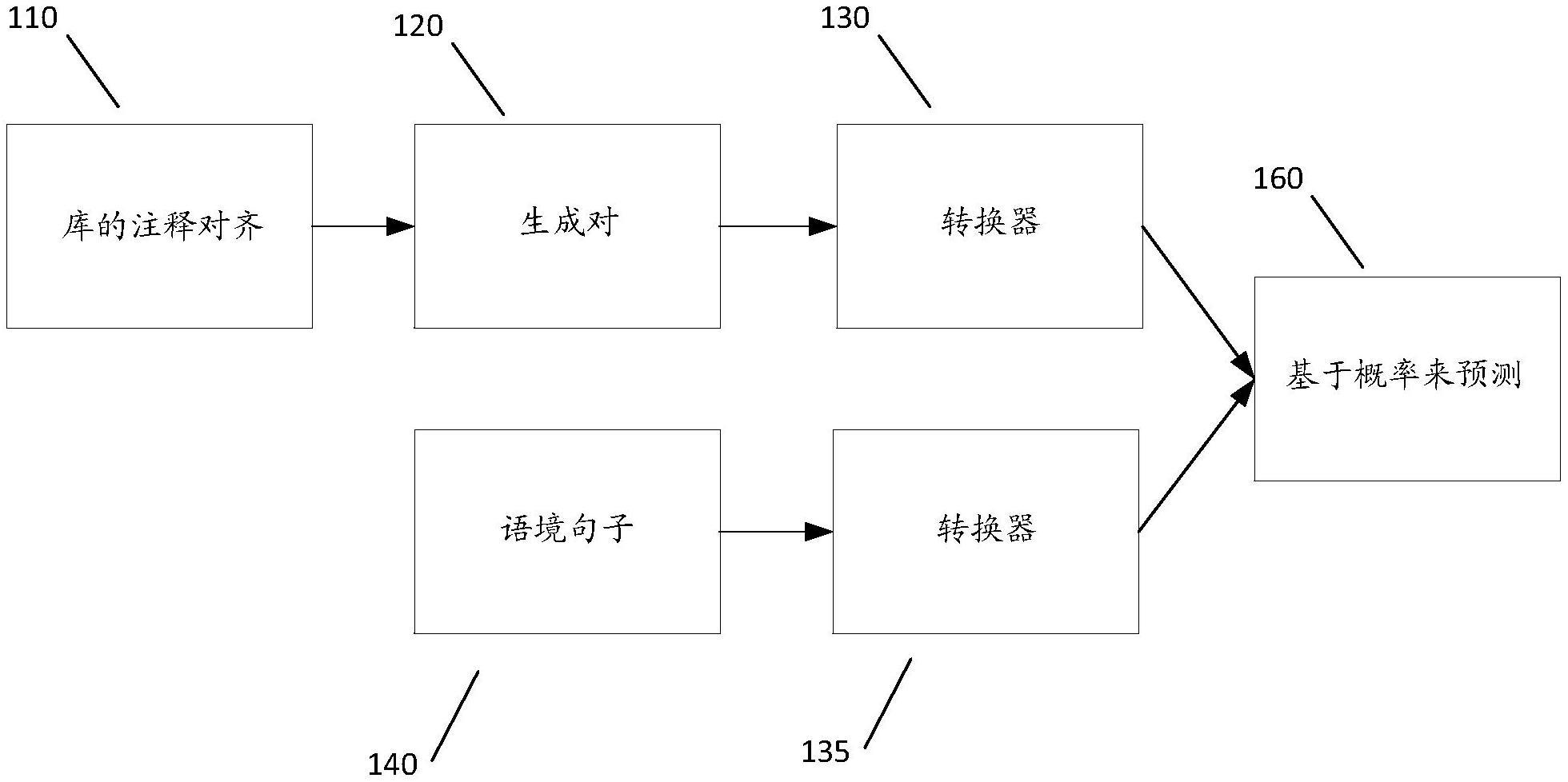
3、根据本公开的一个方面,一种用于预测词义的方法包括:生成一个或多个对齐库,其中,一个或多个对齐库使用一个或多个词义库而生成;获得语境句子中的词语;使用语义等价识别器模型确定一个或多个语义等价分数,一个或多个语义等价分数指示语境句子中的词语与一个或多个对齐库中的一个或多个关联注释中的每个关联注释之间的语义相似度;以及基于所确定的一个或多个语义等价分数,预测语境句子中的词语的正确含义。
4、根据本公开的一方面,生成一个或多个对齐库包括:从第一词义库中收集注释;从第二词义库中收集注释;确定第一词义库和第二词义库之间的最佳匹配,其中,确定第一词义库和第二词义库之间的最佳匹配包括:对于第一词义库和第二词义库中的每个常用词,确定来自第一词义库的每个注释与来自第二词义库的一个或多个关联注释中的每个关联注释之间的句子文本相似度分数;和确定匹配函数以将来自第一词义库的每个注释映射到来自第二词义库的一个或多个关联注释中的每个关联注释,其中,匹配函数配置成使来自第一词义库的每个注释与来自第二词义库的一个或多个关联注释中的每个关联注释之间的句子文本相似度分数之和最大化。
5、根据本公开的一方面,生成一个或多个对齐库进一步包括:基于确定来自第一词义库的注释与来自第二词义库的一个或多个关联注释中的每个关联注释之间的句子文本相似度分数大于阈值,通过将来自第一词义库的注释与来自第二词义库的一个或多个关联注释中的每个关联注释进行配对而生成正注释对;以及基于确定来自第一词义库的注释与来自第二词义库的一个或多个关联注释中的每个关联注释之间的句子文本相似度分数小于阈值,通过将来自第一词义库的注释与来自第二词义库的一个或多个关联注释中的每个关联注释进行配对而生成负注释对。
6、根据本公开的一方面,确定来自第一词义库的每个注释与来自第二词义库的一个或多个关联注释中的每个关联注释之间的句子文本相似度分数包括:基于二次预训练模型确定一个或多个句子嵌入;以及基于一个或多个句子嵌入,确定来自第一词义库的每个注释与来自第二词义库的一个或多个关联注释中的每个关联注释之间的余弦相似度。
7、根据本公开的一方面,二次预训练模型包括来自转换器的句子双向编码器表示(sbert)模型。
8、根据本公开的一方面,使用语义等价识别器模型确定一个或多个语义等价分数(一个或多个语义等价分数指示语境句子中的词语与一个或多个对齐库中的一个或多个关联注释中的每个关联注释之间的语义相似度)包括:将语境句子中的词语输入到语义等价识别器模型中;将一个或多个对齐库输入到语义等价识别器模型中;识别来自一个或多个对齐库的、与语境句子中的词语相关联的一个或多个注释;以及将经训练的注释分类器应用于所识别的一个或多个注释,以生成所识别的一个或多个注释中的每个注释的概率分数。
9、根据本公开的一方面,使用增强训练数据来训练经训练的注释分类器,其中,增强训练数据是一个或多个对齐库和与特定词义库相关联的内置训练数据的组合。
10、根据本公开的一方面,使用一个或多个对齐库来训练经训练的注释分类器,且在新的领域中,使用与特定词义库相关联的内置训练数据来微调经训练的注释分类器。
11、根据本公开的一方面,一个或多个词义库是用于语言的词汇数据集。
12、根据本公开的一方面,基于所确定的一个或多个语义等价分数来预测语境句子中的词语的正确含义包括:选择与最高语义等价分数相关联的结果注释。
技术特征:
1.一种用于预测词义的方法,所述方法包括:
2.根据权利要求1所述的方法,其中,所述生成一个或多个对齐库包括:
3.根据权利要求2所述的方法,其中,所述确定来自所述第一词义库的每个注释与来自所述第二词义库的一个或多个关联注释中的每个关联注释之间的句子文本相似度分数包括:
4.根据权利要求3所述的方法,其中,所述二次预训练模型包括来自转换器的句子双向编码器表示(sbert)模型。
5.根据权利要求1所述的方法,其中,所述使用语义等价识别器模型来确定一个或多个语义等价分数,所述一个或多个语义等价分数指示所述语境句子中的所述词语与所述一个或多个对齐库中的一个或多个关联注释中的每个关联注释之间的语义相似度包括:
6.根据权利要求5所述的方法,其中,使用增强训练数据来训练所述经训练的注释分类器,其中,所述增强训练数据是所述一个或多个对齐库和与特定词义库相关联的内置训练数据的组合。
7.根据权利要求5所述的方法,其中,使用所述一个或多个对齐库来训练所述经训练的注释分类器,且在新的领域中,使用与特定词义库相关联的内置训练数据来微调所述经训练的注释分类器。
8.根据权利要求1所述的方法,其中,所述一个或多个词义库是用于一种语言的词汇数据集。
9.根据权利要求1所述的方法,其中,所述基于所确定的一个或多个语义等价分数来预测语境句子中的所述词语的正确含义包括:选择与最高语义等价分数相关联的结果注释。
10.一种用于预测词义的装置,所述装置包括:
11.根据权利要求10所述的装置,其中,所述第一生成代码还包括:
12.根据权利要求11所述的装置,其中,所述第三确定代码还包括:
13.根据权利要求10所述的装置,其中,所述第一确定代码还包括:
14.根据权利要求13所述的装置,其中,使用增强训练数据来训练所述经训练的注释分类器,其中,所述增强训练数据是所述一个或多个对齐库和与特定词义库相关联的内置训练数据的组合。
15.根据权利要求13所述的装置,其中,使用所述一个或多个对齐库来训练所述经训练的注释分类器,且在新的领域中,使用与特定词义库相关联的内置训练数据来微调所述经训练的注释分类器。
16.根据权利要求10所述的装置,其中,所述一个或多个词义库是用于一种语言的词汇数据集。
17.根据权利要求10所述的装置,其中,所述第一预测代码还包括第一选择代码,配置成使得所述至少一个处理器选择与最高语义等价分数相关联的结果注释。
18.一种存储有指令的非暂时性计算机可读介质,所述指令包括一个或多个指令,其中,所述一个或多个指令当由用于预测词义的装置的一个或多个处理器执行时,使得所述一个或多个处理器:
19.根据权利要求18所述的非暂时性计算机可读介质,其中,所述生成一个或多个对齐库还包括使得所述一个或多个处理器:
20.根据权利要求18所述的非暂时性计算机可读介质,其中,所述使用语义等价识别器模型来确定一个或多个语义等价分数,所述一个或多个语义等价分数指示所述语境句子中的所述词语与所述一个或多个对齐库中的一个或多个关联注释中的每个关联注释之间的语义相似度使得所述一个或多个处理器:
技术总结
包括一种方法和装置,方法和装置包括计算机代码,计算机代码被配置成使得一个或多个处理器执行:生成一个或多个对齐库,其中,一个或多个对齐库使用一个或多个词义库而生成;获得语境句子中的词语;使用语义等价识别器模型确定一个或多个语义等价分数,一个或多个语义等价分数指示语境句子中的词语与一个或多个对齐库中的一个或多个关联注释中的每个关联注释之间的语义相似度;以及基于所确定的一个或多个语义等价分数,预测语境句子中的词语的正确含义。
技术研发人员:姚文林,潘小满,金立峰,陈建树,于典,俞栋
受保护的技术使用者:腾讯美国有限责任公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!