针对大规模数据的可解释的机器学习的制作方法
背景技术:
1、近年来,由于深度学习和其他复杂模型的引入,人工智能(ai),特别是机器学习,在推理任务上经历了显著的性能提升。然而,尽管这些模型性能更高,但并没有得到广泛使用,因为它们往往难以解释。机器生成的决策或“预测”的可解释性对于透明度和问责制非常重要—这是所谓的“负责任ai”的一个方面。因此,许多依赖机器学习完成日常任务的行业,特别是医疗保健、银行和人力资源等高度监管的行业,都无法利用最近以可解释性为代价的性能进步。已经提出了各种方法来解决这一限制,并提供对复杂机器学习模型预测的解释;其中包括局部可解释模型无关解释(lime)和shapley可加性解释(shap)。这些算法通常依赖于理解作为机器学习模型输入数据点提供的给定观察的邻居,并试图提取局部邻域的相关属性来解释复杂机器学习模型的预测。为了实现这一目标,这些算法可以涉及通过扰动特征在观察样本附近生成合成数据,这有时会引入不现实的样本,此外,大规模使用的计算成本很高。因此,仍然需要新的方法来更有效地大规模解释机器学习模型的预测。
技术实现思路
技术特征:
1.一种计算机系统,包括:
2.根据权利要求1所述的系统,其中所述输出包括所述预测的解释,所述预测基于所述输入特征按特征权重的排序而从所述第二特征向量被计算。
3.根据权利要求1所述的系统,其中所述输出标识所述代理模型的所述输入特征的集合的子集,所述子集由至少一个按特征权重排序最高的特征组成,或由所关联的特征权重超过指定阈值的至少一个特征组成。
4.根据权利要求3所述的系统,其中所述代理模型的所述输入特征是所述机器学习模型的输入特征的集合的子集,并且其中,如果由所述机器学习模型从所述第二特征向量计算的所述预测是错误的,所述操作还包括从所述机器学习模型的输入特征的集合中移除所述代理模型的所标识的所述输入特征的集合的子集。
5.根据权利要求4所述的系统,所述操作还包括在从所述机器学习模型的所述输入特征的集合中移除所标识的所述子集之后重新训练所述机器学习模型。
6.根据权利要求1所述的系统,其中所述代理模型的所述输入特征是所述机器学习模型的输入特征的集合的子集,其中所述输出标识所述代理模型的所述输入特征的集合的子集,所述子集由至少一个按特征权重排序最低的特征组成或由所关联的特征权重低于指定阈值的至少一个特征组成,并且其中所述操作还包括从所述机器学习模型的所述输入特征的集合中移除所标识的所述子集。
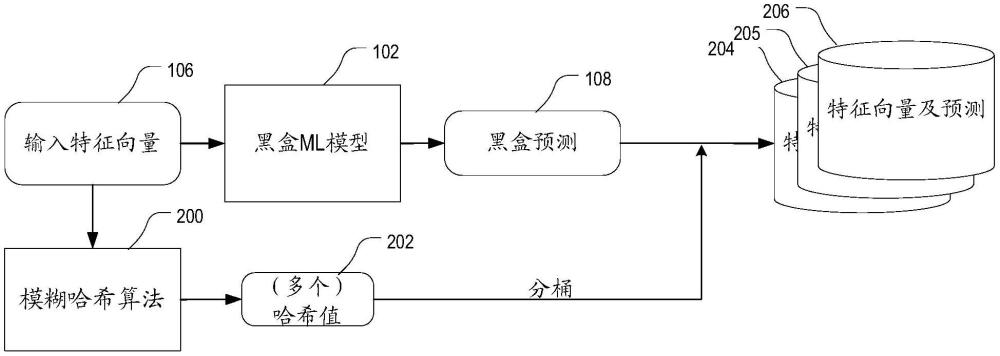
7.根据权利要求1所述的系统,其中所述模糊哈希值通过局部敏感哈希来计算。
8.根据权利要求1所述的系统,其中针对每个特征向量计算所述至少一个模糊哈希值包括:
9.根据权利要求8所述的系统,其中所述至少一个模糊哈希值包括多个模糊哈希值,所述多个模糊哈希值通过将所述签名向量划分为多个段并且将所述第二哈希函数应用于所述多个段中的每个段而被计算。
10.根据权利要求8所述的系统,其中使用所述第一哈希函数计算所述最小哈希值包括:将所述第一哈希函数中的每个第一哈希函数应用于所述特征向量中的每个特征,以计算针对所述第一哈希函数的特征哈希值,以及确定针对所述第一哈希函数中的每个第一哈希函数的特征哈希值的最小哈希值。
11.根据权利要求1所述的系统,其中所述操作还包括:
12.一种用于解释机器学习模型的预测的计算机实现的方法,所述方法包括:
13.根据权利要求12所述的方法,
14.根据权利要求12所述的方法,其中针对每个特征向量计算所述至少一个模糊哈希值包括:
15.至少一种计算机可读介质,存储:
技术总结
在借助代理模型解释机器学习模型的预测的系统中,机器学习模型输入的特征向量可以基于局部敏感哈希或其他哈希进行分组,其他哈希反映了匹配哈希值中特征向量之间的相似性。对于要解释的给定预测和对应的输入特征向量,可以通过对输入特征向量进行哈希并检索具有匹配哈希值的所存储的特征向量以及其相应的预测,以低计算成本获得代理模型的合适训练集。
技术研发人员:M·A·德玛,J·帕里克,K·霍尔斯海默,刘馥晨
受保护的技术使用者:微软技术许可有限责任公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!