用于选择智能眼镜中的摄像头的视场的用户接口的制作方法
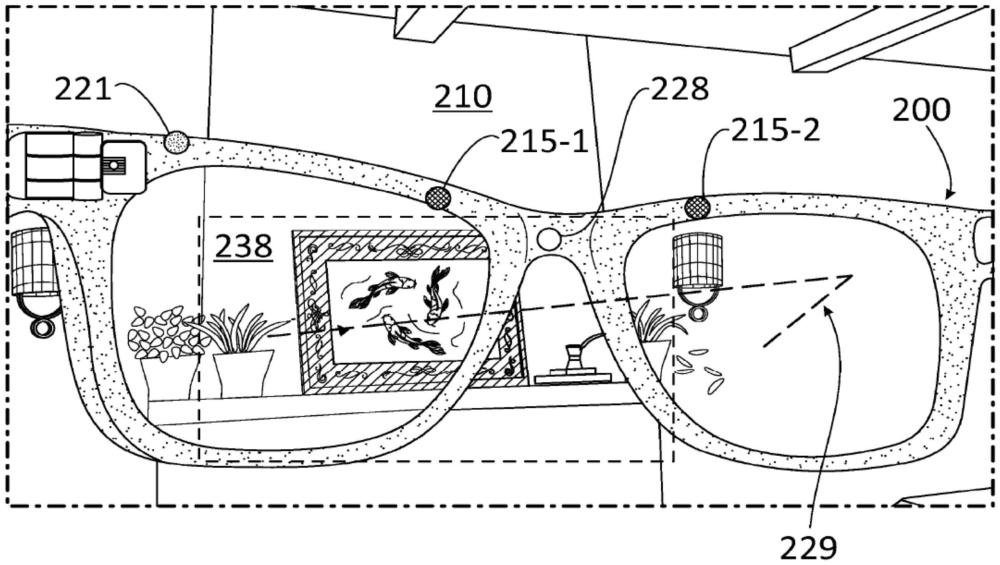
本公开涉及智能眼镜设备中的用户接口,所述智能眼镜设备包括用于记录图像和视频的一个或多个摄像头。更具体地,本公开涉及如下方法:所述方法用于使用眼动追踪工具来识别用户视野中的感兴趣区域并向用户提供非侵入性反馈,以使用户的感兴趣区域与智能眼镜中的一个或多个摄像头的视场一致。相关技术当代许多电子装置包括嵌入在可穿戴框架内的一个或多个摄像头,用户可以激活该一个或多个摄像头来采集照片或视频。然而,在许多情况下,用户采集的图像和视频与在采集时用户视野的感兴趣区域不匹配。发生这种情况是因为该一个或多个摄像头的角度和视场通常不同于用户的角度和视野。在某些类型的电子装置中,这种不一致可以通过在显示器上直接向用户提供一个或多个摄像头附件的视场的反馈来解决。然后,用户可以手动修改摄像头位置和光学配置(放大倍数和光圈大小等)以使该一个或多个摄像头附件的视场与感兴趣区域一致。然而,这种方法需要使用显示器,这在一些装置中可能是不可用的,并且需要用户集中注意力来校正不一致。在一些具有显示器的装置中,可能仍然期望使用这些装置中的显示资源(real estate)以最大化用户享受而不是用于硬件调整。
背景技术:
技术实现思路
1、根据本公开的第一方面,提供了一种设备,该设备包括:框架,该框架包括目镜,该目镜用于向用户提供前视图像;第一前视摄像头,该第一前视摄像头安装在框架上,该第一前视摄像头具有在前视图像内的视场;传感器,该传感器被配置为接收来自用户的命令,该命令指示前视图像内的感兴趣区域;以及接口设备,该接口设备用于向用户指示第一前视摄像头的视场与感兴趣区域对准。
2、在一些实施例中,传感器包括传声器,该传声器被配置为接收来自用户的语音命令。在一些实施例中,传感器包括电容式传感器,该电容式传感器被配置为接收来自用户的触摸手势。
3、在一些实施例中,传感器为眼动追踪传感器,该设备还包括处理器,该处理器被配置为基于来自眼动追踪传感器的信号来确定用户的注视方向,并将感兴趣区域识别为前视图像中的以注视方向为中心的部分。
4、在一些实施例中,传感器为第一前视摄像头,并且来自用户的命令是手势。
5、在一些实施例中,该设备还包括处理器,该处理器被配置为接收来自用户的手势,并基于该手势来识别指示视场内的感兴趣区域的命令。
6、在一些实施例中,该设备还包括处理器,该处理器被配置为基于来自用户的命令,在来自第一前视摄像头的图像中识别感兴趣对象。
7、在一些实施例中,该设备还包括第二前视摄像头,其中在第一前视摄像头的视场与感兴趣区域未对准时,来自用户的命令包括激活第二前视摄像头。
8、在一些实施例中,第一前视摄像头包括运动致动器,该运动致动器被配置为基于来自用户的命令来调整第一前视摄像头的视场。
9、在一些实施例中,目镜包括显示器,该显示器被配置为向用户显示第一前视摄像头的视场。
10、根据本公开的第二方面,提供了一种计算机实现的方法,该方法包括:在安装在智能眼镜系统上的第一摄像头设备中接收来自用户的命令,该命令指示用户观看的前视图像中的感兴趣区域;基于该命令确定感兴趣区域的边界;以及基于感兴趣区域与第一摄像头设备的视场之间的重叠向用户提供反馈。
11、在一些实施例中,该命令为语音命令,并且接收命令包括:将语音命令转换为文本命令,并对文本命令进行解析以获得指示用户意图的关键字。
12、在一些实施例中,该命令为语音命令,该方法还包括:基于语音签名来识别用户,以及在用户被识别时认证语音命令。
13、在一些实施例中,该命令是指示向用户显示的前视图像中的感兴趣对象的语音命令,该方法还包括:使第一摄像头设备的视场的中心对准感兴趣对象。
14、在一些实施例中,该计算机实现的方法还包括:接收来自用户的响应于反馈的第二命令,该第二命令涉及激活第二摄像头设备。
15、在一些实施例中,接收来自用户的命令包括:基于对所记录的来自用户的手势的学习历史,用手势识别模型来识别来自用户的手势。
16、在一些实施例中,接收来自用户的命令包括接收以下中一者:标记感兴趣区域的相对拐角的双手手势、描绘感兴趣区域的边界的手指手势、形成指示感兴趣区域中心的十字线的两指手势或包括感兴趣区域中心的圆形手势。
17、在一些实施例中,向用户提供反馈包括:激活致动器以指示用户移动头部位置,以改善感兴趣区域与第一摄像头设备的视场之间的对准。
18、在一些实施例中,该命令是手势,该方法还包括在手势识别模型未识别出手势时向用户提供反馈。
19、在一些实施例中,该命令是来自用户的手势,该方法还包括向用户提供该手势在第一摄像头设备的视场内不完整的反馈。
技术特征:
1.一种设备,包括:
2.根据权利要求1所述的设备,其中,所述传感器包括传声器,所述传声器被配置为接收来自所述用户的语音命令。
3.根据权利要求1或2所述的设备,其中,所述传感器包括电容式传感器,所述电容式传感器被配置为接收来自所述用户的触摸手势。
4.根据前述权利要求中任一项所述的设备,其中,所述传感器是眼动追踪传感器,所述设备还包括处理器,所述处理器被配置为基于来自所述眼动追踪传感器的信号来确定所述用户的注视方向,并将所述感兴趣区域识别为所述前视图像中的以所述注视方向为中心的部分。
5.根据前述权利要求中任一项所述的设备,其中,所述传感器是所述第一前视摄像头,并且来自所述用户的所述命令是手势。
6.根据前述权利要求中任一项所述的设备,还包括处理器,所述处理器被配置为接收来自所述用户的手势,并基于所述手势来识别指示所述视场内的所述感兴趣区域的所述命令。
7.根据前述权利要求中任一项所述的设备,还包括处理器,所述处理器被配置为基于来自所述用户的所述命令在来自所述第一前视摄像头的图像中识别感兴趣对象。
8.根据前述权利要求中任一项所述的设备,还包括第二前视摄像头,其中,在所述第一前视摄像头的视场与所述感兴趣区域未对准时,来自所述用户的命令包括激活所述第二前视摄像头。
9.根据前述权利要求中任一项所述的设备,其中,所述第一前视摄像头包括运动致动器,所述运动致动器被配置为基于来自所述用户的命令来调整所述第一前视摄像头的视场;和/或优选地,其中,所述目镜包括显示器,所述显示器被配置为向所述用户显示所述第一前视摄像头的视场。
10.一种计算机实现的方法,包括:
11.根据权利要求10所述的计算机实现的方法,其中,所述命令是语音命令,并且接收所述命令包括:将所述语音命令转换为文本命令,并对所述文本命令进行解析以获得指示用户意图的关键字。
12.根据权利要求10或11所述的计算机实现的方法,其中,所述命令是语音命令,所述计算机实现的方法还包括:基于语音签名来识别用户,以及在所述用户被识别出时认证所述语音命令;和/或优选地,其中,所述命令是指示向所述用户显示的所述前视图像中的感兴趣对象的语音命令,所述计算机实现的方法还包括:使所述第一摄像头设备的视场的中心对准所述感兴趣对象。
13.根据权利要求10至12中任一项所述的计算机实现的方法,还包括:接收来自所述用户的响应于所述反馈的第二命令,所述第二命令涉及激活第二摄像头设备;和/或优选地,其中,接收来自所述用户的命令包括:基于对所记录的来自所述用户的手势的学习历史,用手势识别模型来识别来自所述用户的手势。
14.根据权利要求10至13中任一项所述的计算机实现的方法,其中,接收来自所述用户的命令包括接收以下中的一者:标记所述感兴趣区域的相对拐角的双手手势、描绘所述感兴趣区域的边界的手指手势、形成指示所述感兴趣区域的中心的十字线的两指手势或包括所述感兴趣区域的中心的圆形手势;和/或优选地,其中,向所述用户提供反馈包括激活致动器以指示所述用户移动头部位置,以改善所述感兴趣区域与所述第一摄像头设备的视场之间的对准。
15.根据权利要求10至14中任一项所述的计算机实现的方法,其中,所述命令是手势,所述计算机实现的方法还包括在手势识别模型未识别出所述手势时向所述用户提供反馈;和/或优选地,其中,所述命令是来自所述用户的手势,所述计算机实现的方法还包括向所述用户提供所述手势在所述第一摄像头设备的视场内不完整的反馈。
技术总结
提供了一种用于沉浸式现实应用中的可穿戴设备。该可穿戴设备具有:框架,该框架包括目镜,该目镜用于向用户提供前视图像;第一前视摄像头,该第一前视摄像头安装在框架上,该第一前视摄像头具有在该前视图像内的视场;传感器,该传感器被配置为接收来自用户的命令,该命令指示视场内的感兴趣区域;以及接口设备,该接口设备用于向用户指示第一前视摄像头的视场与感兴趣区域对准。还提供了该设备的使用方法、存储指令的存储器和执行所述指令以使设备执行使用方法的处理器。
技术研发人员:塞巴斯蒂安·斯图克,萨普纳·史洛夫,胡均,约翰娜·加布里埃拉·科约克·埃斯库德罗
受保护的技术使用者:元平台技术有限公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!