用于机器学习的计算机模型的迭代训练的制作方法
背景技术:
1、本发明涉及数字计算机系统领域,并且更具体地涉及用于训练基于机器学习的引擎的方法。
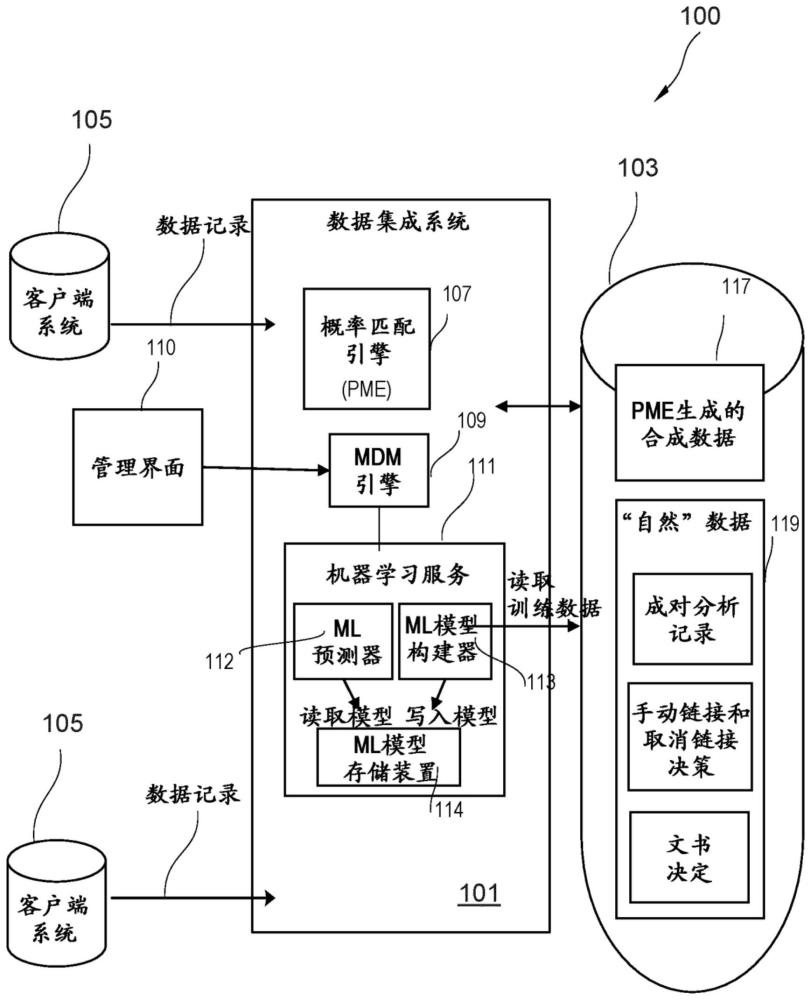
2、文书记录是针对其给定匹配过程不能确定它们是否彼此是重复记录并且因此应当被合并或者一个或多个是否应该被认为是不匹配并且因此应当被保持彼此分开的记录。那些文书记录可能需要用户干预以更接近地查看数据记录的值。尽管自动化和改进记录匹配过程的巨大努力,那些文书记录的数目连续地增加(例如,它可以是数百万个文书记录)。这导致大部分文书记录不在非常长的时间段内被处理,在所述非常长的时间段内不一致的数据可被用于系统配置中。
技术实现思路
1、各个实施例提供了一种用于训练基于机器学习的引擎的方法、计算机系统和计算机程序产品,如独立权利要求的技术方案所描述的。在从属权利要求中描述了有利的实施例。如果本发明的实施例不相互排斥,则它们可以彼此自由组合。
2、在根据本发明的一个方面中,一种训练基于机器学习的引擎的计算机实现的方法包括接收当前训练数据集。第一分数的当前训练数据集包括合成训练数据,并且剩余第二分数的训练数据集包括真实训练数据。真实训练数据是用户定义数据,并且合成训练数据是系统定义数据。该方法包括通过使用当前训练数据集来重复地训练基于机器学习的引擎,其中在每次迭代中或者在迭代的子集的每次迭代中通过添加真实训练数据来更新训练数据集,由此在经更新的训练数据集中增加第二分数的真实训练数据并且减少第一分数的合成训练数据。
3、在相关方面,基于机器学习的引擎被训练成确定两个数据记录是否是彼此的副本,并且该方法进一步包括使用被训练后的基于机器学习的引擎来比较数据库的记录。
4、在相关方面,如果当前经训练的基于机器学习的引擎的预测准确度与上次迭代的经训练的基于机器学习的引擎的预测准确度相比未增加,则使用基于机器学习的引擎来比较数据库的记录。
5、在相关方面,如果第一分数为零,则基于机器学习的引擎被用于比较数据库的记录。
6、在相关方面,该方法进一步包括:在每次迭代中或者在所述迭代的子集的每次迭代中,减少所述合成训练数据,由此进一步减少经更新的训练数据集中的第一分数的合成训练数据。
7、在相关方面,合成训练数据的减少是绝对减少或者相对减少。
8、在相关方面,合成训练数据的重复减少包括逐渐减少合成训练数据的量。
9、在相关方面,合成训练数据的量被减少到仅对真实训练数据执行训练的点。
10、在相关方面,被用于训练的合成训练数据的减少的水平基于至少一个预测质量度量而被动态调整。
11、在相关方面中,针对基于机器学习的引擎的训练的第一执行,第二分数是零。
12、在相关方面,基于机器学习的引擎是用于在数据库中查找副本的基于机器学习的匹配引擎,训练数据集包括标记的记录。合成训练数据的记录由基于规则的匹配引擎基于由基于规则的匹配引擎进行的记录的比较来标记。
13、在相关方面,基于规则的匹配引擎使用确定性匹配和/或概率性匹配来操作。
14、在相关方面,标记合成训练记录包括使用基于规则的匹配引擎的默认配置。
15、在根据本发明的另一方面,一种计算机程序产品包括计算机可读存储介质,所述计算机可读存储介质具有与其体现的程序指令。所述程序指令由计算机可执行以使所述计算机执行包括以下功能的功能:接收当前训练数据集,第一分数的所述当前训练数据集包括合成训练数据,并且剩余第二分数的所述训练数据集包括真实训练数据,所述真实训练数据是用户定义数据,并且所述合成训练数据是系统定义数据;以及通过使用所述当前训练数据集来重复地训练所述基于机器学习的引擎,其中所述训练数据集在每次迭代中或者在所述迭代的子集的每次迭代中通过添加真实训练数据而被更新,由此增加所述第二分数的所述真实训练数据并且减少经更新的训练数据集中的所述第一分数的所述合成训练数据。
16、在根据本发明的另一方面,一种训练基于机器学习的引擎的系统,该系统包括计算机系统,该计算机系统包括:计算机处理器、计算机可读存储介质、以及存储在该计算机可读存储介质上的程序指令,该程序指令由该处理器可执行以使该计算机系统执行以下功能:接收当前训练数据集,第一分数的所述训练数据集包括合成训练数据并且剩余第二分数的所述训练数据集包括真实训练数据,所述真实训练数据是用户定义数据并且所述合成训练数据是系统定义数据;以及通过使用所述当前训练数据集来重复地训练所述基于机器学习的引擎,其中所述训练数据集在每次迭代中或者在所述迭代的子集的每次迭代中通过添加真实训练数据而被更新,由此在所述经更新的训练数据集中增加所述第二分数并且减少所述第一分数的所述合成训练数据。
技术特征:
1.一种训练基于机器学习的引擎的计算机实现的方法,所述方法包括:
2.根据权利要求1所述的方法,所述基于机器学习的引擎被训练以确定两个数据记录是否是彼此的副本,所述方法进一步包括使用被训练后的所述基于机器学习的引擎来比较数据库的记录。
3.根据权利要求2所述的方法,其中如果当前经训练的所述基于机器学习的引擎的预测准确度与上一次迭代的经训练的所述基于机器学习的引擎的所述预测准确度相比没有增加,则所述基于机器学习的引擎被用于比较所述数据库的所述记录。
4.根据权利要求2所述的方法,其中如果所述第一分数是零,则所述基于机器学习的引擎被用于比较所述数据库的所述记录。
5.根据权利要求1所述的方法,进一步包括:在每次迭代中或者在所述迭代的所述子集的每次迭代中,减少所述合成训练数据,由此进一步减少经更新的所述训练数据集中的所述第一分数的合成训练数据。
6.根据权利要求5所述的方法,其中所述合成训练数据的所述减少是绝对减少或者相对减少。
7.根据权利要求5所述的方法,其中所述合成训练数据的重复减少包括逐渐减少合成训练数据的量。
8.根据权利要求5所述的方法,其中合成训练数据的所述量被减少到仅对真实训练数据执行所述训练的点。
9.根据权利要求5所述的方法,其中被用于训练的所述合成训练数据的减少的水平基于至少一个预测质量度量而被动态地调整。
10.根据权利要求1所述的方法,针对所述基于机器学习的引擎的所述训练的所述第一执行,所述第二分数为零。
11.根据权利要求1所述的方法,其中所述基于机器学习的引擎是用于在数据库中查找副本的基于机器学习的匹配引擎,所述训练数据集包括标记的记录,其中所述合成训练数据的所述记录由基于规则的匹配引擎基于由所述基于规则的匹配引擎对所述记录的比较来标记。
12.根据权利要求11所述的方法,其中所述基于规则的匹配引擎使用确定性匹配和/或概率性匹配来操作。
13.根据权利要求11所述的方法,其中标记合成训练记录包括使用所述基于规则的匹配引擎的默认配置。
14.一种计算机程序产品,包括计算机可读存储介质,所述计算机可读存储介质具有利用其体现的程序指令,所述程序指令由计算机可执行以使所述计算机由所述计算机执行功能,所述功能包括用于以下操作的功能:
15.根据权利要求14所述的计算机程序产品,所述基于机器学习的引擎被训练以确定两个数据记录是否是彼此的副本,所述方法进一步包括使用被训练后的所述基于机器学习的引擎来比较数据库的记录。
16.根据权利要求15所述的计算机程序产品,其中如果当前经训练的所述基于机器学习的引擎的预测准确度与所述上一次迭代的经训练的所述基于机器学习的引擎的所述预测准确度相比没有增加,则所述基于机器学习的引擎被用于比较所述数据库的所述记录。
17.根据权利要求15所述的计算机程序产品,其中如果所述第一分数是零,则所述基于机器学习的引擎被用于比较所述数据库的所述记录。
18.根据权利要求14所述的计算机程序产品,进一步包括:在每次迭代中或者在所述迭代的所述子集的每次迭代中,减少所述合成训练数据,由此进一步减少经更新的所述训练数据集中的所述第一分数的合成训练数据。
19.根据权利要求18的所述计算机程序产品,其中所述合成训练数据的所述减少是绝对减少或者相对减少。
20.一种训练基于机器学习的引擎的系统,所述系统包括计算机系统,所述计算机系统包括:计算机处理器、计算机可读存储介质、以及被存储在所述计算机可读存储介质上的程序指令,所述程序指令由所述处理器可执行,以使所述计算机系统执行以下功能以:
技术总结
本公开涉及接收当前训练数据集的计算机。第一分数的训练数据集包括合成训练数据,并且剩余第二分数的训练数据集包括真实训练数据。真实训练数据是用户定义数据,并且合成训练数据是系统定义数据。基于机器学习的引擎被训练并且可通过使用当前训练数据集来重复地执行。在每次迭代或迭代的子集中,通过添加真实训练数据来更新训练数据集,由此增加经更新的训练数据集中的第二分数并减少第一分数的合成训练数据。
技术研发人员:H·科尼格,L·布雷默,M·欧弗斯,M·奥贝霍弗
受保护的技术使用者:国际商业机器公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!