利用无监督元学习来提升小样本动作识别的制作方法
背景技术:
1、深度神经网络已经在向诸如图像分类、对象检测、动作识别等的广泛的任务上的新颖类别集合的转换学习方面取得了优越的性能。然而,这种性能取决于大规模、分布均匀、干净且有标签的训练数据的可用性,以首先训练强监督模型。获取此类训练数据既耗时又昂贵,并且通常是不可行的。特别是,用各种个人动作大规模注释视频数据非常耗时、容易出错且不切实际。
技术实现思路
1、本
技术实现要素:
被提供是为了以简化的形式介绍一些概念的选择,这些概念将在下面的详细说明中进一步描述。本发明内容无意于识别所要求保护的主题的关键特征或基本特征,也无意于用作确定所要求保护的主题的范围的帮助。
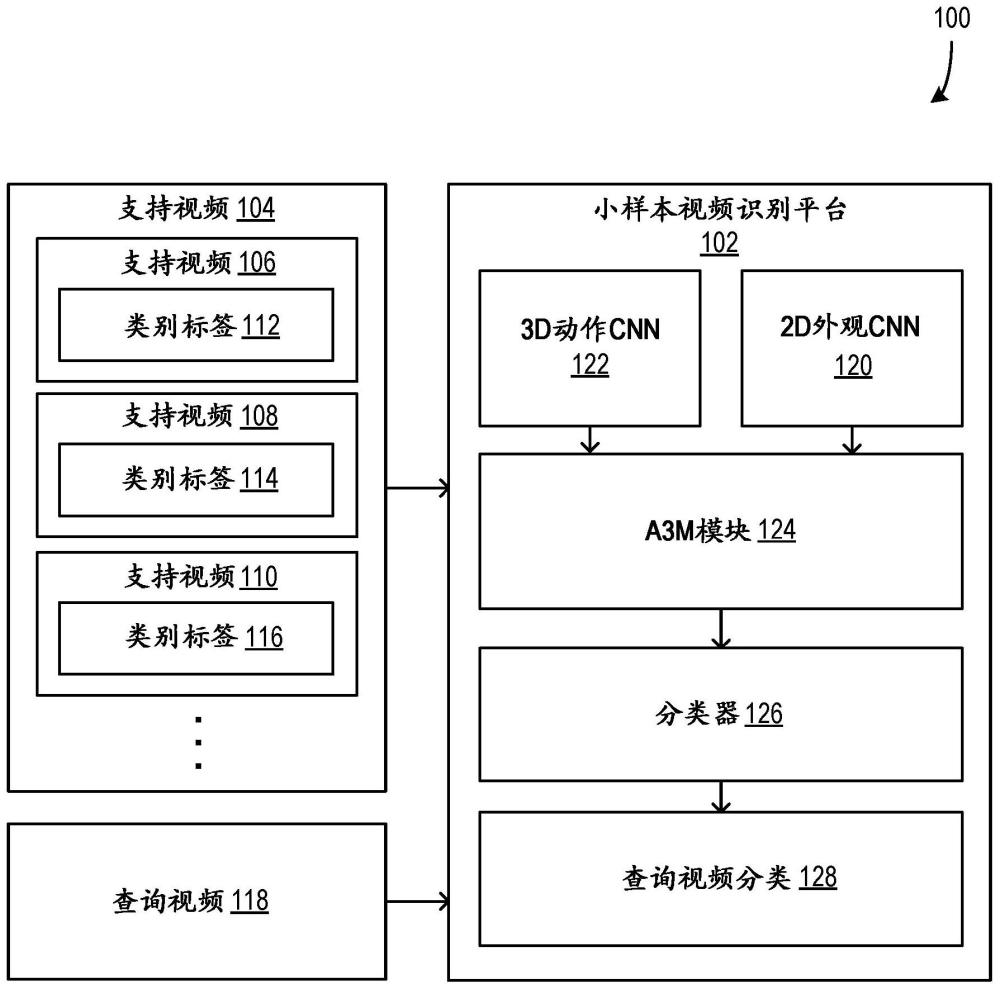
2、一种使用预先训练的编码器和新颖类别微调来准备用于动作识别的交叉注意模型的计算机化方法被描述。无标签的训练视频数据被转换为增强训练视频片段,用于训练外观(appearance)编码器和动作编码器。外观编码器使用无监督训练进行训练,以基于空间语义对视频片段进行编码,动作编码器使用无监督训练进行训练,以基于时空语义对视频片段进行编码。难挖掘的(hard-mined)训练回合(episode)集合通过使用经训练的外观编码器和经训练的动作编码器而被生成。交叉注意力模块然后被使用难挖掘的训练回合集合进行训练。然后,支持视频片段集合被获取,其中每个支持视频片段与视频类别集合中的视频类别相关联。交叉注意力模块通过使用获取的支持视频片段集合和相关联的视频类别进行微调以用于动作-外观对齐分类。查询视频片段被获取以及被使用经微调的交叉注意力模块进行分类,其中该获取的查询视频片段被分类为视频类别集合中的视频类别。
技术特征:
1.一种系统,包括:
2.根据权利要求1所述的系统,其中所述至少一个存储器和所述计算机程序代码被配置为与所述至少一个处理器一起还使所述至少一个处理器:
3.根据权利要求2所述的系统,其中所述支持视频片段集合中的所述视频类别集合是与所述训练视频数据的类别不同的新颖类别。
4.根据权利要求2至3中任一项所述的系统,其中所述支持视频片段集合包括小样本视频片段,由此经训练的所述交叉注意力模块基于所述小样本视频片段而被微调,以基于所述小样本视频片段的视频类别对视频片段进行分类。
5.根据权利要求1至4中任一项所述的系统,其中将训练视频数据转换为增强训练视频片段集合包括以下至少一项:裁剪视频数据的部分、水平翻转视频数据、改变视频数据的颜色、将视频数据转换为灰度、以及将高斯模糊引入到视频数据中。
6.根据权利要求1至5中任一项所述的系统,其中基于所述增强训练视频片段集合来训练所述外观编码器包括:基于采样的视频帧来训练所述外观编码器,所述采样的视频帧在所述训练视频片段的整个视频回合被均匀地间隔开;并且
7.根据权利要求1至6中任一项所述的系统,其中使用所生成的所述难挖掘的训练回合集合来训练用于动作-外观对齐分类的所述交叉注意力模块包括:
8.根据权利要求1至7中任一项所述的系统,其中所述训练视频数据包括有标签的数据和无标签的数据,并且所述外观编码器和所述动作编码器使用以下至少一项而被训练:半监督训练和弱监督训练。
9.一种计算机化方法,包括:
10.根据权利要求9所述的计算机化方法,其中所述支持视频片段集合中的所述视频类别集合是与被用于训练所述交叉注意力模块的训练视频数据的类别不同的新颖类别。
11.根据权利要求9至10中任一项所述的计算机化方法,其中所述支持视频片段集合包括小样本视频片段,由此所述经训练的交叉注意力模块基于所述小样本视频片段而被微调,以基于所述小样本视频片段的视频类别对视频片段进行分类。
12.根据权利要求9至11中任一项所述的计算机化方法,其中所述经训练的交叉注意力模型基于被增强的训练视频片段而被训练,其中所述训练视频片段的增强包括以下至少一项:裁剪视频数据的部分、水平翻转视频数据、改变视频数据的颜色、将视频数据转换为灰度、以及将高斯模糊引入到视频数据中。
13.一种或多种计算机存储介质,所述一种或多种计算机存储介质具有计算机可执行指令,所述计算机可执行指令在由处理器执行时,使所述处理器至少:
14.根据权利要求13所述的一种或多种计算机存储介质,其中所述计算机可执行指令在由处理器执行时,还使所述处理器至少:
15.根据权利要求14所述的一种或多种计算机存储介质,其中所述支持视频片段集合包括小样本视频片段,由此经训练的所述交叉注意力模块基于所述小样本视频片段而被微调,以基于所述小样本视频片段的视频类别对视频片段进行分类。
技术总结
本文的公开内容描述了使用预先训练的编码器和新颖类别微调来准备和使用用于动作识别的交叉注意力模型。训练视频数据被转换为增强训练视频片段,以用于训练外观编码器和动作编码器。外观编码器被训练为基于空间语义对视频片段进行编码,动作编码器被训练为基于时空语义对视频片段进行编码。难挖掘的训练回合集合通过使用经训练的编码器而被生成。交叉注意力模块然后被使用难挖掘的训练回合进行训练以用于动作‑外观对齐分类。然后,获取支持视频片段,其中每个支持视频片段与视频类别相关联。交叉注意力模块通过使用获取的支持视频片段和相关视频类别进行微调。使用经微调的交叉注意模块获取查询视频片段并将其分类为视频类别。
技术研发人员:G·米塔尔,喻冶,陈梅,J·S·帕特拉瓦里
受保护的技术使用者:微软技术许可有限责任公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!