用于端到端自监督预训练的对比学习和掩蔽建模的制作方法
本公开总体上涉及机器学习。更具体地,本公开涉及利用对比损失项和掩蔽建模损失项的组合的改进的端到端自监督预训练框架。
背景技术:
1、利用大规模未注释数据来改进机器学习模型在各种任务上的性能的技术的开发一直是长期存在的研究问题。迄今为止,已经有两种主要方法用于利用未标记数据来处理这种半监督任务。
2、第一道工作是自训练,也称为伪标记,其中系统开始于使用初始可用的标记数据来训练教师模型。接下来,教师模型用于标记未标记的数据。然后使用组合的标记和伪标记数据来训练学生模型。伪标记过程可以重复多次以改进教师模型的质量。对于许多不同的任务和域,自训练已经是一种实际有用且广泛研究的技术。
3、利用未标记数据的第二方向是无监督预训练或自监督预训练。在无监督预训练中,首先训练模型以完成代理任务,该代理任务被设计为仅消耗未标记数据(因此被称为“无监督”)。通常认为这种代理任务能够在受监督的数据上训练之前在良好的起始点初始化模型的参数。最近已经进行了大量的研究努力来开发代理任务,当模型在某些下游任务上被微调时,该代理任务允许模型良好地执行。还有研究表明,自训练和无监督预训练带来的增益对于某些下游任务是相加的。
技术实现思路
1、本公开的实施例的方面和优点将在以下描述中部分地阐述,或者可以从描述中获知,或者可以通过实施例的实践而获知。
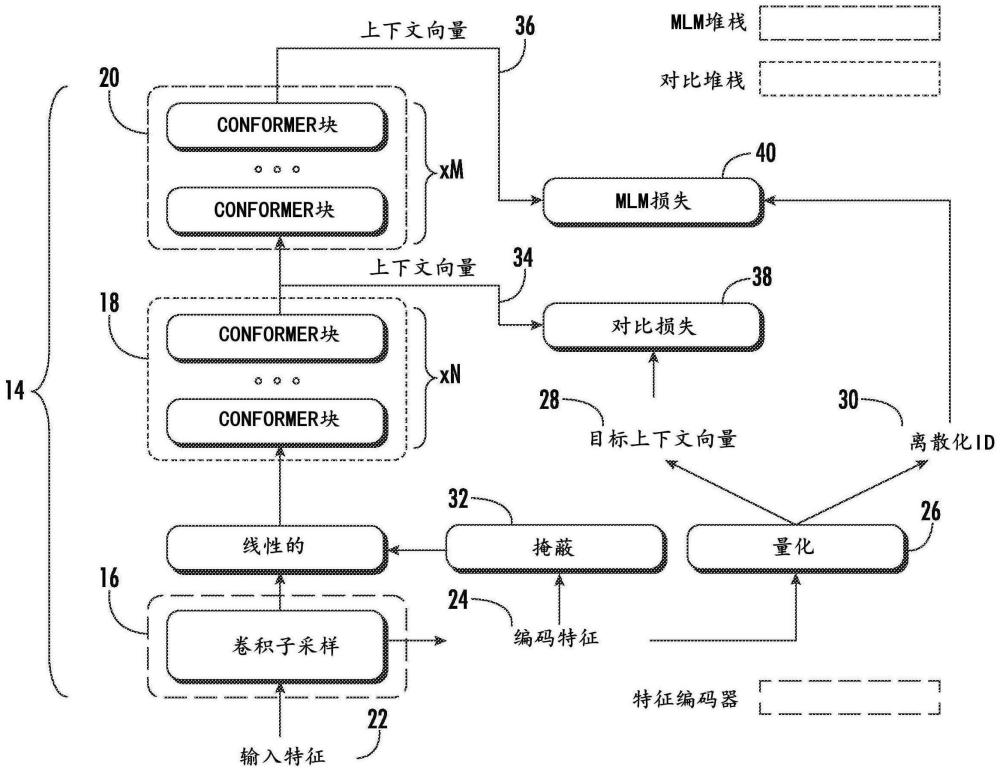
2、本公开中描述的一个示例涉及一种用于执行端到端自监督预训练的计算机实现的方法。该方法包括由包括一个或多个计算设备的计算系统获得一系列输入数据。该方法包括由计算系统用机器学习模型的第一编码器部分处理一系列输入数据以生成多个编码特征。该方法包括由计算系统量化多个编码特征以生成多个目标量化向量和与多个目标量化向量相关联的多个离散化标识符。该方法包括由计算系统掩蔽多个编码特征中的一个或多个。该方法包括:在所述掩蔽之后,由计算系统用机器学习模型的第二编码器部分处理多个编码特征,以生成第一组上下文向量。该方法包括由计算系统用机器学习模型的第三编码器部分处理第一组上下文向量以生成第二组上下文向量。该方法包括由计算系统评估包括对比损失项和掩蔽建模项的损失函数,其中对比损失项评估基于第一组上下文向量和多个目标量化向量生成的对比预训练输出,并且其中掩蔽建模损失项评估基于第二组上下文向量和多个离散化标识符生成的掩蔽建模预训练输出。该方法包括由计算系统基于损失函数端到端地训练机器学习模型。
3、对于一个或多个掩蔽位置中的每一个,对比预训练输出可以包括来自一组候选向量的预测选择,预测选择基于第一组上下文向量中的对应于掩蔽位置的一个上下文向量来生成。该组候选向量可以包括真目标量化向量和一个或多个干扰(distractor)向量。对比损失项可以评估预测选择是否对应于真目标量化向量。
4、对于一个或多个掩蔽位置中的每一个:掩蔽建模预训练输出可以包括基于第二组上下文向量中的对应于掩蔽位置的一个上下文向量生成的预测标识符,并且掩蔽建模损失项可以评估预测标识符是否对应于多个离散化标识符中的对应于掩蔽位置的真离散化标识符。
5、机器学习模型的第二编码器部分可以包括一个或多个conformer块。类似地,编码器部分可以包括一个或多个conformer块。
6、由计算系统基于损失函数训练机器学习模型可以包括由计算系统基于掩蔽建模损失项修改机器学习模型的第三编码器部分、第二编码器部分和第一编码器部分的一个或多个参数的一个或多个值。训练机器学习模型还可以包括由计算系统基于掩蔽建模损失项和对比损失项的组合来修改机器学习模型的第二编码器部分和第一编码器部分的一个或多个参数的一个或多个值。
7、该方法可以包括基于损失函数修改用于执行量化的码本。
8、一系列输入数据可以包括音频数据或音频数据的频谱表示。例如,音频数据可以包括语音数据。例如,机器学习模型可以是用于执行语音相关任务(诸如语音识别和/或语音转换(speech translation))的模型。一系列输入数据可以附加地或替代地包括文本数据、传感器数据和/或图像数据。
9、本公开中描述的另一示例涉及共同存储指令的一个或多个非暂时性计算机可读介质,所述指令在由计算系统的一个或多个处理器执行时使计算系统执行操作。例如,操作可以包括用于执行本文描述的任何方法的操作。例如,操作可以包括获得任务特定的训练输入。操作包括用机器学习模型处理任务特定的训练输入以生成任务特定的训练输出,其中机器学习模型的至少编码器部分已经使用包括对比损失项和掩蔽建模项的损失函数进行了端到端训练,其中对比损失项评估基于第一组上下文向量和多个目标量化向量生成的对比预训练输出,第一组上下文向量是在掩蔽机器学习模型的编码器部分的输入或中间输出之后由机器学习模型的编码器部分生成的,多个目标量化向量是通过量化机器学习模型的编码器部分的输入或中间输出生成的,并且其中掩蔽建模损失项评估基于第二组上下文向量和多个离散化标识符生成的掩蔽建模预训练输出,第二组上下文向量由机器学习模型的编码器部分从第一组上下文向量生成,多个离散化标识符通过量化机器学习模型的编码器部分的输入或中间输出生成。操作包括基于任务特定的训练输出来评估任务特定的损失函数。操作包括基于任务特定的损失函数来训练机器学习模型。
10、本公开的另一示例方面涉及一种计算系统。计算系统包括一个或多个处理器和一个或多个非暂时性计算机可读介质,一个或多个非暂时性计算机可读介质共同存储指令,所述指令在由计算系统的一个或多个处理器执行时使计算系统执行操作。操作可以包括本文描述的任何方法。例如,操作可以包括获得任务特定的推理输入。操作包括用机器学习模型处理任务特定的推理输入,以生成任务特定的推理输出,其中机器学习模型的至少编码器部分已经使用包括对比损失项和掩蔽建模项的损失函数进行了端到端训练,其中对比损失项评估基于第一组上下文向量和多个目标量化向量生成的对比预训练输出,第一组上下文向量是在掩蔽机器学习模型的编码器部分的输入或中间输出之后由机器学习模型的编码器部分生成的,多个目标量化向量是通过量化机器学习模型的编码器部分的输入或中间输出生成的,并且其中掩蔽建模损失项评估基于第二组上下文向量和多个离散化标识符生成的掩蔽建模预训练输出,第二组上下文向量由机器学习模型的编码器部分从第一组上下文向量生成,多个离散化标识符通过量化机器学习模型的编码器部分的输入或中间输出生成。操作包括提供任务特定的推理输出作为输出。
11、本公开中描述的其他示例涉及各种系统、装置、非暂时性计算机可读介质、用户界面和电子设备。
12、参考以下描述和所附权利要求,将更好地理解本公开的各种实施例的这些和其他特征、方面和优点。并入本说明书中并构成本说明书的一部分的附图示出了本公开的示例实施例,并且与说明书一起用于解释相关原理。
技术特征:
1.一种执行自监督预训练的计算机实现的方法,所述方法包括:
2.根据权利要求1所述的计算机实现的方法,其中,对于一个或多个掩蔽位置中的每一个:
3.根据任一前述权利要求所述的计算机实现的方法,其中,对于一个或多个掩蔽位置中的每一个:
4.根据任一前述权利要求所述的计算机实现的方法,其中,所述机器学习模型的所述第二编码器部分和/或所述第三编码器部分包括一个或多个conformer块。
5.根据任一前述权利要求所述的计算机实现的方法,其中,所述机器学习模型的所述第三编码器部分包括一个或多个conformer块。
6.根据任一前述权利要求所述的计算机实现的方法,其中,由所述计算系统基于所述损失函数训练所述机器学习模型包括:
7.根据任一前述权利要求所述的计算机实现的方法,还包括:
8.根据任一前述权利要求所述的计算机实现的方法,其中,所述一系列输入数据包括音频数据或所述音频数据的频谱表示。
9.根据权利要求8所述的计算机实现的方法,其中,所述音频数据包括语音数据。
10.根据任一前述权利要求所述的计算机实现的方法,其中,所述一系列输入数据包括文本数据。
11.根据任一前述权利要求所述的计算机实现的方法,其中,所述一系列输入数据包括传感器数据或图像数据。
12.一个或多个非暂时性计算机可读介质,所述一个或多个非暂时性计算机可读介质共同存储指令,所述指令在由计算系统的一个或多个处理器执行时使所述计算系统执行操作,所述操作包括:
13.根据权利要求12所述的一个或多个非暂时性计算机可读介质,其中,对于一个或多个掩蔽位置中的每一个:
14.根据权利要求12或13所述的一个或多个非暂时性计算机可读介质,其中,对于一个或多个掩蔽位置中的每一个:
15.根据权利要求12、13或14所述的一个或多个非暂时性计算机可读介质,其中所述机器学习模型的所述编码器部分包括一个或多个conformer块。
16.根据权利要求12-15中任一项所述的一个或多个非暂时性计算机可读介质,其中,所述机器学习模型包括解码器部分,所述解码器部分被配置为处理所述编码器部分的输出以生成所述任务特定的训练输出。
17.根据权利要求12-16中任一项所述的一个或多个非暂时性计算机可读介质,其中:
18.所述任务特定的训练输出包括语音数据的转换或针对语音数据的语音识别。
19.一种计算系统,包括:
20.根据权利要求18所述的计算系统,其中,对于一个或多个掩蔽位置中的每一个:
21.根据权利要求18或19所述的计算系统,其中,对于一个或多个掩蔽位置中的每一个:
22.根据权利要求18-20中任一项所述的计算系统,其中,所述机器学习模型的编码器部分包括一个或多个conformer块。
23.根据权利要求18-21中任一项所述的计算系统,其中,所述机器学习模型包括解码器部分,所述解码器部分被配置为处理所述编码器部分的输出以生成所述任务特定的推理输出。
24.根据权利要求18-22中任一项所述的计算系统,其中:
技术总结
提供了改进的端到端自监督预训练框架,其利用对比损失项和掩蔽建模损失项的组合。具体地,本公开提供组合对比学习和掩蔽建模的框架,其中前者训练模型以将输入数据(例如,连续信号,如连续语音信号)离散化成有限组的判别令牌,并且后者训练模型以通过求解消耗离散化令牌的掩蔽预测任务来学习语境化表示。与依赖于迭代重新聚类和重新训练过程的某些现有的基于掩蔽建模的预训练框架或连接两个分开训练的模块的其他现有框架相比,所提出的框架可以通过同时求解两个自监督任务(对比任务和掩蔽建模)来使得模型能够以端到端的方式被优化。
技术研发人员:张羽,锺毓安,韩玮,C-C·邱,W·秦,R·庞,吴永辉
受保护的技术使用者:谷歌有限责任公司
技术研发日:
技术公布日:2024/5/8
- 还没有人留言评论。精彩留言会获得点赞!