一种视频卷积降噪方法、系统、终端及存储介质与流程
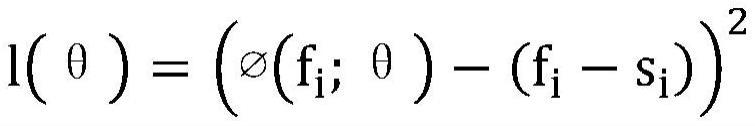
本发明涉及视频处理领域,尤其涉及一种视频卷积降噪方法、系统、终端及存储介质。
背景技术:
1、一般情况下,由于设备、环境等因素的作用,视频图像在经过收集、处理、传输、接收、输出后,易出现噪声干扰。噪声的存在对视频图像信息的提取具有阻碍效应,视频图像去噪,改善视频图像的质量意义显著。
2、目前的降噪技术十分丰富,利用滤波技术直接对图像像素点进行处理,利用空间变换将图像信息放到其它域调整、逆变换,少数利用优化理论为基础的智能降噪方法等,其中多数方法面临着图像边缘信息丢失的现象,且忽略视频的时域噪声;另一主要是降噪的反应速度,尤其处理视频降噪的场景下,信息冗余以及降噪智能化的要求。为了解决上述技术问题现提出一种视频卷积降噪方法、系统、终端及存储介质。
技术实现思路
1、为了解决上述现有技术中存在的技术问题,本发明提供了一种视频卷积降噪方法、系统、终端及存储介质,采用视频影像n分段随机稀疏采样的方式,考虑影像帧之间的连续性,捕捉时域噪声;降低视频信息冗余,稀疏化模型架构,提高降噪的反应速度;使用神经网络捕捉噪声,删减式精准降噪,尽量遏制视频影像边缘信息丢失。
2、为实现上述目的,本发明实施例提供了如下的技术方案:
3、第一方面,在本发明提供的一个实施例中,提供了视频卷积降噪方法,该方法包括以下步骤:
4、构造视频训练集,所述视频训练集包括无噪声视频s和噪声视频f;其中,噪声视频f(t)通过无噪声视频s中加入白噪声n得到;
5、采样无噪声视频s和噪声视频f影像帧,构造n影像模块
6、神经网络模型构建及基于所述n影像模块对神经网络模型进行训练;
7、应用神经网络模型到噪声视频影像,进行降噪处理。
8、作为本发明的进一步方案,所述构造视频训练集包括如下步骤:
9、假设含噪声视频为f,噪声视频f为原始视频s和白噪声n之和:
10、f(t)=s(t)+n(t)
11、其中,n(t)一般为均值为零的高斯白噪声。
12、作为本发明的进一步方案,所述采样无噪声视频s和噪声视频f影像帧,构造影像模块包括如下步骤:
13、将视频影像均匀分成n段,在每一段中按序列顺序随机稀疏采样5帧图像,每帧图像均为三通道rgb图像,采用相同权值3d卷积神经网络将rgb图像转化成2d feature map,将5帧的2d feature maps堆叠成帧模块,即可得到n影像模块
14、作为本发明的进一步方案,所述神经网络模型构建,包括:
15、定义为神经网络模型;
16、假定视频影像模块为数据损失函数定义
17、
18、代价函数
19、
20、其中,θ为神经网络模型的参数和同权值转化网络的参数全集;
21、使用adam优化训练神经网络参数θ;
22、将过滤后的视频与无噪声视频s比较,即相似性度量评估神经网络去除噪声效果。
23、作为本发明的进一步方案,所述神经网络模型基本结构为:
24、1-2层:conv 1×1+relu,步长设置为1;
25、3-10层:conv 3×3×3(padding=1)+bn+relu+maxpooling,步长设置为1,bias=false;
26、11-18层:conv 3×3×3(padding=1)+bn+relu+uppooling,步长设置为1,bias=false;
27、19层:conv 3×3(padding=1)+relu,步长设置为1。
28、作为本发明的进一步方案,所述应用神经网络模型到噪声视频影像,进行降噪处理,具体包括:
29、将视频影像数据按序列连续分帧,每5帧影像作为一模块,神经网络模型对模块进行降噪处理。
30、作为本发明的进一步方案,其中,
31、σ2为高斯白噪声功率。
32、第二方面,在本发明提供的又一个实施例中,提供了视频卷积降噪系统,该系统包括:构造视频训练集模块100、构造影像模块200、神经网络模型构建训练模块300和视频影像噪声处理模块400;
33、所述构造视频训练集模块100,用于构造无噪声视频s和噪声视频f的视频训练集;
34、所述构造影像模块200,用于采样无噪声视频s和噪声视频f影像帧,构造影像模块
35、所述神经网络模型构建训练模块300,用于神经网络模型构建及基于所述n影像模块对神经网络模型进行训练;
36、所述构造影像模块400,用于应用神经网络模型到噪声视频影像,进行降噪处理。
37、第三方面,在本发明提供的又一个实施例中,提供了一种终端,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器加载并执行所述计算机程序时实现视频卷积降噪方法的步骤。
38、第四方面,在本发明提供的再一个实施例中,提供了一种存储介质,存储有计算机程序,所述计算机程序被处理器加载并执行时实现所述视频卷积降噪方法的步骤。
39、本发明提供的技术方案,具有如下有益效果:
40、本发明提供的视频卷积降噪方法、系统、终端及存储介质,采用视频影像n分段随机稀疏采样的方式,考虑影像帧之间的连续性,捕捉时域噪声;降低视频信息冗余,稀疏化模型架构,提高降噪的反应速度;使用神经网络捕捉噪声,删减式精准降噪,尽量遏制视频影像边缘信息丢失。
41、本发明的这些方面或其他方面在以下实施例的描述中会更加简明易懂。应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
技术特征:
1.一种视频卷积降噪方法,其特征在于,该方法包括:
2.如权利要求1所述的视频卷积降噪方法,其特征在于,所述构造视频训练集包括如下步骤:
3.如权利要求2所述的视频卷积降噪方法,其特征在于,所述采样无噪声视频s和噪声视频f影像帧,构造影像模块包括如下步骤:
4.如权利要求3所述的视频卷积降噪方法,其特征在于,所述神经网络模型构建,包括:
5.如权利要求4所述的视频卷积降噪方法,其特征在于,所述神经网络模型基本结构为:
6.如权利要求4所述的视频卷积降噪方法,其特征在于,所述应用神经网络模型到噪声视频影像,进行降噪处理,具体包括:
7.如权利要求1-6任一所述的视频卷积降噪方法,其特征在于,其中,
8.一种视频卷积降噪系统,其特征在于,该系统包括::构造视频训练集模块、构造影像模块、神经网络模型构建训练模块和视频影像噪声处理模块;
9.一种终端,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器加载并执行所述计算机程序时实现如权利要求1-7任一项所述的视频卷积降噪方法的步骤。
10.一种存储介质,存储有计算机程序,所述计算机程序被处理器加载并执行时实现如权利要求1-7任一项所述的视频卷积降噪方法的步骤。
技术总结
本发明涉及视频处理领域,具体涉及视频卷积降噪方法、系统、终端及存储介质。该方法包括:构造视频训练集,所述视频训练集包括无噪声视频s和噪声视频f;采样无噪声视频s和噪声视频f影像帧,构造影像模块神经网络模型构建及基于所述N影像模块对神经网络模型进行训练;应用神经网络模型到噪声视频影像,进行降噪处理。本发明采用视频影像N分段随机稀疏采样的方式,考虑影像帧之间的连续性,捕捉时域噪声;降低视频信息冗余,稀疏化模型架构,提高降噪的反应速度;使用神经网络捕捉噪声,删减式精准降噪,尽量遏制视频影像边缘信息丢失。
技术研发人员:满宏涛,邹德强
受保护的技术使用者:山东云海国创云计算装备产业创新中心有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!