一种基于动捕的模型训练方法与流程
本发明涉及行为分析,特别是,一种基于动捕的模型训练方法。
背景技术:
1、人体动作捕捉技术,简称动捕技术(motion capture,mocap),是通过某些传感器,捕捉场景中人体运动的姿态或者运动数据,将这些运动姿态数据作为一种驱动数据去驱动虚拟形象模型或者进行行为分析。
2、互联网应用一般通过rgb摄像头或者是rgbd摄像头进行动作捕捉,根据hip根关节点的旋转信息是作为相机外参数,作为人体的朝向(orientation)信息,再根据世界坐标计算出各个骨骼节点的旋转、缩放和位移;然后把参数传递给glb或者vrm模型进行驱动和渲染,形成虚拟形象。
3、现有的动作捕捉技术中,对于人体的朝向信息以及骨骼节点的建立容易造成信息失真,动作误差较大。
技术实现思路
1、本发明公开了一种基于动捕的模型训练方法,用于解决模型的动作和姿态信息失真,提高模型的准确度。
2、本发明提供如下解决方案:一种基于动捕的模型训练方法,包括:
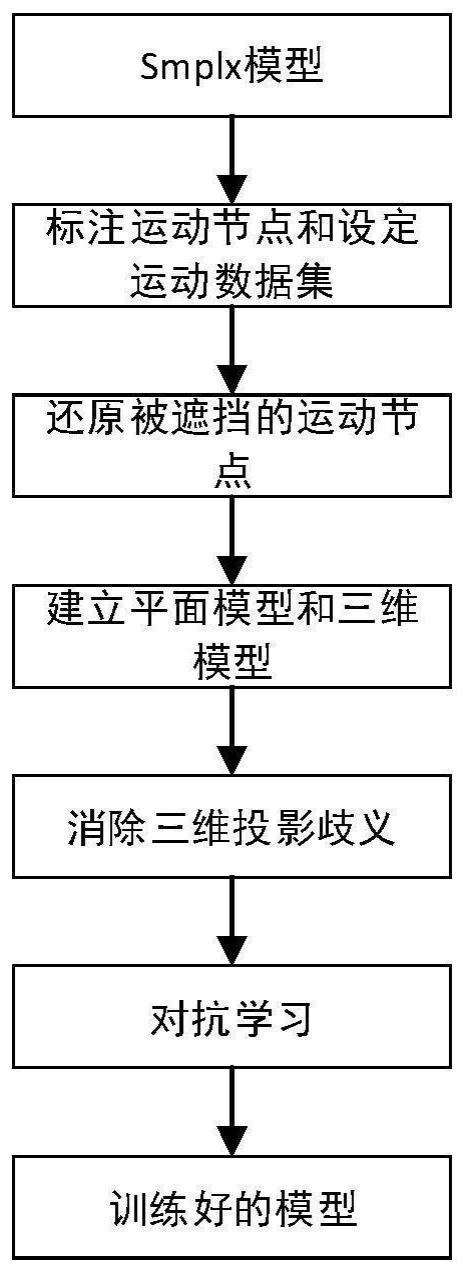
3、预选smplx模型;
4、基于素材视频,标注每一帧的平面数据集中的运动节点;使用重投影损失函数还原被遮挡的运动节点,建立平面模型和投影三维模型;
5、设定若干运动数据集;
6、基于人体的极限动作和姿态,消除三维的投影歧义;
7、设置判别器,根据空间模型的全身动作和全身姿态进行对抗学习,得到人体运动的先验,获取训练好的模型。
8、本发明中,通过重投影损失函数对投影后的空间模型做进一步的误差补偿,还原了被遮挡的运动节点使得之后的模型动作和驱动联动更加流畅,同时基于人体自身的运动极限,即人体的极限动作和姿态信息,使得模型的驱动朝向具有更强的模拟性能,使得在计算机中建立的人体模型的准确大大增强;实现对应的每个骨骼节点的旋转、缩放和位移,为之后的虚拟模型提供良好的驱动基础。
9、依据上述的方案,本发明还可进行的改进为:所述平面数据集为coco数据集。
10、依据上述的方案,本发明还可进行的改进为:基于人体的极限动作和姿态,消除三维的投影歧义,包括:
11、基于人体的极限动作或姿态,降低人体姿态的先验,消除或修正歧义的空间模型。
12、依据上述的方案,本发明还可进行的改进为:根据空间模型的全身动作和全身姿态进行对抗学习,包括:
13、基于人体的极限动作或姿态,选择运动数据集使空间模型模拟人体的姿态和动作,判别并修正不合格的动作姿态。
14、依据上述的方案,本发明还可进行的改进为:还包括:
15、获取视频素材;
16、基于视频中各帧图片的时序rgb信息,消除单帧图片的估计误差。
17、进一步的,基于视频中各帧图片的时序rgb信息,还包括:
18、提取视频中每一帧图片的特征,使用rpn网略生成项目框;
19、从第i帧的项目框出发,在相邻帧的空间领域内寻找最相似的项目框,连接成项目隧道;
20、在相邻的第i帧和第i-1帧之间,两个项目的匹配准则可根据以下公式:
21、
22、其中s()是用于计算两个项目特征的余弦相似度,而l()是用于计算两个项目在尺寸大小及空间位置上的相似程度。x和b分别表示项目特征和项目边界框,字母的上标表示项目编号,表示在第i-1帧搜索区域内的项目框的编号集合;
23、通过加权求和重新融合到对应帧的项目特征中,具体的融合权重可根据以下公式求得:
24、
25、其中,τ代表时序上前后各有τ帧,λ为常数,t表示当前帧;上述公式的做法可以避免无关的特征被错误融合进来。当背景框被连接到了关节模型的隧道当中,他们的特征相似度较低,所以最后产生的融合权重较小,从而防止了关节特征被背景特征所污染,反之亦然;
26、得出无遮挡的关节模型视频。
27、依据上述的方案,本发明还可进行的改进为:获取视频素材,还包括:
28、使用非监督学习深度模型cnns模型进行预测单张图片的深度。
29、进一步的,使用非监督学习深度模型cnns模型进行预测单张图片的深度,包括:
30、基于如下公式定义人体肢干的长度:
31、
32、其中,f是焦距,可以简单设为参数,不影响整体比例;是2d姿态估计推理出来的平面关节点,而是该帧所有2d姿态估计的平均值,其中νi是可见形参数,判断是否关节点可见,因此,vi∈[0,1]k,有
33、
34、ki∈r3是估计出来的3d关节点,是该帧所有3d关节点的空间坐标的平均值,有:
35、
36、依据上述的方案,本发明还可进行的改进为:还包括:
37、用mediapipe holistic识别并得出连接节点中对应人体部位的特征点。
38、依据上述的方案,本发明还可进行的改进为:人体部位包括:脸、虹膜、手部或手指、躯干和四肢。
39、依据上述的方案,本发明还可进行的改进为:合并特征点到空间模型中,用于实现运动节点的实时驱动。
40、采用本发明的技术方案,具有如下有益效果:
41、1)原有的视频素材中,24个关节点在视频中不一定全部可见,会出现被遮挡的情况,通过重投影函数,通过使用重投影损失函数,把被遮挡部分的关节点预测还原出来,使各个关节点都清晰地连接得起来;同时通过模型的对抗损失以及人体的极限动作和姿态信息,获得的人体先验可以辅助建立空间模型的驱动数据和联动参数,方便后期的渲染。
42、2)根据视频各帧的时序rgb图片信息,消除遮挡导致的单帧估计误差,对被遮挡的关节点大致位置进行估计,因而提高了鲁棒性。
技术特征:
1.一种基于动捕的模型训练方法,其特征在于,包括:
2.依据权利要求1所述的一种基于动捕的模型训练方法,其特征在于,所述平面数据集为coco数据集。
3.依据权利要求1所述的一种基于动捕的模型训练方法,其特征在于,基于人体的极限动作和姿态,消除三维的投影歧义,包括:
4.依据权利要求1所述的一种基于动捕的模型训练方法,其特征在于,根据空间模型的全身动作和全身姿态进行对抗学习,包括:
5.依据权利要求1所述的一种基于动捕的模型训练方法,其特征在于,还包括:
6.依据权利要求5所述的一种基于动捕的模型训练方法,其特征在于,基于视频中各帧图片的时序rgb信息,还包括:
7.依据权利要求5所述的一种基于动捕的模型训练方法,其特征在于,获取视频素材,还包括:
8.依据权利要求1所述的一种基于动捕的模型训练方法,其特征在于,还包括:用mediapipe holistic识别并得出连接节点中对应人体部位的特征点。
9.依据权利要求8所述的一种基于动捕的模型训练方法,其特征在于,
10.依据权利要求8所述的一种基于动捕的模型训练方法,其特征在于,
技术总结
一种基于动捕的模型训练方法,涉及行为分析技术领域。包括:预选smplx模型;基于素材视频,标注每一帧的平面数据集中的运动节点;使用重投影损失函数还原被遮挡的运动节点,建立平面模型和投影三维模型;设定若干运动数据集;基于人体的极限动作和姿态,消除三维的投影歧义;设置判别器,根据空间模型的全身动作和全身姿态进行对抗学习,得到人体运动的先验,获取训练好的模型。通过使用重投影损失函数,把被遮挡部分的关节点预测还原出来,使各个关节点都清晰地连接得起来;同时通过模型的对抗损失以及人体的极限动作和姿态信息,获得的人体先验可以辅助建立空间模型的驱动数据和联动参数,方便后期的渲染。
技术研发人员:李森和
受保护的技术使用者:广州扎加信息科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!