一种多源地址信息识别方法及装置与流程
本文涉及文本识别领域,尤其涉及一种多源地址信息识别方法及装置。
背景技术:
1、在企业数据治理过程中,如何对非结构化数据进行有效治理,是影响数据治理整体效果的关键因素。文本数据作为非结构化数据的典型代表,具有规模庞大、价值密度低、利用难度高等特点。因此,如何有效对文本数据进行处理,高效提取其中有价值的信息,是数据治理过程中必不可少的一环。
2、现有技术中,对于文本数据中地址实体的识别主要有如下两种方法:
3、一种是利用传统的神经网络模型(cnn、rnn)进行实体地址识别,该种方法无法解决自然语言句子中的长程依赖等问题,从而存在识别的准确率低的问题,另该方法不适用于电网数据的地址识别,未对同一用户在不同数据表中的地址进行匹配,进而无法确定用户在不同数据表中地址的正确性。
4、另一种是利用模糊查询方法匹配地址,该方法在面对复杂的文本数据时,存在识别效率低及灵活度低的问题,另该方法同样不适用于电网数据的地址识别,未对同一用户在不同数据表中的地址进行匹配。
技术实现思路
1、本文用于解决现有技术中文本中地址识别存在准确率出差及效率低的问题,以及无法核查各用户在各数据表中地址信息的一致性。
2、为了解决上述技术问题,本文一方面提供一种多源地址信息识别方法,包括:
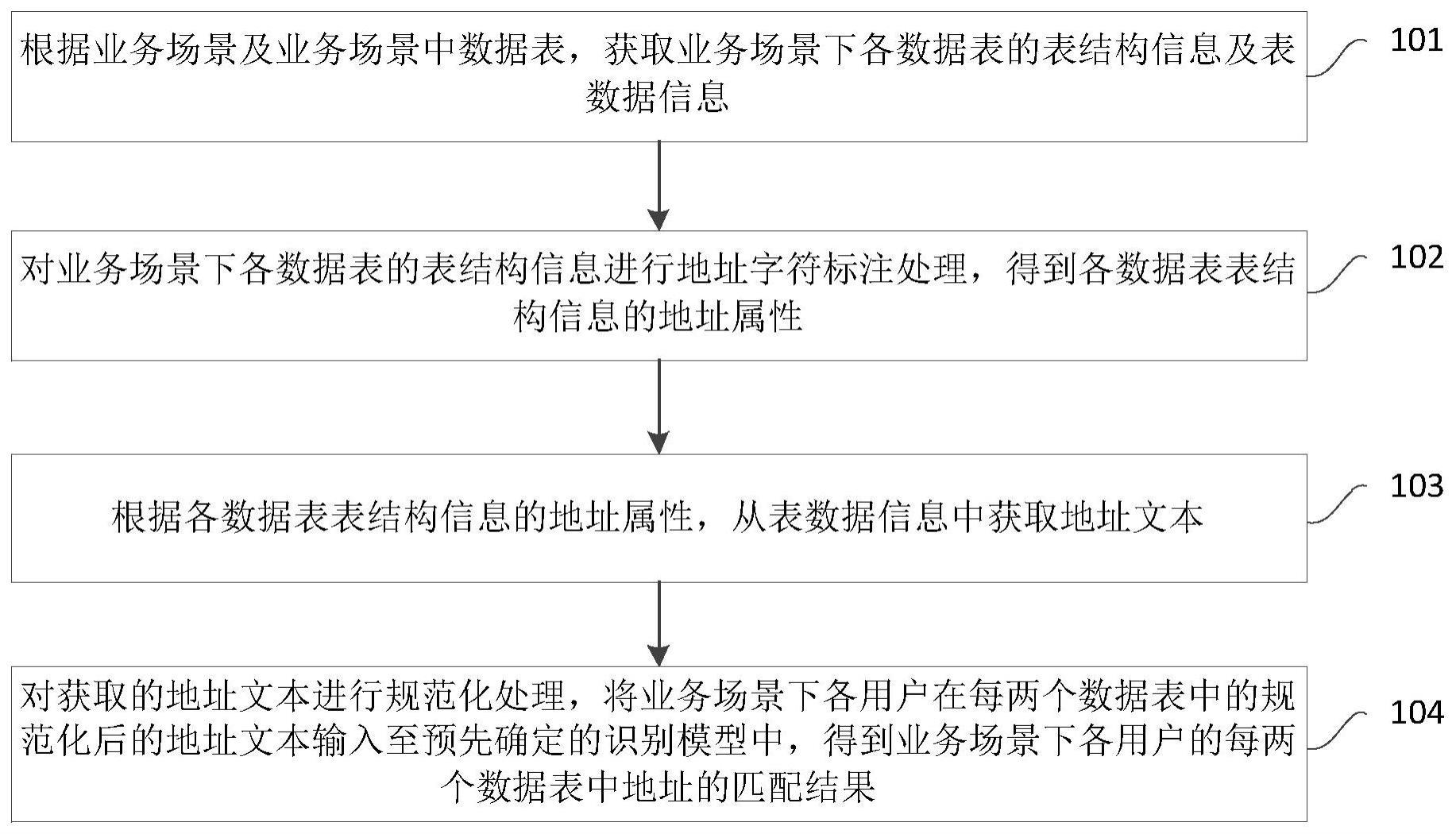
3、根据业务场景及业务场景中数据表,获取业务场景下各数据表的表结构信息及表数据信息;
4、对业务场景下各数据表的表结构信息进行地址字符标注处理,得到各数据表表结构信息的地址属性;
5、根据各数据表表结构信息的地址属性,从表数据信息中获取地址文本;
6、对获取的地址文本进行规范化处理,将业务场景下各用户在每两个数据表中的规范化后的地址文本输入至预先确定的识别模型中,得到业务场景下各用户的每两个数据表中地址的匹配结果;
7、其中,所述识别模型包括:词向量转换模型及地址文本语义匹配模型,词向量转换模型用于将规范化后的地址文本转换为词向量,地址文本语义匹配模型用于计算每两个数据表地址文本的词向量之间的匹配结果。
8、作为本文进一步实例中,对业务场景下各数据表的表结构信息进行地址字符标注处理,得到各数据表表结构信息的地址属性,包括:
9、对业务场景下各数据表的表结构信息进行地址字符标注处理;
10、提取各数据表表结构信息的标注结果中表示地址字符的标注结果,得到各数据表的地址属性。
11、作为本文进一步实例中,对业务场景下各数据表的结构信息进行地址字符标注处理,包括:
12、根据预设规范地址,识别业务场景下各数据表的结构信息中的地址字符;
13、设置首个地址字符为第一标识,其余地址字符为第二标识;
14、设置各数据表的结构信息中的非地址字符为第三标识。
15、作为本文进一步实例中,对地址文本进行规范化处理,包括:
16、根据地址俗称库,将地址文本中的地址俗称替换为标准地址,其中,地址俗称库中存储有地址俗称与标准地址之间的关联关系;
17、对地址文本进行繁转简及重复文字删除处理,得到规范化的地址文本。
18、作为本文进一步实例中,所述词向量转换模型为word2vec模型,所述地址文本语义匹配模型为esim模型。
19、作为本文进一步实例中,多源地址信息识别方法还包括:
20、对于匹配结果为失败的用户及数据表,建立核查信息;
21、将核查信息发送至业务人员处理。
22、本文第二方面提供一种多源地址信息识别装置,包括:
23、信息获取单元,用于根据业务场景及业务场景中数据表,获取业务场景下各数据表的表结构信息及表数据信息;
24、地址标注单元,用于对业务场景下各数据表的表结构信息进行地址字符标注处理,得到各数据表表结构信息的地址属性;
25、地址文本获取单元,用于根据各数据表表结构信息的地址属性,从表数据信息中获取地址文本;
26、规范化处理及匹配单元,用于对获取的地址文本进行规范化处理,将业务场景下各用户在每两个数据表中的规范化后的地址文本输入至预先确定的识别模型中,得到业务场景下各用户的每两个数据表中地址的匹配结果;
27、其中,所述识别模型包括:词向量转换模型及地址文本语义匹配模型,词向量转换模型用于将规范化后的地址文本转换为词向量,地址文本语义匹配模型用于计算每两个数据表地址文本的词向量之间的匹配结果。
28、本文第三方面提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现前述任一示例所述方法。
29、本文第四方面提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被计算机设备的处理器执行时实现前述任一实施例所述方法。
30、本文第五方面提供一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序被计算机设备的处理器执行时实现前述任一实施例所述的方法。
31、本文提供的多源地址信息识别方法及装置,适用于电网数据中多源地址信息,通过根据业务场景及业务场景中数据表,获取业务场景下各数据表的表结构信息及表数据信息;对业务场景下各数据表的表结构信息进行地址字符标注处理,得到各数据表表结构信息的地址属性;根据各数据表表结构信息的地址属性,从表数据信息中获取地址文本,能够解决当前电网数据中地址信息数据量庞大,无法全量进行地址数据信息质量核查和数据治理的问题,以业务场景为单位开展数据规范化处理及获取,能够提高地址文本的获取效率及准确性,解决实际生产中,地址信息治理工作的难以开展的难点。通过对获取的地址文本进行规范化处理,将业务场景下各用户在每两个数据表中的规范化后的地址文本输入至预先确定的识别模型中,得到业务场景下各用户的每两个数据表中地址的匹配结果,进而根据匹配结果可确定用户地址的一致性。
32、为让本文的上述和其他目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附图式,作详细说明如下。
技术特征:
1.一种多源地址信息识别方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,对业务场景下各数据表的表结构信息进行地址字符标注处理,得到各数据表表结构信息的地址属性,包括:
3.如权利要求2所述的方法,其特征在于,对业务场景下各数据表的结构信息进行地址字符标注处理,包括:
4.如权利要求1所述的方法,其特征在于,对地址文本进行规范化处理,包括:
5.如权利要求1所述的方法,其特征在于,所述词向量转换模型为word2vec模型,所述地址文本语义匹配模型为esim模型。
6.如权利要求1所述的方法,其特征在于,还包括:
7.一种多源地址信息识别装置,其特征在于,包括:
8.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至6任意一项所述方法。
9.一种计算机存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被计算机设备的处理器执行时实现权利要求1至6任意一项所述方法。
10.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机程序,所述计算机程序被计算机设备的处理器执行时实现权利要求1至6任意一项所述方法。
技术总结
本文提供了一种多源地址信息识别方法及装置,方法包括:根据业务场景及业务场景中数据表,获取业务场景下各数据表的表结构信息及表数据信息;对业务场景下各数据表的表结构信息进行地址字符标注处理,得到各数据表表结构信息的地址属性;根据各数据表表结构信息的地址属性,从表数据信息中获取地址文本;对获取的地址文本进行规范化处理,将业务场景下各用户在每两个数据表中的规范化后的地址文本输入至预先确定的识别模型中,得到业务场景下各用户的每两个数据表中地址的匹配结果。本文能够对电网数据中的地址数据信息质量进行全面核查,通过确定业务场景下各用户的每两个数据表中地址的匹配结果可确定用户地址的一致性。
技术研发人员:王艺霏,马跃,梁东,娄竞,邢宁哲,李信,陈重韬,王骏,王畅,温馨,张海明,尚芳剑,李欣怡,梁潇,刘卫卫,姚艳丽,王森,庞思睿,苏丹,那琼澜,周子阔,姜蕴洲,曲洪泽,王晓慧,黄复鹏,安宁钰,雷舒娅,张文思
受保护的技术使用者:国网冀北电力有限公司信息通信分公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!