一种基于安全多方计算技术的隐私保护实体识别工具
本发明涉及信息安全,尤其涉及一种基于安全多方计算技术的隐私保护实体识别工具。
背景技术:
1、隐私保护实体识别旨在匹配出来自不同数据库的两条记录是否属于真实世界的同一个实体,同时不会暴露敏感信息。在大规模预训练语言模型bert的支撑下,实体记录之间的相似度判别可以不仅仅受限于文本层面,还能受益于可以捕获语义的深度神经网络架构,因此实体识别本身的效率有了很大的提升。而如何在保护隐私信息的条件下,高效地完成bert上的实体识别任务,就成为了一个亟待解决的问题。
2、现有的解决方案要么适用于很少有非线性操作的小模型,要么适用于非机器学习的低效实体识别方案。将安全多方计算技术引入实体识别任务是一个新颖的方案,它可以让每个参与方在不获取任何明文信息的情况下,独立完成bert模型上的实体识别计算任务。我们采用了安全多方计算中的秘密共享技术,该技术具有信息论安全性和密码学安全性的双重保护。在此技术中,利用随机数和对应的加密算法,使得每个参与方拥有原始数据的一部分密文份额,而当且仅当所有的密文份额都被获取到后,原始明文才能被正确恢复。
3、现有技术存在一种安全多方计算技术应用于机器学习模型的工具crypten,它提供了基本的安全多方计算和通信原语,以及一些神经网络中出现的非线性函数的多项式近似算法。crypten提供模型加密和数据加密两个模块,模型通过安全类注册以及参数秘密共享来实现,数据通过直接进行秘密共享实现。由于秘密共享协议只具有同台可加性,对于神经网络中出现的e指数、倒数、平方根等非线性模块,采用牛顿-拉普森迭代、豪斯霍尔德迭代等算法进行近似。
4、但该技术存在如下问题:
5、首先,bert模型含有需要明文索引的词嵌入模块,现有技术crypten很难应用于其上,使得秘密共享份额能够与加密模型的输入端所匹配。其次,由于bert模型的维度大,层数深,crypten中的很多近似算法在bert模型计算的过程中不收敛,导致整个模型输出错误结果。最后,crypten没有覆盖一个完整的实体识别任务流程,缺少实体识别任务中的预分块步骤。
6、本发明解决的问题是:如何在大规模语言模型bert上正确、稳定地应用安全多方计算方法,以完成隐私保护实体识别任务,并且不损失实体识别的准确度。
7、具体来说,实现bert模型中的明文词嵌入模块与安全多方计算技术的匹配,不易收敛的高敏感模块(hsm)的优化,以及带有隐私保护的实体识别预分块模块的设计。
技术实现思路
1、为此,本发明首先提出一种基于安全多方计算技术的隐私保护实体识别工具,
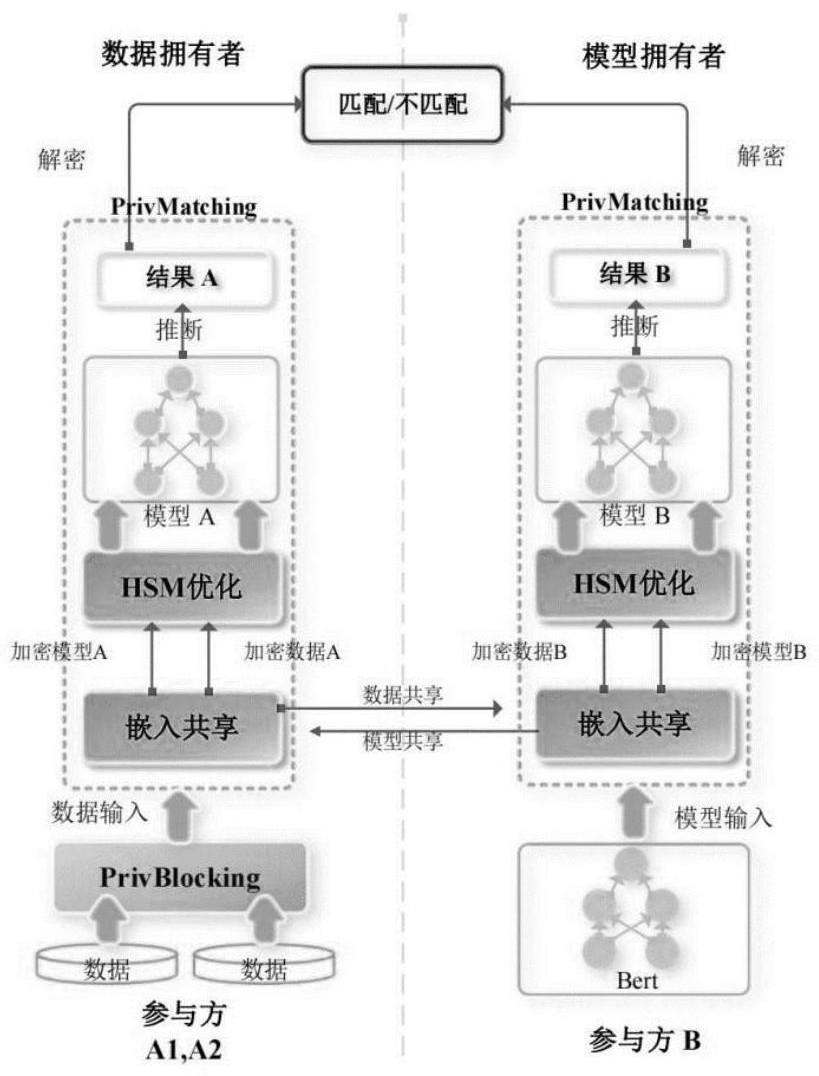
2、包含嵌入矩阵共享、高敏感模块优化以及隐私保护预分块三个模块;
3、所述嵌入矩阵共享模块采用嵌入共享算法处理模型,通过对电商平台作为模型拥有者提供的共享嵌入矩阵进行索引,获得高维词矩阵;
4、所述高敏感模块优化模块对现有的bert模型中的四种高敏感模块进行优化,并使用秘密共享协议对数据和模型进行加密,参与者各自获得数据和模型的一半密文,并通过密文推理阶段,每个参与方独立地计算自己的密文各自独立地进行密文上的计算操作;
5、所述隐私保护预分块模块对两个计算参与方得到各自对应的一半结果a和结果b,并通过秘密共享协议的解密算法得到完整的明文结果“0”或“1”,即在电商活动各方都不暴露自己信息的情况下,通过相似度计算得出实体“匹配”或“不匹配”,即是否属于同一实体的结论。
6、所述公向算法处理模型当存在一个数据对s和一个经过微调的模型m时,模型拥有者首先将其embedding层参数共享给数据拥有者,数据拥有者使用特定的分词器将数据对划分为tokens,然后,对于每个token,使用查找表来获得训练阶段得到的embedding矩阵,以及其他bert模型特有的embedding,经过嵌入部分后,再进行层的归一化操作,最后应用秘密共享技术为数据拥有者和模型拥有者各自生成秘密共享份额;在加密数据集的embedding得到数据共享份额之后对模型加密,得到加密模型。
7、所述其他bert模型特有的embedding包括位置、标记类型。
8、所述现有的四种高敏感模块进行优化具体包括,首先对softmax函数进行优化,当上一层的输入进入softmax模块时,首先对其进行解密,让数据拥有者和模型拥有者得到softmax的明文输入,分别独立进行明文上的softmax计算,最后将结果重新利用秘密共享协议加密;
9、其次对平方根函数进行优化,首先引入一个因子r,利用此因子将原始值缩小到对应的收敛范围内,通过小范围的平方根逼近函数处理之后,再对结果乘以因子r,得到最终结果。我们在输入值上首先做max操作,判断最大值是否超过迭代次数为6时的收敛上界,若超过,便按照10的倍数设定因子r,从而动态扩展设置近似函数的收敛域;
10、之后对倒数的多项式近似优化,使用newton-raphson迭代法:
11、
12、首先在初始化阶段,由于此近似算法的收敛条件为:并设定初始值y0(x)=3e0.5-x;
13、最后对bert中的激活函数进行优化,使用gelu作为默认激活函数,其中包含高斯误差函数erf:
14、
15、并设置gelu函数的近似:x*sigmoid(1.702x)。
16、所述隐私保护预分块模块采用privblocking算法,对每个数据拥有者都保存一个原始数据库或表,这些数据库或表是方案感知的或方案感知的,首先进行预处理,使每个记录都是一个纯文本,去除属性界限,其余部分将同步在不同的数据拥有者上使用相同的方法执行,对于每个记录,使用bert的tokenizer生成token列表,并创建一个bloom过滤器结构,然后,对于每个token,通过不同的哈希函数将“1”生成到相应的bloom过滤器位置,在这个迭代结束时,每条数据都将持有一个只有“1”和“0”的bloom过滤器;
17、在每个数据拥有者获得其私有的bloom过滤器后,进行笛卡尔积,并获得可能匹配的索引对[x,y],而不泄漏敏感信息,最后,通过检查在相同的对应位置中有多少个“1”,并使用阈值s,锁定减少的候选对索引。
18、本发明所要实现的技术效果在于:
19、提出了一个兼具稳定性和鲁棒性的隐私保护实体识别框架priber,能够在bert模型上采用安全多方计算技术执行实体识别二分类任务,并且不牺牲实体识别本身的准确性。
技术特征:
1.一种基于安全多方计算技术的隐私保护实体识别工具,通过输入电商平台各方数据,计算参与各方是否属于同一实体,其特征在于:包含嵌入矩阵共享、高敏感模块优化以及隐私保护预分块三个模块;
2.如权利要求1所述的一种基于安全多方计算技术的隐私保护实体识别工具,其特征在于:所述公向算法处理模型当存在一个数据对s和一个经过微调的模型m时,模型拥有者首先将其embedding层参数共享给数据拥有者,数据拥有者使用特定的分词器将数据对划分为tokens,然后,对于每个token,使用查找表来获得训练阶段得到的embedding矩阵,以及其他bert模型特有的embedding,经过嵌入部分后,再进行层的归一化操作,最后应用秘密共享技术为数据拥有者和模型拥有者各自生成秘密共享份额;在加密数据集的embedding得到数据共享份额之后对模型加密,得到加密模型。
3.如权利要求2所述的一种基于安全多方计算技术的隐私保护实体识别工具,其特征在于:所述其他bert模型特有的embedding包括位置、标记类型。
4.如权利要求2所述的一种基于安全多方计算技术的隐私保护实体识别工具,其特征在于:所述现有的四种高敏感模块进行优化具体包括,首先对softmax函数进行优化,当上一层的输入进入softmax模块时,首先对其进行解密,让数据拥有者和模型拥有者得到softmax的明文输入,分别独立进行明文上的softmax计算,最后将结果重新利用秘密共享协议加密;
5.如权利要求4所述的一种基于安全多方计算技术的隐私保护实体识别工具,其特征在于:所述隐私保护预分块模块采用privblocking算法,对每个数据拥有者都保存一个原始数据库或表,这些数据库或表是方案感知的或方案感知的,首先进行预处理,使每个记录都是一个纯文本,去除属性界限,其余部分将同步在不同的数据拥有者上使用相同的方法执行,对于每个记录,使用bert的tokenizer生成token列表,并创建一个bloom过滤器结构,然后,对于每个token,通过不同的哈希函数将“1”生成到相应的bloom过滤器位置,在这个迭代结束时,每条数据都将持有一个只有“1”和“0”的bloom过滤器;
技术总结
本发明通过网络安全领域的方法,实现了一种基于安全多方计算技术的隐私保护实体识别工具。包含嵌入矩阵共享、高敏感模块优化以及隐私保护预分块三个模块;嵌入矩阵共享模块获得高维词矩阵;高敏感模块优化模块对现有的四种高敏感模块进行优化;所述隐私保护预分块模块对两个计算参与方得到各自对应的一半结果A和结果B,并通过秘密共享协议的解密算法得到完整的明文结果“0”或“1”,即实体“匹配”或“不匹配”。本发明提供的方法提出了一个兼具稳定性和鲁棒性的隐私保护实体识别框架PRIBER,能够在Bert模型上采用安全多方计算技术执行实体识别二分类任务,并且不牺牲实体识别本身的准确性。
技术研发人员:李牧,孙明正,冯逸骏,杨心怡
受保护的技术使用者:北京航空航天大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!