一种基于图核的文本数据分类方法
本发明涉及自然语言处理领域,具体涉及一种基于图核的文本数据分类方法。
背景技术:
1、文本分类是自然语言处理中的一项重要任务。该任务被广泛应用于新闻文本分析、情感分析、垃圾邮件检测等多个领域。如何更好地识别出用户需要的文本以及不需要的文本是文本分类领域关注的重点。文本分类利用标注数据(即已知类别信息的数据)进行模型训练,最终实现对未知文本的分类。通常,这种操作涉及对两个文档之间的相似度进行比较,因此文档相似度在该领域中起着重要作用。我们可以使用图结构来捕获文档之中的文本信息和结构信息,通过图核进行相似度测量,帮助用户获取所需要的新闻文本或者对垃圾邮件进行屏蔽。
2、使用图核技术对文档进行分类是近年来文本分类领域的常用手段。通过将文档表示为单词图,我们可以更好地捕获文档的文本信息(比如一个单词在文档内出现的次数)和结构信息(比如两个单词在文档内的关系),从而对这些关系进行建模。在单词图中,每个单词表示为图中的一个节点,单词之间的关系由节点之间的边表示。通过使用改进的图核方法,我们可以对两个文档进行相似性度量。同时我们可以将单词图转换成邻接矩阵和对角矩阵将文档的特征信息呈现给用户,方便用户更直观地了解文档内各单词的关联程度以及重要程度。使用图核对文档进行相似性度量的重点是捕获足够的文本信息和结构信息。然而,目前存在的一些图核方法并没有充分利用这些信息。过去的基于图核的方法只关注文档转换而成的单词图本身,并没有利用单词图存储文本信息和结构信息,这导致过去方法的准确率不能完全满足用户的需求。同时,随着用户对使用体验的愈发关注,现有的一些高精度方法并不能很好地满足用户在这方面的需求。
技术实现思路
1、本发明的主要目的是提供一种基于图核的文本数据分类方法,涉及算法将文档的文本信息和结构信息保存至单词图中,并提出一种新的图核方法对文档进行相似性度量,满足用户对文本分类的高准确率以及高运行效率和低存储占用的需求。
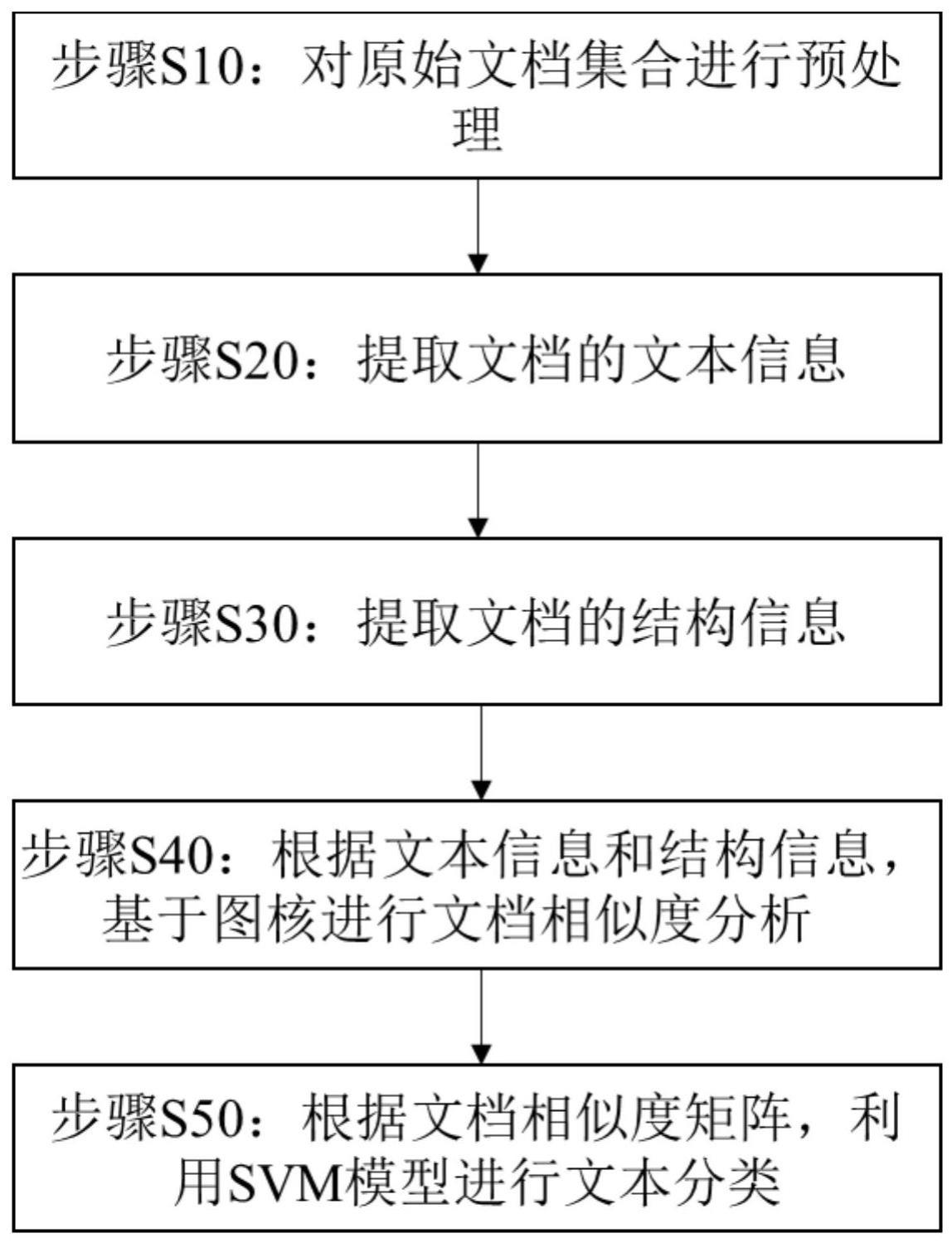
2、根据本发明的第一方面,提供一种基于图核的文本数据分类方法,其特征在于,包括:
3、步骤s10:对原始文档集合进行预处理。
4、步骤s20:提取文档的文本信息,包括步骤s21-s22。
5、步骤s21:提取每个单词的基于熵的加权值,即bdc值
6、
7、其中,t是单词,|c|是类别数,p(t|ci)是单词t在类别ci中所占的比率。
8、步骤s22:使用降序排列构建单词和bdc值一一对应的字典。
9、步骤s30:提取文档的结构信息,包括步骤31-32。
10、步骤s31:基于词共现窗口w,将文档转换成单词图g=(v,e),其中,v={v1,v2,…,vn}表示单词转换而成的顶点集合,e={e1,e2,…,en}表示顶点之间的边的集合。
11、步骤s32:对集合e中的边赋值为其中,nei表示边ei在单词图g中出现的次数,max(ne1,ne2,…,nen)表示出现次数最多的边。
12、步骤s40:根据文本信息和结构信息,基于图核进行文档相似度分析,包括步骤41-42。
13、步骤41:将单词图g转换成邻接矩阵a和对角矩阵d,a中存储g的边值,即me值,d中存储g的顶点值,即单词的bdc值。
14、步骤42:使用改进的图核方法计算单词图g1=(v1,e1)和单词图g2=(v2,e2)的文档相似度
15、
16、其中,norm=‖a1+d1‖f×‖a2+d2‖f,用于对得到的图核值进行归一化;a1和a2是图g1和g2的邻接矩阵,存储两个单词图的结构信息,d1和d2是图g1和g2的对角矩阵,存储两个单词图的文本信息,||.||f是矩阵的f范数。使用对角矩阵d1和d2中的值计算两个单词图之间的knode值。若顶点vi和顶点vj是同一个单词,则和表示顶点vi和vj在图g1和g2中的度数(即它和几个顶点相连),和表示顶点vi和vj的bdc值。若顶点vi和顶点vj不是同一个单词,则knode(vi,vj)=0。
17、使用邻接矩阵a1和a2中的值计算两个单词图之间的kedge值,若边ei连接的两个顶点vm和vn与边ej连接的两个顶点v′m和v′n的单词是相同的,则若边ei连接的两个顶点的单词与边ej连接的两个顶点的单词是不同的,则kedge(ei,ej)=0。
18、步骤s50:根据文档相似度矩阵,利用svm模型进行文本分类。
19、进一步地,本发明所提供的基于图核的文本数据分类方法,其特征在于,步骤s10包括:加载数据集,获取文档的标签与内容,去除内容里面的标点符号、停用词、频率过高或者过低的词。
20、进一步地,本发明所提供的基于图核的文本数据分类方法,其特征在于,步骤s50包括:基于训练文档集合的文档相似度矩阵训练svm模型,保存训练得到的svm模型以及最优的惩罚参数p;根据最优的惩罚参数p使用svm模型对文档进行分类。
21、根据本发明的第二方面,提供一种计算机设备,其特征在于,包括:
22、存储器,用于存储指令;处理器,用于调用所述存储器存储的指令执行第一方面的基于图核的文本数据分类方法。
23、根据本发明的第三方面,提供一种计算机可读存储介质,其特征在于,存储有指令,所述指令被处理器执行时,执行第一方面的基于图核的文本数据分类方法。
24、与现有技术相比,本发明所构思的上述技术方案至少具有以下有益效果:
25、(1)本发明的基于图核的文本数据分类方法,适用于各种类型的文本分类,有助于根据用户不同的需求实现不同的文本分类模型,帮助用户更加精准的获得所需要的文本以及屏蔽垃圾文本,满足用户对垃圾信息屏蔽以及新闻文本分析方面的需求。
26、(2)本发明使用的图核改进方法,能够更快更方便的满足用户的需求,对用户的计算机硬件配置要求低,占用的用户计算机资源更少,用户的使用体验将会更好。
27、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
技术特征:
1.一种基于图核的文本数据分类方法,其特征在于,包括:
2.根据权利要求1所述的基于图核的文本数据分类方法,其特征在于,步骤s10包括:
3.根据权利要求1所述的基于图核的文本数据分类方法,其特征在于,步骤s50包括:
4.一种计算机设备,其特征在于,包括:
5.一种计算机可读存储介质,其特征在于,存储有指令,所述指令被处理器执行时,执行如权利要求1-3中任一项所述的基于图核的文本数据分类方法。
技术总结
本发明公开了一种基于图核的文本数据分类方法,用于在保证高分类准确率的同时提升计算效率并降低内存消耗,该发明主要包括获取文档的文本信息和结构信息,将文档转换成单词图,使用图核方法对两个文档进行相似度度量,获得文档集的相似度矩阵;将相似度矩阵作为输入数据传入SVM进行模型训练,通过SVM模型对未知文档进行分类。该方法的目的是在保证用户更好的使用体验的前提下,为用户提供一种高准确率的文本分类方法,方便用户获取自己需要的文档以及屏蔽自己不需要的文档。
技术研发人员:朱坛,杨帆
受保护的技术使用者:中南林业科技大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!