处理生僻字一字多码的方法、装置、设备和介质与流程
本公开涉及金融科技,更具体地,涉及一种处理生僻字一字多码的方法、装置、设备、介质和程序产品。
背景技术:
1、生僻字包括日常生活中用的比较少的汉字。生僻字往往具有书写比较复杂,读字发音不易掌握的特点。对软、硬件系统而言,生僻字主要是指软、硬件环境使用的字符集不能够支持的汉字,例如gbk字符集范围之外的汉字字符,字符集iso/iec 10646-1993汉字集(u+4e00~u+9fa5,20902字)外的字符。
2、对于生僻字,人眼认为字形相同,但可能同一个生僻字存在不同的编码,所以计算机认为不同,导致计算机在处理具有不同编码的生僻字过程中存在一定的难度,影响客户体验。
技术实现思路
1、鉴于上述问题,本公开提供了一种处理生僻字一字多码的方法、装置、设备、介质和程序产品。
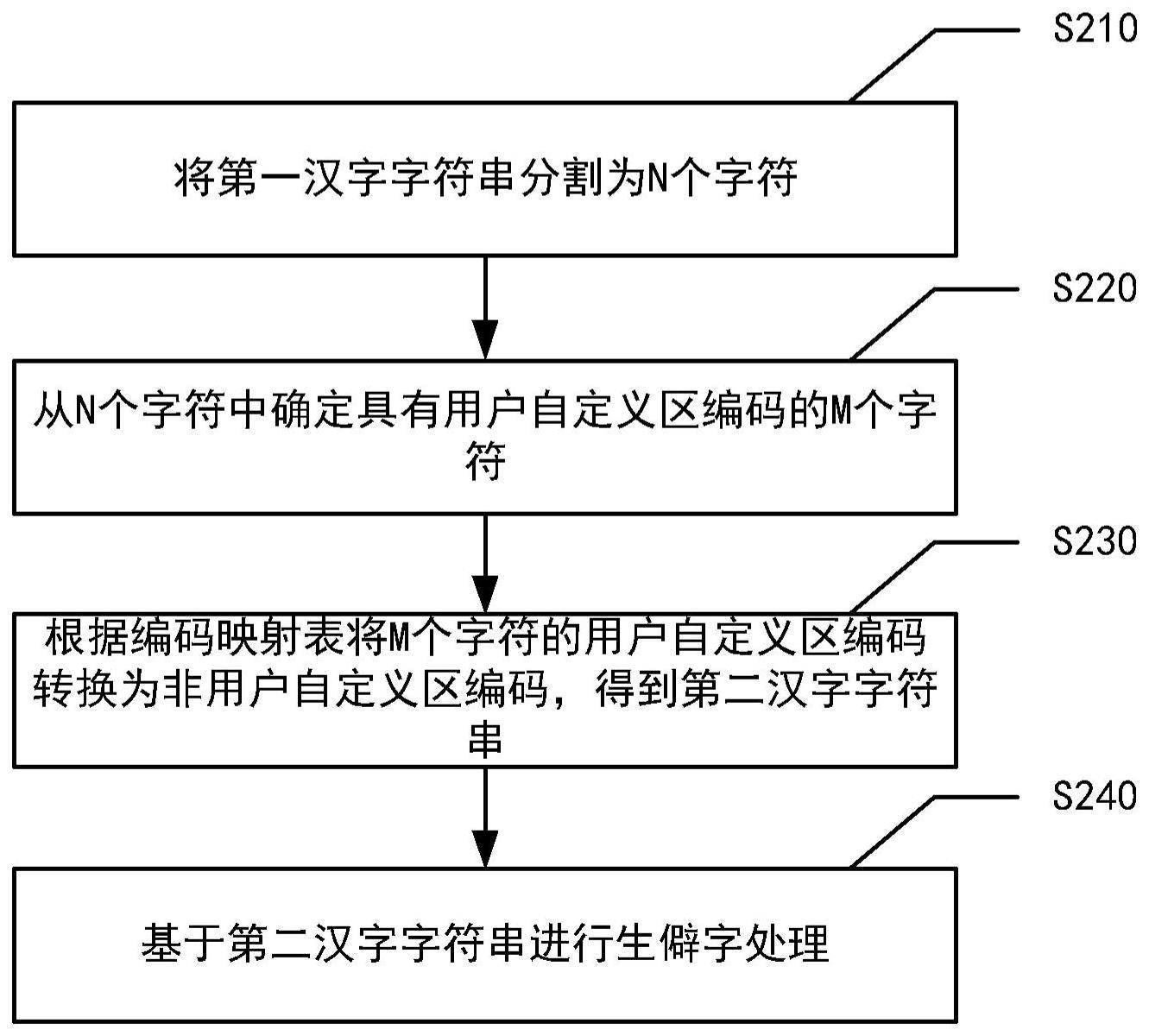
2、本公开实施例的一个方面提供了一种处理生僻字一字多码的方法,包括:将第一汉字字符串分割为n个字符,n大于或等于1;从所述n个字符中确定具有用户自定义区编码的m个字符,m小于或等于n;根据编码映射表将所述m个字符的用户自定义区编码转换为非用户自定义区编码,得到第二汉字字符串,其中,所述编码映射表中包括所述m个字符中每个字符的用户自定义区编码与非用户自定义区编码的映射关系;基于所述第二汉字字符串进行生僻字处理。
3、根据本公开的实施例,在根据编码映射表将所述m个字符的用户自定义区编码转换为非用户自定义区编码之前,还包括:从预先存储位置获取所述编码映射表,其中,所述预先存储位置包括内存、网络云端、共享数据库或非共享数据库中至少一个。
4、根据本公开的实施例,所述基于所述第二汉字字符串进行生僻字处理包括:将第三汉字字符串分割为s个字符,s大于或等于1;从所述s个字符中确定具有用户自定义区编码的k个字符,k小于或等于s;根据所述编码映射表将所述k个字符的用户自定义区编码转换为所述非用户自定义区编码;比较转换后的所述第三汉字字符串和所述第二汉字字符串。
5、根据本公开的实施例,所述第一汉字字符串和所述第三汉字字符串来自不同的平台系统,所述不同的平台系统包括来自不同机构或不同版本的软硬件环境。
6、根据本公开的实施例,所述基于所述第二汉字字符串进行生僻字处理包括:根据所述第二汉字字符串进行数据库查询和/或联网核查,其中,所述联网核查用于查询用户关联的身份信息。
7、根据本公开的实施例,所述进行数据库查询和/或联网核查包括:将所述第一汉字字符串和所述第二汉字字符串分别作为查询条件。
8、根据本公开的实施例,所述n个字符中除m个字符以外的其他字符皆具有所述非用户自定义区编码,所述基于所述第二汉字字符串进行生僻字处理包括:将所述第二汉字字符串的所述非用户自定义区编码进行存储。
9、根据本公开的实施例,所述从所述n个字符中确定具有用户自定义区编码的m个字符包括:将所述n个字符中每个字符转换为统一码;将所述每个字符的统一码在所述编码映射表中进行查询;确定在所述编码映射表中查询到的所述m个字符。
10、根据本公开的实施例,所述方法还包括:若所述m个字符中至少一个字符为非用户自定义区编码,将所述至少一个字符皆转换为用户自定义区编码,得到第四汉字字符串;根据所述第二汉字字符串和/或所述第四汉字字符串进行数据库查询和/或联网核查,其中,所述联网核查用于查询用户关联的身份信息。
11、本公开实施例的另一方面提供了一种处理生僻字一字多码的装置,包括:字符分割模块,用于将第一汉字字符串分割为n个字符,n大于或等于1;生僻字确定模块,用于从所述n个字符中确定具有用户自定义区编码的m个字符,m小于或等于n;编码转换模块,用于根据编码映射表将所述m个字符的用户自定义区编码转换为非用户自定义区编码,得到第二汉字字符串,其中,所述编码映射表中包括所述m个字符中每个字符的用户自定义区编码与非用户自定义区编码的映射关系;生僻字处理模块,用于基于所述第二汉字字符串进行生僻字处理。
12、本公开实施例的另一方面提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行如上所述的方法。
13、本公开实施例的另一方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行如上所述的方法。
14、本公开实施例的另一方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如上所述的方法。
15、上述一个或多个实施例具有如下有益效果:加载编码映射表仅耗费极低的计算资源即可,能够加快处理生僻字的速度。对于待处理的第一汉字字符串进行拆分,若存在用户自定义区编码的m个字符,则认为该m个字符为生僻字,可以调用编码映射表根据映射关系转换得到m个字符的非用户自定义区编码。计算机可以按照统一的编码进行生僻字规范处理,减少重复开发,降低开发难度,且实现逻辑简单易懂,实施方便。
技术特征:
1.一种处理生僻字一字多码的方法,包括:
2.根据权利要求1所述的方法,其中,在根据编码映射表将所述m个字符的用户自定义区编码转换为非用户自定义区编码之前,还包括:
3.根据权利要求1所述的方法,其中,所述基于所述第二汉字字符串进行生僻字处理包括:
4.根据权利要求3所述的方法,其中,所述第一汉字字符串和所述第三汉字字符串来自不同的平台系统,所述不同的平台系统包括来自不同机构或不同版本的软硬件环境。
5.根据权利要求1所述的方法,其中,所述基于所述第二汉字字符串进行生僻字处理包括:
6.根据权利要求5所述的方法,其中,所述进行数据库查询和/或联网核查包括:
7.根据权利要求1所述的方法,其中,所述n个字符中除m个字符以外的其他字符皆具有所述非用户自定义区编码,所述基于所述第二汉字字符串进行生僻字处理包括:
8.根据权利要求1所述的方法,其中,所述从所述n个字符中确定具有用户自定义区编码的m个字符包括:
9.根据权利要求8所述的方法,其中,所述方法还包括:
10.一种处理生僻字一字多码的装置,包括:
11.一种电子设备,包括:
12.一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行根据权利要求1~9中任一项所述的方法。
13.一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现根据权利要求1~9中任一项所述的方法。
技术总结
本公开提供了一种处理生僻字一字多码的方法,涉及金融科技领域。该方法包括:将第一汉字字符串分割为N个字符;从所述N个字符中确定具有用户自定义区编码的M个字符,M小于或等于N;根据编码映射表将所述M个字符的用户自定义区编码转换为非用户自定义区编码,得到第二汉字字符串,其中,所述编码映射表中包括所述M个字符中每个字符的用户自定义区编码与非用户自定义区编码的映射关系;基于所述第二汉字字符串进行生僻字处理。本公开还提供了一种处理生僻字一字多码的装置、设备、存储介质和程序产品。
技术研发人员:杨帅,袁蓉,陈静国,廖过房
受保护的技术使用者:中国工商银行股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!