一种基于QPSO算法和LSTM模型的数字经济数据处理方法
本发明涉及数据处理领域,特别涉及一种基于qpso算法和lstm模型的数字经济数据处理方法。
背景技术:
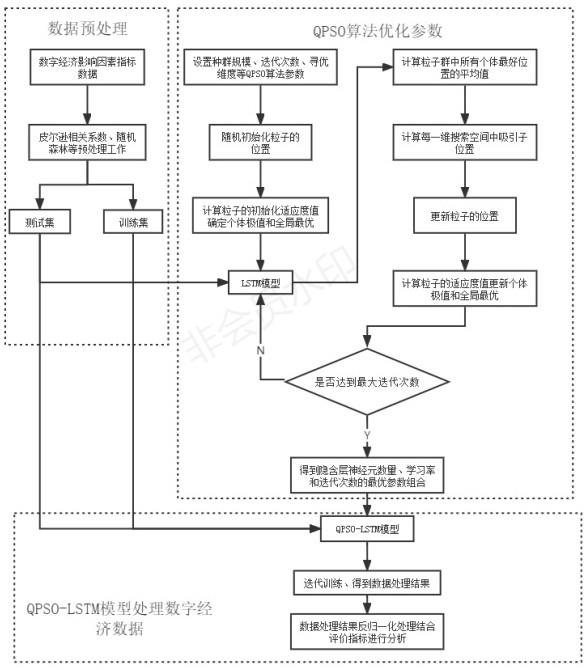
1、随着经济全球化潮流的演变和国际经济结构调整进程的加快,数据处理影响指标越来越多,使得数据处理的难度日趋加大。因此,进行科学数据处理的重要性逐渐凸显出来,准确的数据处理不仅能够对未来经济走势做出量化判断,还能直接服务经济社会的发展,有效防范经济风险。当今世界,由信息革命作为引领,以数据资源作为关键要素的数字经济时代已经来临,数字经济在国民经济中的占比已经达到一定程度,值得广大科研工作者进行持续关注和深入研究。但目前大部分工作聚焦于数字经济的定义、发展水平、监管制度及其对社会的作用等方面,对于数字经济数据处理领域,却少有学者涉及。
技术实现思路
1、本发明的目的在于提供一种基于qpso算法和lstm模型的数字经济数据处理方法,引入lstm模型对数据进行处理,从深层次挖掘和刻画数字经济数据中存在复杂关系,在此基础上,为改善模型初始权重、阈值以及网络节点数量获取困难等问题,引入qpso算法,对参数进行寻优,将寻得的最优参数赋给lstm模型,避免模型参数选择的盲目性,从而更好的捕捉数字经济数据的变化特征,提高数据处理的准确性。
2、为实现上述目的,本发明的技术方案是:一种基于qpso算法和lstm模型的数字经济数据处理方法,具体包括以下步骤:
3、步骤s1、对影响经济数据变化因素的指标数据进行预处理操作,包括标准化、计算皮尔逊相关参数和随机森林、训练集和测试集划分;
4、步骤s2、初始化lstm模型结构,包括lstm模型结构中输入层和输出层神经元数量、模型优化器、激活函数参数;
5、步骤s3、确定粒子的适应度函数,将带有lstm模型参数的粒子群个体的适应度函数定为均方误差mse,qpso算法的迭代目标是找到一组最优参数组合,使得适应度值最小;
6、步骤s4、根据粒子的适应度函数计算粒子的初始适应度值,确定个体极值pi,t,并将适应度值最小的个体极值确定为全局最优gt;
7、步骤s5、计算整个粒子群中所有个体最好位置的平均值ct;
8、步骤s6、计算得到每一维搜索空间中的每个粒子的个体极值
9、步骤s7、更新粒子的位置
10、步骤s8、根据粒子的适应度函数计算粒子的适应度值,并更新个体极值pi,t和全局最优gt;
11、步骤s9、若达到最大迭代次数,将得到的最优参数组合赋予lstm模型,并对qpso-lstm模型进行训练;否则,返回步骤s5;
12、步骤s10、通过mape、mae和r2检验组合数据处理模型的性能,判断组合模型是否适用于对数字经济数据的处理。
13、在本发明一实施例中,lstm模型引入记忆单元用于存储历史信息和门控单元用于添加或移除记忆单元中的信息,具体如下:
14、①遗忘门:决定从记忆单元中舍弃多少信息,计算公式如下:
15、ft=σ(wf·[ht-1,xt]+bf)
16、其中ft表示遗忘门控,σ表示激活函数,wf表示权重,bf表示阈值,ht-1表示t-1时刻隐藏层输出,xt表示当前时刻输入;
17、②输入门:决定哪些状态信息添加到记忆单元中,计算公式如下:
18、i=σ(wi·[ht-1,xt]+bi)
19、其中i表示输入门控,wi表示权重,bi表示阈值;
20、③更新门:更新记忆单元状态,计算公式如下:
21、
22、其中ct表示记忆单元状态,ct-1表示t-1时刻记忆单元状态,it表示输入门控,表示t时刻的输入门控;
23、④输出门:决定记忆单元中哪些状态信息作为输出,计算公式如下:
24、ot=σ(wo·[ht-1,xt]+bo)
25、其中ot表示输出门控,bo表示阈值,wo表示权重;
26、最终,lstm模型输出的状态将保留过去所有的输出信息,计算公式如下:
27、
28、其中表示输出,by表示阈值,wy表示权重,g表示激活函数,ht表示t时刻的输出门控。
29、在本发明一实施例中,通过qpso算法对lstm模型中的隐含层神经元数量、学习率和训练次数参数进行优化,构建qpso-lstm模型进行数据处理;
30、qpso算法的具体公式如下:
31、
32、其中表示介于(0,1)之间的随机数,表示个体极值,表示全局最优;
33、qpso算法通过在点建立δ势阱,产生束缚态,处于量子束缚态的粒子能够以预定的概率出现在可行区域中任何点,既保证粒子可以在整个可行区域进行大范围搜索最优解又不会发散到无穷远,建立δ势阱后,对应的粒子束缚态波函数如下:
34、
35、其中是δ势阱的特征长度,表示更新粒子的位置,上式对应的概率分布函数为:
36、
37、根据蒙特卡罗法,得到的迭代更新公式如下:
38、
39、其中表示介于(0,1)之间的随机数;
40、至此,问题变成如何控制趋于0,从而使粒子经过迭代更新后,收敛到吸引子为解决该问题,引入平均最好位置ct:
41、
42、其中n表示粒子个数;
43、则定义为:
44、
45、其中α表示扩张-收缩因子,表示第i个粒子的平均最好位置,表示t时刻更新粒子的位置;
46、于是,的迭代更新公式变为:
47、
48、qpso算法中的粒子能够以预定的概率分布函数出现在搜索空间的任何位置,且通过引入平均最好位置,提高了粒子之间的协作能力,增强了全局搜索的能力,能够避免整个粒子群陷入局部最优的困境。
49、相较于现有技术,本发明具有以下有益效果:
50、1、采用qpso算法对lstm模型中的部分参数进行优化,并根据优化后的最优参数组合构建的qpso-lstm模型,数据处理的精度和性能均有一定提升,体现出在数字经济数据处理的工作中,采用qpso算法对lstm模型进行参数寻优的可操作性。
51、2.、在qpso-lstm模型中,针对数据处理问题,得益于元启发式算法的参数寻优功能,避免了人为选择参数的主观影响,qpso-lstm模型相较于lstm模型,各项指标均能得到显著的提升,说明了将qpso-lstm模型用于进一步提高数字经济数据处理精度的有效性。
技术特征:
1.一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,通过建立影响数据变化的因素指标体系,结合qpso算法和lstm模型,构建组合模型。
2.根据权利要求1所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,针对影响数据变化的因素指标体系混杂的问题,结合皮尔逊相关系数和随机森林的特征重要性评估思想,对选取相应的数据变化影响因素进行分析,建立数据处理影响因素指标体系。
3.根据权利要求2所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,通过皮尔逊相关系数得到两个变量间相关性的强弱关系,其基本原理是以依赖度量作为评价函数来衡量特征子集性能,按积差方法来计算,基于两组数据与其各自平均值的离差,两个变量之间的相关程度则借助两个离差相乘的结果来反映,计算结果范围是[-1,1],其绝对值值越大,两个变量之间相关程度越强,具体公式如下:
4.根据权利要求2所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,
5.根据权利要求1所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,
6.根据权利要求5所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,
7.根据权利要求6所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,该方法具体包括以下步骤:
8.根据权利要求1所述的一种基于qpso算法和lstm模型的数字经济数据处理方法,其特征在于,
技术总结
本发明涉及一种基于QPSO算法和LSTM模型的数字经济数据处理方法。针对数字经济影响因素指标体系混杂的问题,结合皮尔逊相关系数和随机森林的特征重要性评估思想,对选取的数据处理影响因素进行分析,建立数据处理指标体系,克服了影响因素选取存在主观性,易带来特征冗余导致神经网络训练缓慢的问题;引入数据处理指标体系,结合QPSO算法,构建组合模型,其中,QPSO算法克服人为调整参数具有盲目性和不确定性的难题,使参数寻优结果和收敛速度和数据处理精度得到进一步地提升。
技术研发人员:黄捷
受保护的技术使用者:福州大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!