一种基于八度卷积和编解码的手写数学表达式识别方法
本发明涉及模式识别与人工智能,具体为一种基于八度卷积和编解码的手写数学表达式识别方法。
背景技术:
1、手写数学表达式识别任务的目标是对于输入的只包含手写数学表达式的图片,通过算法分析,将图片转成对应的latex数学表达式。
2、手写数学表达式存在局部歧义性和结构复杂性等特点,往往无法被拆解为独立的字符,导致这类方法的识别准确率很低。
3、现有的以手写数学表达式识别方法分为表达式符号的识别和表达式结构分析两个阶段。这类方法虽然可以在一定程度上匹配出数学表达式内部包含的复杂特征,但对符号识别的错误较敏感,当符号出现误识别时,会对结构分析产生较大影响,并且,这类算法对含嵌套上下标的表达式识别精度较低,不能满足实际生产生活需要。
技术实现思路
1、本发明的目的在于提供一种基于八度卷积和编解码的手写数学表达式识别方法,以解决上述背景技术中提出现有的以手写数学表达式识别方法对符号识别的错误较敏感以及对含嵌套上下标的表达式识别精度较低,不能满足实际生产生活需要的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于八度卷积和编解码的手写数学表达式识别方法,包括以下步骤;
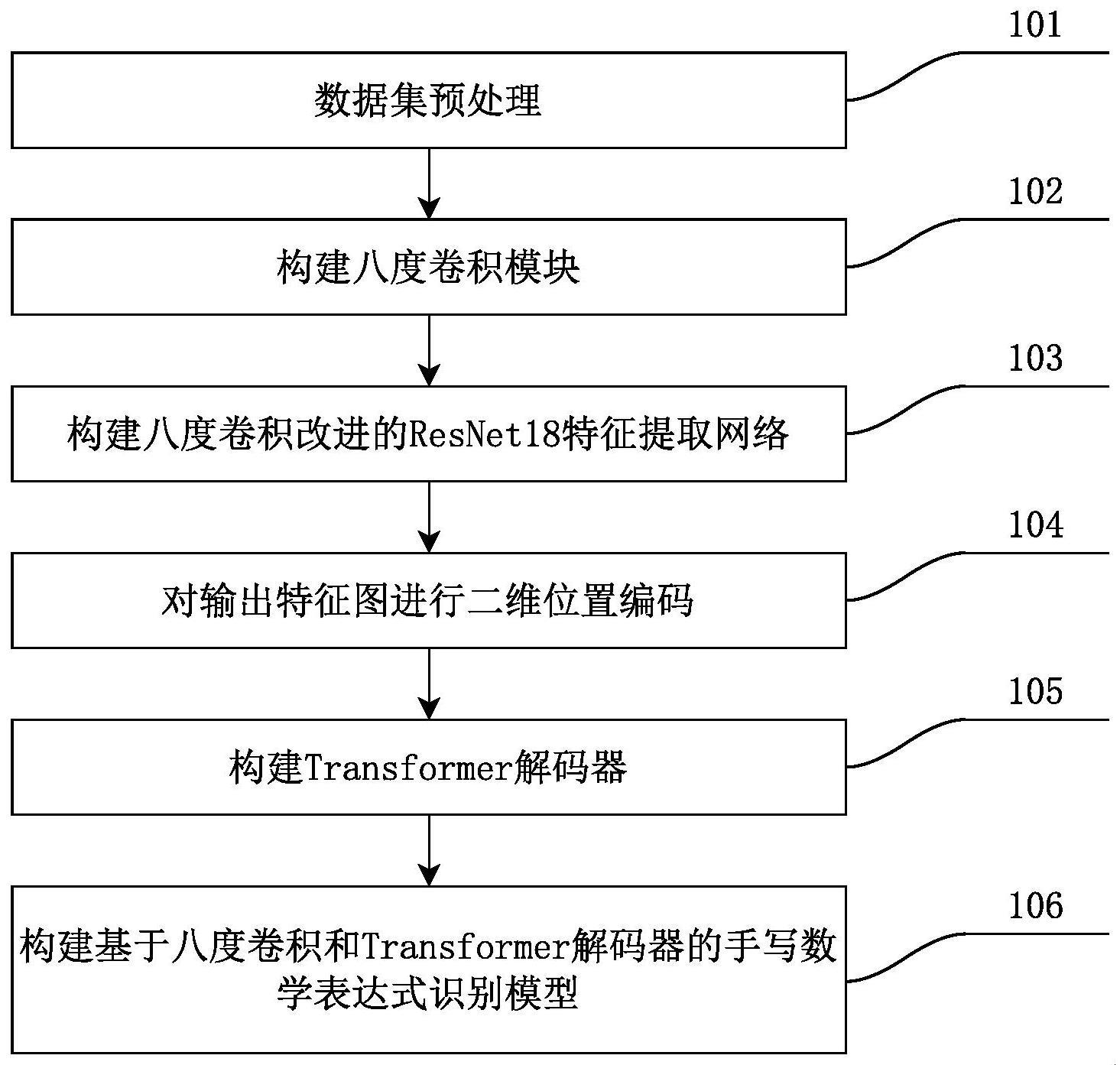
3、步骤1:数据集预处理。
4、所述数据集预处理包括对手写数学表达式图像和标签进行预处理;构建词元字典和把数据集分成训练集、验证集和测试集。
5、所述对手写数学表达式图像和标签进行预处理方法包括图像灰度化、公式部分裁剪、边缘填充。
6、所述构建词元字典包括按latex语法对数据标签进行解析,将公式符号与公式内容用空格隔开,公式内容用空格拆分成独立的字母和数字,形成词元序列。接着,对每个词元统计出现的次数,取出现次数最多的k个词元组成字典,并给每个词元赋予唯一的数字索引。
7、步骤2:构建八度卷积模块。
8、所述八度卷积是对传统卷积方法的一种改进。与原始卷积输出是单一特征不同,八度卷积根据图像的特性,将特征空间映射为两个不同的频率,即输入x=(xh,xl),输出y=(yh,yl),其中和分别为输入的高低频分量,而和分别为输出的高低频分量。通过调节αin和αout,可以控制高低频分量的输入和输出信道比。
9、步骤3:构建八度卷积改进的resnet18特征提取网络。
10、所述八度卷积改进的resnet18特征提取网络由三部分组成,包括图像预处理块、卷积块、resnet基本构件块。
11、所述图像预处理块输入向量尺寸为224×224,输入通道数为3。
12、所述卷积块首先进行普通卷积运算,再进行最大池化运算,得到64×56×56的输出。
13、所述resnet基本构件块,由三个子层串联形成。每个子层由两个相同的resnet基本构件组成。每个resnet基本构件使用的卷积方式均为八度卷积,每个基本构件均包括一个残差支路和一个直连支路。残差支路上依次是3×3八度卷积、批归一化、relu激活函数、3×3八度卷积、批归一化。每个基本构件通过直连支路直接将输入的特征图与残差支路的输出相加,经过relu激活函数激活后得到该基本构件的输出特征图。
14、relu激活函数的数学表达式为:relu(x)=max(0,x)
15、步骤4:对输出特征图进行二维位置编码。
16、所述二维位置编码方法是对传统一维正余弦位置编码方法在二维平面内的推广,即二维正余弦编码方法。
17、二维正余弦编码方法的数学公式为:
18、
19、
20、
21、
22、其中,x和y分别表示特征图沿水平和垂直方向的索引,2i和2i+1分别表示输出特征图通道维度的偶数索引和偶数索引,d为输出通道维度。
23、将步骤3的输出特征图与二维位置编码的结果pe相加,即可得到带位置编码信息的特征图。
24、步骤5:构建transformer解码器。
25、所述transformer解码器由缩放点乘注意力、多头注意力和前馈网络组成。具体地计算过程如下:
26、
27、hi=attention(qwiq,kwik,vwiv)
28、multihead(q,k,v)=[h1;…,hh]wo
29、ffn(x)=max(0,xw1+b1)w2+b2
30、其中,attention(q,k,v)表示缩放点乘注意力的计算,hi和multihead(q,k,v)表示多头自注意力机制的计算,ffn(x)为前馈神经网络。
31、由于注意力机制无法对位置信息进行捕捉,所以标签在输入解码器前需要提前进行词嵌入,将输入的数据编码为词向量。
32、所述词嵌入块首先根据步骤1构建的字典,将输入的latex标签中每一个词元转换为数字索引,得到原始词嵌入向量。接着,利用一维余弦位置编码方法对原始词嵌入向量进行编码,得到带位置信息的词嵌入向量。
33、所述一维余弦位置编码的数学表达式为:
34、
35、
36、其中,pos表示单词在句子中的位置,d表示词嵌入块的输出维度,2i表示偶数的维度,2i+1表示奇数的维度,2i≤d,2i+1≤d。
37、softmax的数学公式为:
38、
39、其中,zi表示解码器的每个输出分量。
40、使用交叉熵损失函数对输出概率进行评估,交叉熵损失函数的数学公式为:
41、
42、其中,yij表示标签,pij表示模型输出概率。
43、步骤6:构建基于八度卷积和transformer解码器的手写数学表达式识别模型。
44、基于八度卷积和transformer解码器的手写数学表达式识别模型采用的是编解码器结构。编码器使用了八度卷积优化的resnet18特征提取网络来提取图像特征并编码图像,解码器仍然沿用了transformer的解码器结构。
45、所述编码器由八度卷积优化的resnet18特征提取网络、线性映射层、二维位置编码和压平层四个部分组成。
46、所述编码器利用八度卷积优化的resnet18特征提取网络获取到的图像特征图,经过由1x1卷积构成的线性映射层将特征图映射成transformer解码器输入要求的维数。接着,通过二维余弦编码模块对特征图进行位置编码,之后再经过压平层形成一个一维的向量输入给所述解码器。
47、所述解码器的输出结果经过softmax函数激活得到每个位置词元的概率,利用贪婪搜索的方法,即找概率最大的词元作为当前位置的预测输出,即可得到完整的输出序列。输出的序列利用字典进行反索引化,即可得到识别出的数学表达式。
技术特征:
1.一种基于八度卷积和编解码的手写数学表达式识别方法,其特征在于:所述方法包括以下步骤:
2.根据权利要求1所述的一种基于八度卷积和编解码的手写数学表达式识别方法,其特征在于:所述数据预处理包括对手写数学表达式图像和标签进行预处理;构建词元字典和把数据集分成训练集、验证集和测试集;
3.根据权利要求1所述的一种基于八度卷积和编解码的手写数学表达式识别方法,其特征在于:八度卷积改进的resnet18特征提取网络由三部分组成,包括图像预处理块、卷积块、resnet基本构件块;
4.根据权利要求1所述的一种基于八度卷积和编解码的手写数学表达式识别方法,其特征在于:所述二维位置编码方法是对传统一维正余弦位置编码方法在二维平面内的推广,其计算公式为:
5.根据权利要求1所述的一种基于八度卷积和编解码的手写数学表达式识别方法,其特征在于:所述transformer解码器由缩放点乘注意力、多头注意力和前馈网络组成;具体地计算过程如下:
6.根据权利要求1所述的一种基于八度卷积和编解码的手写数学表达式识别方法,其特征在于:所述构建的基于八度卷积和transformer解码器的手写数学表达式识别模型采用的是编解码器结构;编码器使用了八度卷积优化的resnet18特征提取网络来提取图像特征并编码图像,解码器仍然沿用了transformer的解码器结构;
技术总结
本发明公开了一种基于八度卷积和编解码的手写数学表达式识别方法,包括数据预处理、构建八度卷积模块、构建八度卷积改进的ResNet18特征提取网络、对输出特征图进行二维位置编码、构建Transformer解码器、构建基于八度卷积和Transformer解码器的手写数学表达式识别模型六个步骤。本方法采用编解码器结构进行组织,编码器使用了八度卷积优化的ResNet18特征提取网络来提取图像特征并编码图像,解码器仍然沿用了Transformer的解码器结构。所述编码器由八度卷积优化的ResNet18特征提取网络、线性映射层、二维位置编码和压平层四个部分组成。相比于现有方法,本发明具有良好的识别精度和泛化能力,可满足生产环境的实际需要。
技术研发人员:卢利栋,游兴隆
受保护的技术使用者:河海大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!