面向考试领域的手写中文行识别方法及系统与流程
本发明涉及图像处理,特别是涉及面向考试领域的手写中文行识别方法及系统。
背景技术:
1、本部分的陈述仅仅是提到了与本发明相关的背景技术,并不必然构成现有技术。
2、文本识别是机器学习和计算机视觉领域的一个热门方向。在教育考试领域,非选择题类题目仍然主要以手写文字的方式作答。在试卷评分的过程中,目前仍然处于评卷教师从考生答题卡的扫描图像中辨认考试书写内容进而给出分数的现状中。对此,将大量的图像数据转写为文本化数据是十分必要的。这样的策略既能对试卷进行智能评分,提高评卷质量和效率;又能基于大数据分析的角度,从多个维度分析考试试题质量、考察考生答题结果,并将其反馈给考试管理和命题机构,对改进学生学习方法、提高教师教学质量和命题水平提供辅助方案。
3、文本识别方法可以按照是否对字符分割分为两类:一类是基于分割的方法,即将文本行图像中每个字符的位置进行定位,进而将文本行以字符为单位进行分割,然后对分割出的单个字符使用字符分类器进行识别,最终将单个字符的识别结果整合为文本行的识别结果。这种方法存在两个明显的局限性:一是文本行的识别结果依赖于对字符进行定位的准确性;二是该方法将文本行中的字符视为单独的个体,无法对文本行本身含有的上下文信息进行利用。另一类是基于无分割的方法,也被称为序列到序列(sequencetosequence)的方法,即将文本行图像视为一个序列,方法的输出是字符序列,模型旨在学习文本图像到输出序列的一种映射关系,通过特征隐式对齐来避免对字符的分割操作。隐式特征对齐效果通常在模型的解码器部分实现,根据解码器的实现方式,可以将无分割方法分为两类:一类是基于ctc(connectionisttemporal classification,连接时序分类)的方法,即根据每个时间步的概率分布,组合为一个二维概率分布矩阵,通过动态规划寻找最大概率的预测路径;另一类是基于attention的方法,在解码时利用注意力机制使模型关注与当前时间步相关的部分,来实现特征对齐。
4、目前科研领域对文本识别方法的研究主要针对于自然场景下的英文文本识别,面向真实场景下试卷数据的中文文本行识别与目前科研研究方向有较大差别。具体来说,目前考试领域的中文文本行识别面临以下几个问题:不同于英文的少量字母,中文有超过3000个常用字符,整个识别字典的容量超过6000个字符;不同于场景文本的印刷体,试卷中均为手写体,由于其本身的流动性与书写者书写方式的多样性,识别难度陡然增加;不同于公开数据集上的较短文本,考试领域的文本行来自于考生书写的简答题,单个图像样本的文本长度往往超过30,这大大增加了文本识别的难度。
技术实现思路
1、为了解决现有技术的不足,本发明提供了面向考试领域的手写中文行识别方法及系统;在该方法中主要侧重以下几方面:1)在特征矩阵序列化的过程中加入列注意力机制以对包含文本信息的像素赋予更高权重;2)提出了新颖的损失函数,使像素提取模块学习到有区分度的知识;3)结合ctc解码方式和attention解码方式的优点,发挥不同解码方式的优势;4)对文本行包含的上下文信息进行建模,通过上下文信息辅助模型的训练与预测;5)使解码器模块化,实现在预测时通过移除特征序列化与循环神经网络的方式实现对多行段落的识别,并且提高识别速度。
2、第一方面,本发明提供了面向考试领域的手写中文行识别方法;
3、面向考试领域的手写中文行识别方法,包括:
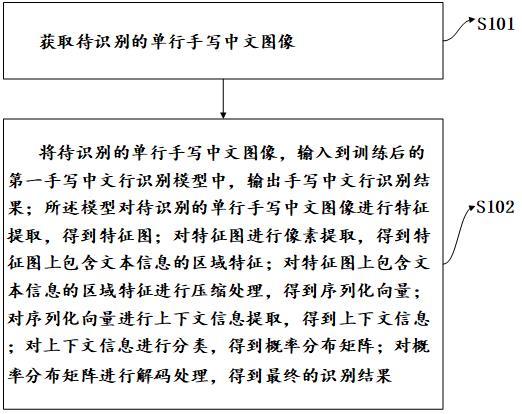
4、获取待识别的单行手写中文图像;
5、将待识别的单行手写中文图像,输入到训练后的第一手写中文行识别模型中,输出手写中文行识别结果;
6、其中,所述训练后的第一手写中文行识别模型,包括:对待识别的单行手写中文图像进行特征提取,得到特征图;对特征图进行像素提取,得到特征图上包含文本信息的区域特征;对特征图上包含文本信息的区域特征进行压缩处理,得到序列化向量;对序列化向量进行上下文信息提取,得到上下文信息;对上下文信息进行分类,得到概率分布矩阵;对概率分布矩阵进行解码处理,得到最终的识别结果。
7、第二方面,本发明提供了面向考试领域的手写中文行识别系统;
8、面向考试领域的手写中文行识别系统,包括:
9、获取模块,其被配置为:获取待识别的单行手写中文图像;
10、识别模块,其被配置为:将待识别的单行手写中文图像,输入到训练后的第一手写中文行识别模型中,输出手写中文行识别结果;
11、其中,所述训练后的第一手写中文行识别模型,包括:对待识别的单行手写中文图像进行特征提取,得到特征图;对特征图进行像素提取,得到特征图上包含文本信息的区域特征;对特征图上包含文本信息的区域特征进行压缩处理,得到序列化向量;对序列化向量进行上下文信息提取,得到上下文信息;对上下文信息进行分类,得到概率分布矩阵;对概率分布矩阵进行解码处理,得到最终的单行手写中文图像的识别结果。
12、与现有技术相比,本发明的有益效果是:
13、本发明在空间特征提取之后增加了像素提取模块,通过在特征图的每列上应用注意力机制,使模型自适应地学习到最具有文本信息的像素位置。
14、本发明针对像素提取模块提出了新颖且有效的损失函数,使模型可以真正关注到含有文本信息的像素,使像素提取模块学习到更具有区分度的知识,并通过最终的损失函数联合训练。
15、本发明结合了ctc解码和attention解码方式的优点,从两个维度上实现了特征的隐式对齐,最终实现了优秀的识别效果。
16、本发明通过对文本行的上下文信息进行建模,让上下文信息可以辅助训练与预测。
17、本发明通过模块化思想,实现了两种方法路线,并且实现在预测时移除像素提取模块与上下文模块从而达到对多行文本行组成的段落图像进行识别的效果。
技术特征:
1.面向考试领域的手写中文行识别方法,其特征是,包括:
2.如权利要求1所述的面向考试领域的手写中文行识别方法,其特征是,所述训练后的第一手写中文行识别模型,其网络结构包括:
3.如权利要求1所述的面向考试领域的手写中文行识别方法,其特征是,所述训练后的第一手写中文行识别模型,其训练过程包括:
4.如权利要求3所述的面向考试领域的手写中文行识别方法,其特征是,所述构建第一训练集,包括:
5.如权利要求3所述的面向考试领域的手写中文行识别方法,其特征是,所述模型的总损失函数为:
6.如权利要求1所述的面向考试领域的手写中文行识别方法,其特征是,所述方法,还包括:
7.如权利要求6所述的面向考试领域的手写中文行识别方法,其特征是,所述训练后的第二手写中文行识别模型,包括:对待识别的多行手写中文图像进行特征提取,得到特征图;对特征图进行像素提取,得到特征图上包含文本信息的区域特征;对特征图上包含文本信息的区域特征进行压缩处理,得到序列化向量;对序列化向量进行分类,得到分类结果;对分类结果进行解码处理,得到最终的识别结果。
8.如权利要求6所述的面向考试领域的手写中文行识别方法,其特征是,获取待识别的多行手写中文图像;将待识别的多行手写中文图像,输入到修正后的第二手写中文行识别模型中,输出多行手写中文行的识别结果;具体包括:
9.如权利要求8所述的面向考试领域的手写中文行识别方法,其特征是,所述后处理模块,具体工作过程包括:
10.面向考试领域的手写中文行识别系统,其特征是,包括:
技术总结
本发明涉及图像处理技术领域,公开了面向考试领域的手写中文行识别方法及系统;方法包括:获取待识别的单行手写中文图像;将待识别的单行手写中文图像,输入到训练后的第一手写中文行识别模型中,输出手写中文行识别结果;模型用于对待识别的单行手写中文图像进行特征提取得到特征图;对特征图进行像素提取得到特征图上包含文本信息的区域特征;对特征图上包含文本信息的区域特征进行压缩处理得到序列化向量;对序列化向量进行上下文信息提取得到上下文信息;对上下文信息进行分类得到概率分布矩阵;对概率分布矩阵进行解码处理得到最终的识别结果。本发明能够对多行文本行组成的段落图像进行识别,提高了识别的速度。
技术研发人员:许信顺,李昊,马磊,陈义学,李溢欢
受保护的技术使用者:山东山大鸥玛软件股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!