可配置卷积核大小和并行计算数目的脉动阵列结构及方法与流程
本发明涉及人工智能,具体为可配置卷积核大小和并行计算数目的脉动阵列结构及方法。
背景技术:
1、随着科技发展,人工智能在各个领域被广泛应用,卷积神经网络的研究和应用一直是人工智能的一个核心,神经网络可以为广泛的应用提供高精度的推理,随着神经网络的深入化和复杂化,人们对神经网络计算的速度和硬件面积有了更高的需求,在卷积神经网络中,卷积层的计算量占据了80%以上,为了让更高效率的网络部署在低功耗的soc中,卷积层的硬件加速必不可少。
2、在处理器架构中,大量数据存储在处理器外部的存储器中,当计算模块需要运算的时候,就需要将数据从存储器中取出到缓冲buffer或cache中,再送到计算模块进行运算,在通常地卷积神经网络卷积层计算中,卷积层运算时间相比数据搬运时间要短得多,而通常卷积神经网络需要用到大量的数据,数据存取的速度远远低于数据处理的速度。
3、传统的卷积计算单元有着数据复用低,消耗硬件单元多,卷积计算效率低的缺陷,传统的脉动阵列针对特定卷积核大小和并行数进行优化,一旦更换网络结构则需重新设计阵列结构。
技术实现思路
1、本发明的目的在于提供可配置卷积核大小和并行计算数目的脉动阵列结构及方法,以解决上述背景技术中提出的问题。
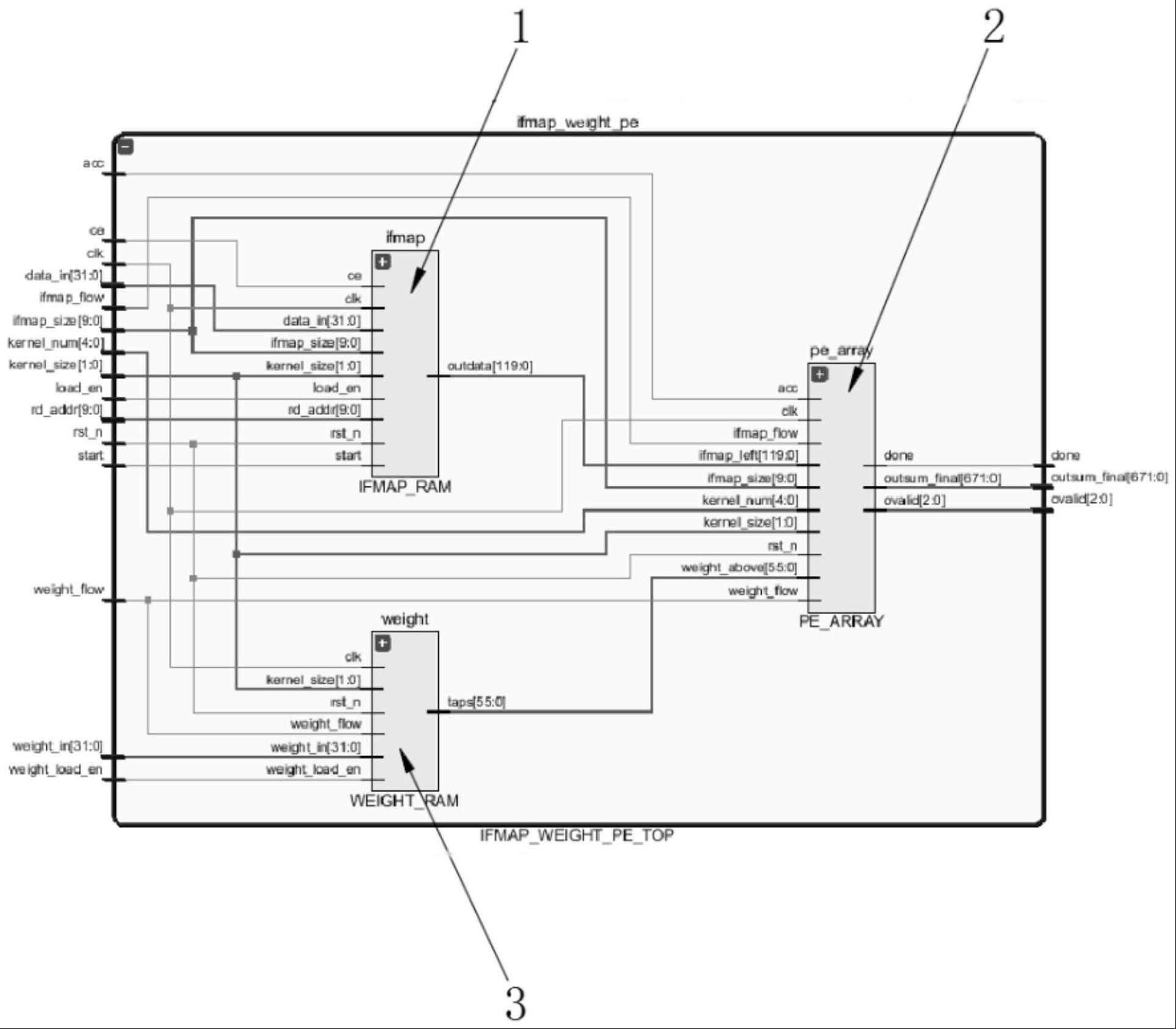
2、为实现上述目的,本发明提供如下技术方案:可配置卷积核大小和并行计算数目的脉动阵列结构,包括ifmap_ram单元、pe_array单元和weight_ram单元,所述ifmap_ram单元通过outdata接口与pe_array单元建立数据连接,且pe_array单元通过taps与weight_ram单元建立数据连接,pe_array单元通过done接口、outsum_final以及ovalid接口与外界建立数据连接。
3、优选的,所述pe_array单元包括乘法器和d触发器,且乘法器为8位乘法器。
4、优选的,所述pe_array单元有7×15个单元,且支持的卷积核为21个2×2卷积核、10个3×3卷积核,3个5×5卷积核和2个7×7卷积核其中一种。
5、优选的,所述pe_array单元中卷积核大小为7,则并行度最大为2,卷积核大小为5,则并行度最大为3,卷积核大小为3,则并行度最大为10,若卷积核大小为2,则并行度最大为21。
6、可配置卷积核大小和并行计算数目的脉动阵列的方法,包括步骤一,权重数据的固定;步骤二,输入特征图数据的广播和排列;步骤三,卷积计算;步骤四,输出数据的有效性判定;步骤五,数据储存;
7、其中上述步骤一中,取出存在ram内的卷积核数据,根据卷积核大小信号,并行数量信号送到滑动窗口,滑动窗口连接脉动阵列最上方一行pe单元,每个周期滑动窗口和行pe单元往下传输一次数据,直到卷积核滑动使能信号置零,此时不同权重数据固定在脉动阵列单元;
8、其中上述步骤二中,当步骤一中的权重数据被固定完毕,取出存在乒乓buffer中的输入特征图数据,根据输入特征图大小信号,卷积核大小信号,并行数量信号,将信号传输到滑动窗口,并对滑动窗口输出数据进行排列,若并行数大于1,则需要对数据进行广播,连接到脉动阵列最左侧第一列,接着每个周期滑动窗口和行pe单元往右侧传输一次数据,直到最右侧需要进行计算的pe单元收到输入特征图数据,开始进行计算;
9、其中上述步骤三中,当步骤二中输入特征图数据脉动到最右侧需要计算的pe单元,此时拉高运算使能信号,pe单元开始对固定的权重数据和输入特征图数据进行卷积计算,随着左侧输入特征图数据向右流动,得到乘法结果,此时根据卷积核大小信号,对同一卷积核计算出来的乘法结果进行两两累加,若卷积核大小为2×2,则需要两个周期得到累加结果,若卷积核大小为3×3,则需要四个周期得到累加结果,若卷积核大小为5×5,则需要六个周期得到累加结果,若卷积核大小为7×7,则也需要六个周期得到累加结果;
10、其中上述步骤四中,当步骤三中的数据累加完成,则通过输出端口输出,此时输出端口数据并不全有效,需要根据输出数据有效标志位和并行数量来识别有效输出信号,根据每一列数据累加完成时间来标志;
11、其中上述步骤五中,当步骤一、步骤二、步骤三以及步骤四完成后,则输出缓存根据脉动阵列输出数据和out_enable,并行数量来存储数据。
12、优选的,所述步骤二中,若卷积核大小为2,卷积并行数为21,则脉动阵列按照图3右下角图所示排列,在输入特征图流进脉动阵列的第2个周期时开始1,2行所有彩色pe的卷积计算操作,在第4个周期开始3,4行所有彩色pe的卷积计算操作,在第6个周期开始5,6彩色pe的卷积计算操作,在倒数第5个周期时完成1,2行所有彩色pe的卷积计算操作,在倒数第3个周期完成3,4行所有彩色pe的卷积计算操作,在倒数第1个周期完成5,6行所有彩色pe的卷积计算操作。
13、优选的,所述步骤四中,输出信号由ovalid[2:0]、kernel_size[1:0]和kernel_num[4:0]共同标志是否有效。
14、与现有技术相比,本发明的有益效果是:本发明采用相同的可配置卷积核大小和并行数量的脉动阵列结构、采用相同的脉动阵列乘加法流水线结构、采用相同的脉动阵列窗口滑动及广播结构以及采用相同的并行输出有效信号及结构,无需将数据从存储器中取出到缓冲buffer或cache中,在进行计算,有利于实现了卷积层的硬件加速,可配置卷积核大小和并行计算数目的脉动阵列结构,支持不同大小,不同并行数的卷积计算,进一步提高了数据复用的能力,降低了硬件计算单元的消耗,提高了卷积计算的效率。
技术特征:
1.可配置卷积核大小和并行计算数目的脉动阵列结构,包括ifmap_ram单元(1)、pe_array单元(2)和weight_ram单元(3),其特征在于:所述ifmap_ram单元(1)通过outdata接口与pe_array单元(2)建立数据连接,且pe_array单元(2)通过taps与weight_ram单元(3)建立数据连接,pe_array单元(2)通过done接口、outsum_final以及ovalid接口与外界建立数据连接。
2.根据权利要求1所述的可配置卷积核大小和并行计算数目的脉动阵列结构,其特征在于:所述pe_array单元(2)包括乘法器和d触发器,且乘法器为8位乘法器。
3.根据权利要求1所述的可配置卷积核大小和并行计算数目的脉动阵列结构,其特征在于:所述pe_array单元(2)有7×15个单元,且支持的卷积核为21个2×2卷积核、10个3×3卷积核,3个5×5卷积核和2个7×7卷积核其中一种。
4.根据权利要求1所述的可配置卷积核大小和并行计算数目的脉动阵列结构,其特征在于:所述pe_array单元(2)中卷积核大小为7,则并行度最大为2,卷积核大小为5,则并行度最大为3,卷积核大小为3,则并行度最大为10,若卷积核大小为2,则并行度最大为21。
5.可配置卷积核大小和并行计算数目的脉动阵列的方法,包括步骤一,权重数据的固定;步骤二,输入特征图数据的广播和排列;步骤三,卷积计算;步骤四,输出数据的有效性判定;步骤五,数据储存;其特征在于:
6.根据权利要求5所述的可配置卷积核大小和并行计算数目的脉动阵列的方法,其特征在于:所述步骤二中,若卷积核大小为2,卷积并行数为21,则脉动阵列按照图3右下角图所示排列,在输入特征图流进脉动阵列的第2个周期时开始1,2行所有彩色pe的卷积计算操作,在第4个周期开始3,4行所有彩色pe的卷积计算操作,在第6个周期开始5,6彩色pe的卷积计算操作,在倒数第5个周期时完成1,2行所有彩色pe的卷积计算操作,在倒数第3个周期完成3,4行所有彩色pe的卷积计算操作,在倒数第1个周期完成5,6行所有彩色pe的卷积计算操作。
7.根据权利要求5所述的可配置卷积核大小和并行计算数目的脉动阵列的方法,其特征在于:所述步骤四中,输出信号由ovalid[2:0]、kernel_size[1:0]和kernel_num[4:0]共同标志是否有效。
技术总结
本发明公开了可配置卷积核大小和并行计算数目的脉动阵列结构及方法,包括步骤一,权重数据的固定;步骤二,输入特征图数据的广播和排列;步骤三,卷积计算;步骤四,输出数据的有效性判定;步骤五,数据储存;本发明采用相同的可配置卷积核大小和并行数量的脉动阵列结构、采用相同的脉动阵列乘加法流水线结构、采用相同的脉动阵列窗口滑动及广播结构以及采用相同的并行输出有效信号及结构,无需将数据从存储器中取出到缓冲buffer或cache中,实现了卷积层的硬件加速,可配置卷积核大小和并行计算数目的脉动阵列结构,支持不同大小,不同并行数的卷积计算,提高了数据复用的能力,降低了硬件计算单元的消耗,提高了卷积计算的效率。
技术研发人员:窦思远,朱博源,杨冬立
受保护的技术使用者:广东松科智能科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!