视觉问答模型的样本生成方法及相关设备与流程
本发明涉及人工智能,具体涉及一种视觉问答模型的样本生成方法、装置、电子设备及存储介质。
背景技术:
1、视觉问答(visual question answering,vqa)是一个需要同时理解文本和视觉的热门领域。需要计算机算法构建的模型有一定的推理能力,相比传统计算机视觉任务有更高的要求。
2、发明人在实现本发明的过程中发现,现有的视觉问答系统主要依赖于人工标注训练样本,成本高,耗时长,且容易产生各种人类偏见等各种问题,导致基于人工标注的数据进行训练的视觉问答系统是很脆弱的,鲁棒性较差。
技术实现思路
1、鉴于以上内容,有必要提出一种视觉问答模型的样本生成方法、装置、电子设备及存储介质,能够解决智能视觉问答中训练数据缺乏的技术问题,并能够提高视觉问答的准确度。
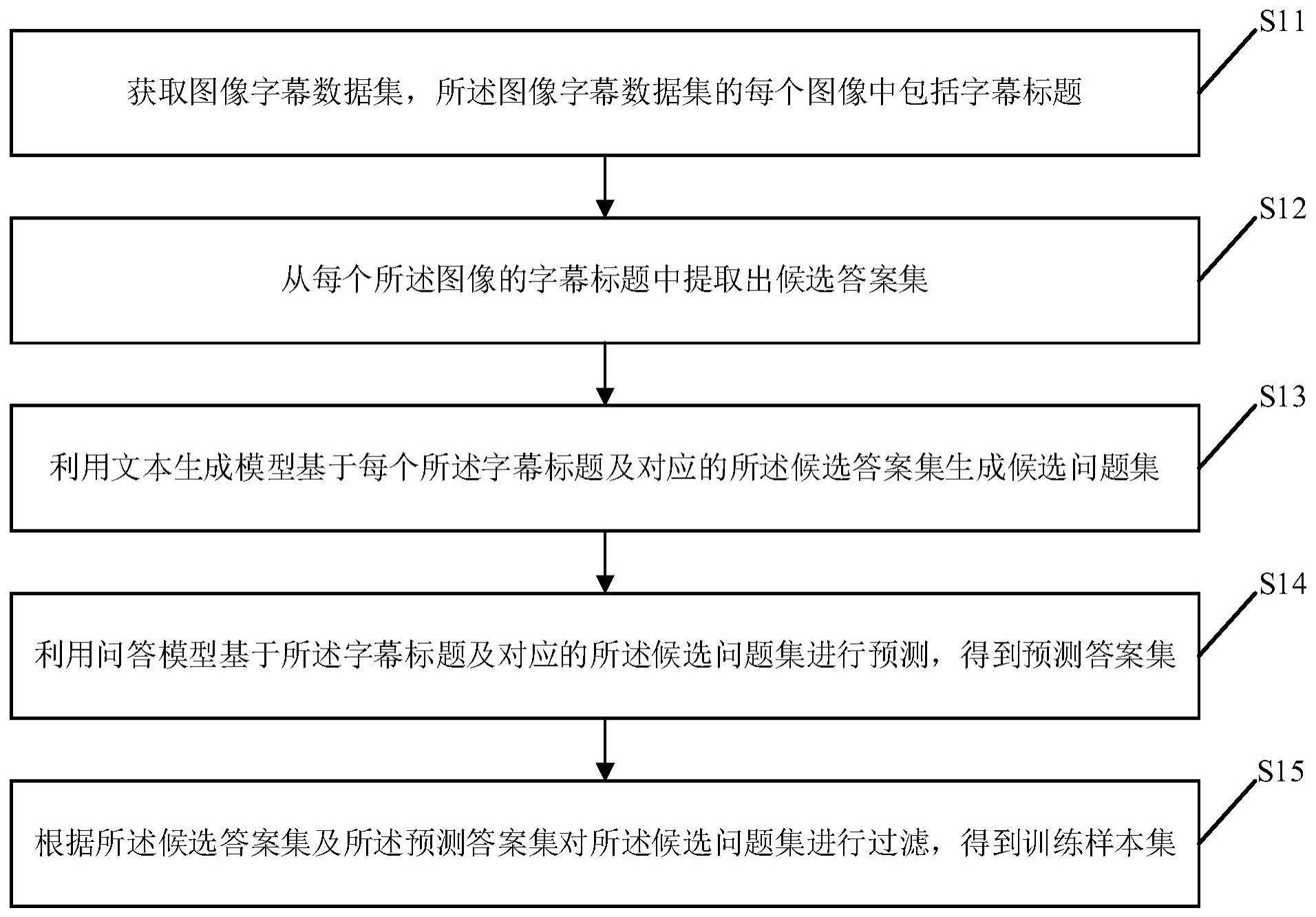
2、本发明的第一方面提供一种视觉问答模型的样本生成方法,所述方法包括:
3、获取图像字幕数据集,所述图像字幕数据集的每个图像中包括字幕标题;
4、从每个所述图像的字幕标题中提取出候选答案集,所述候选答案集中包括默认答案;
5、利用文本生成模型基于每个所述字幕标题及对应的所述候选答案集生成候选问题集;
6、利用问答模型基于所述字幕标题及对应的所述候选问题集进行预测,得到预测答案集;
7、根据所述候选答案集及所述预测答案集对所述候选问题集进行过滤,得到训练样本集。
8、根据本发明的一个可选的实施方式,所述利用文本生成模型基于每个所述字幕标题及对应的所述候选答案集生成候选问题集包括:
9、对所述候选答案集中的多个候选答案进行遍历;
10、将每次遍历的候选答案与所述字幕标题组合成文本数据对;
11、将所述文本数据对输入预先训练的文本生成模型中,通过所述文本生成模型输出多个问题文本及每个所述问题文本对应的置信度;
12、根据所述置信度从所述多个问题文本中选取目标问题文本,作为所述候选答案的候选问题;
13、根据所述多个候选答案对应的候选问题生成候选问题集。
14、根据本发明的一个可选的实施方式,所述根据所述候选答案集及所述预测答案集对所述候选问题集进行过滤,得到训练样本集包括:
15、从所述候选答案集中任意选取一个候选答案,及从所述预测答案集中获取对应所述候选答案的预测答案;
16、根据所述候选答案及对应的所述预测答案计算精确率和召回率;
17、根据所述精确率和召回率计算得到模型评价值;
18、判断所述模型评价值是否大于预设评价阈值;
19、当所述模型评价值大于所述预设评价阈值,保留所述候选答案及对应的所述预测答案;
20、当所述模型评价值小于所述预设评价阈值,剔除所述候选答案及对应的所述预测答案;
21、根据保留的所述候选答案及对应的所述候选问题生成所述训练样本集。
22、根据本发明的一个可选的实施方式,所述文本生成模型是基于webqa数据集及手动生成的问题文本,对语言模型t5-xxl进行微调得到的。
23、根据本发明的一个可选的实施方式,所述从每个所述图像的字幕标题中提取出候选答案集包括:
24、对所述字幕标题进行分词处理,得到多个关键词;
25、对每个所述关键词进行词性识别,得到词性标签;
26、对每个所述关键词进行实体识别,得到实体标签;
27、从所述多个关键词中获取指定词性标签对应的第一关键词集及指定实体标签对应的第二关键词集;
28、根据所述第一关键词集及所述第二关键词集生成候选答案集。
29、根据本发明的一个可选的实施方式,在所述对所述字幕标题进行分词处理,得到多个关键词之后,所述方法还包括:
30、将所述多个关键词与停用词表匹配;
31、当所述多个关键词中的关键词与所述停用词表中的任意一个停用词匹配成功,则去除匹配成功的关键词。
32、根据本发明的一个可选的实施方式,所述方法还包括:
33、基于所述图像字幕数据集及所述训练样本集训练视觉问答模型。
34、本发明的第二方面提供一种视觉问答模型的样本生成装置,所述装置包括:
35、获取模块,用于获取图像字幕数据集,所述图像字幕数据集的每个图像中包括字幕标题;
36、提取模块,用于从每个所述图像的字幕标题中提取出候选答案集,所述候选答案集中包括默认答案;
37、生成模块,用于利用文本生成模型基于每个所述字幕标题及对应的所述候选答案集生成候选问题集;
38、预测模块,用于利用问答模型基于所述字幕标题及对应的所述候选问题集进行预测,得到预测答案集;
39、过滤模块,用于根据所述候选答案集及所述预测答案集对所述候选问题集进行过滤,得到训练样本集。
40、本发明的第三方面提供一种电子设备,所述电子设备包括处理器和存储器,所述处理器用于执行所述存储器中存储的计算机程序时实现所述视觉问答模型的样本生成方法。
41、本发明的第四方面提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现所述视觉问答模型的样本生成方法。
42、本发明实施方式提供的视觉问答模型的样本生成方法、装置、电子设备及存储介质,用于生成样本(训练数据),从而用于下游的视觉问答任务,解决了高性能视觉问答模型训练过程中面临的训练数据不足的瓶颈问题。且由于来源于百万甚至上亿规模的图像字幕数据集,相较于一些人工标注的数据集,不仅省时省力且规模庞大,更重要的是降低人工标注引入的一些人为偏见及误标等导致的模型脆弱性的问题,可以使得基于生成的样本训练出的视觉问答模型更加鲁棒。
43、对于候选答案集的提取也不仅仅是名词短语或命名实体,而且引入了布尔值(是和否),以及量词等多种词性,使得候选答案集可以全面覆盖字幕标题潜在的一些问题点,充分利用图像字幕数据集,使得用于训练视觉问答模型的样本数据集的扩充效果更理想。
44、最后,通过对所述候选答案集及所述预测答案集的验证机制,可以保证生成后的样本数据集的质量更佳。
技术特征:
1.一种视觉问答模型的样本生成方法,其特征在于,所述方法包括:
2.如权利要求1所述的视觉问答模型的样本生成方法,其特征在于,所述利用文本生成模型基于每个所述字幕标题及对应的所述候选答案集生成候选问题集包括:
3.如权利要求1或2所述的视觉问答模型的样本生成方法,其特征在于,所述根据所述候选答案集及所述预测答案集对所述候选问题集进行过滤,得到训练样本集包括:
4.如权利要求3所述的视觉问答模型的样本生成方法,其特征在于,所述文本生成模型是基于webqa数据集及手动生成的问题文本,对语言模型t5-xxl进行微调得到的。
5.如权利要求3所述的视觉问答模型的样本生成方法,其特征在于,所述从每个所述图像的字幕标题中提取出候选答案集包括:
6.如权利要求5所述的视觉问答模型的样本生成方法,其特征在于,在所述对所述字幕标题进行分词处理,得到多个关键词之后,所述方法还包括:
7.如权利要求3所述的视觉问答模型的样本生成方法,其特征在于,所述方法还包括:
8.一种视觉问答模型的样本生成装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,所述电子设备包括处理器和存储器,所述处理器用于执行所述存储器中存储的计算机程序时实现如权利要求1至7中任意一项所述视觉问答模型的样本生成方法。
10.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任意一项所述视觉问答模型的样本生成方法。
技术总结
本发明涉及人工智能技术领域,提供一种视觉问答模型的样本生成方法及相关设备,从图像的字幕标题中提取出候选答案集,候选答案集中还添加有默认答案,充分利用图像字幕数据集,使得用于训练视觉问答模型的样本数据集的扩充效果更理想,利用文本生成模型基于每个所述字幕标题及对应的所述候选答案集生成候选问题集;利用问答模型基于所述字幕标题及对应的所述候选问题集进行预测,得到预测答案集;最后通过所述候选答案集及所述预测答案集对所述候选问题集进行过滤,得到训练样本集,解决了视觉问答模型中训练数据缺乏的问题,保证生成后的样本数据集的质量更佳,使得基于生成的样本训练出的视觉问答模型更加鲁棒。
技术研发人员:姜鹏,谯轶轩
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!