基于电子表格的纸质表格内容分类识别和统计方法及系统与流程
本发明涉及图像处理和图像识别,具体涉及一种基于电子表格的纸质表格内容分类识别和统计方法及系统。
背景技术:
1、纸质版的调查问卷、测评表格等载体在很多场景需要大量使用。传统人工统计工作量大、效率低、误差大,大量的打分表需要统计,动辄几十份、数百份,每张打分表还包括很多的栏目需要进行合格性检验,因此是项繁重的工作。如果能用软件来实现测评结果的自动化统计处理,则能极大的提高工作效率和正确率。
2、现有的表格识别算法均采用深度学习来识别表格结构,并用统一的ocr算法识别表格单元中的内容。通用的ocr算法对打印文字和手写文字识别能正确识别,但对测评表中常出现的手写数字(0~100)和手写符号(√,o,x)识别率很差。
技术实现思路
1、有鉴于此,本发明提出了一种基于电子表格的纸质表格内容分类识别和统计方法及系统,能够对纸质表格中不同类型内容实现分类识别以及统计,速度快,错误率小。
2、为实现上述目的,本发明的技术方案为:
3、一种基于电子表格的纸质表格内容分类识别方法,基于实际调查或测评所用的纸质表格构建电子表格模板,在电子表格模板中分类定义打印文字和手写文字、手写数字和手写符号,基于电子表格模板中的类别,对待识别纸质表格中的表格内容进行划分,针对划分出的不同类别内容,各自采用对应的识别算法进行识别。
4、其中,电子表格模板中的识别内容定义为下面几类:
5、打印文字用“c”表示;手写符号用“s”表示;手写数字用“n”表示;手写文字用“f”表示;
6、如果在这四个符号前加一个行重复标识,表示该设置对本单元格下面连续的所有未设置的单元格都有效;如果在这四个符号前加一个列重复标识,表示该设置对本单元格右面连续的所有未设置的单元格都有效。
7、其中,手写符号包括√,o,x,符号类别分组具体为:如果符号类标识后加有数字1,2,3...,表示这几个连续数字的单元格为一组,一组内必须有且仅有一个√,否则该测评表将被视为不合格。
8、其中,对手写文字和打印文字采用paddle ocr算法进行识别,对手写数字、手写符号分别采用自定义的卷积神经网络模型进行识别。
9、其中,对于待识别纸质表格进行自动转正和矫正,具体如下:
10、在模板内容区域的四个顶点设置四个黑块,其中,左上角黑色填充块比左下角黑色填充块宽,右上角黑色填充块与右下角黑色填充块的宽度相同;
11、识别出各个定位点及其位置关系,将待识别纸质表格利用透视变换技术转换为正平面图即进行自动转正和矫正,正平面图即为矫正后的图片,正平面图长宽比与电子表格文件中定义的长宽比相同,通过电子表格文件中定义的结构切割出正平面图中待识别的单元格,再将各单元格子图按类别交予不同的识别算法进行识别。
12、其中,对纸质表格中的单元格进行精准切割时,首先利用模板结构预计出单元格的位置,然后扩大范围切割出单元格所在的区域,再根据边框线将单元格分为各个连通域,找出最小外接矩形最大的那个连通域,即为单元格的精准区域。
13、其中,找连通域法的算法流程如下:
14、(a)首先,对单元格图像做3个点的腐蚀变换,保证不同单元格之间的区域是不连通的;
15、(b)找出图像中所有面积大于整图十分之一的连通域,计算出这些连通域的最小外界矩形;
16、(c)从符合要求的所有连通域的最小外接矩形中,找出面积最大的那个外接矩形,作为本单元格的内容区;将该区域四周缩小2~3个像素,提取出来,得到去除了边框线的内容区域。
17、本发明还提供了一种基于电子表格的纸质表格内容分类统计方法,基于本发明所述的识别方法得到的结果,批量将识别结果转换为与所述电子表格模板格式一致的电子表格结果文件,最后对电子表格结果文件进行统计。
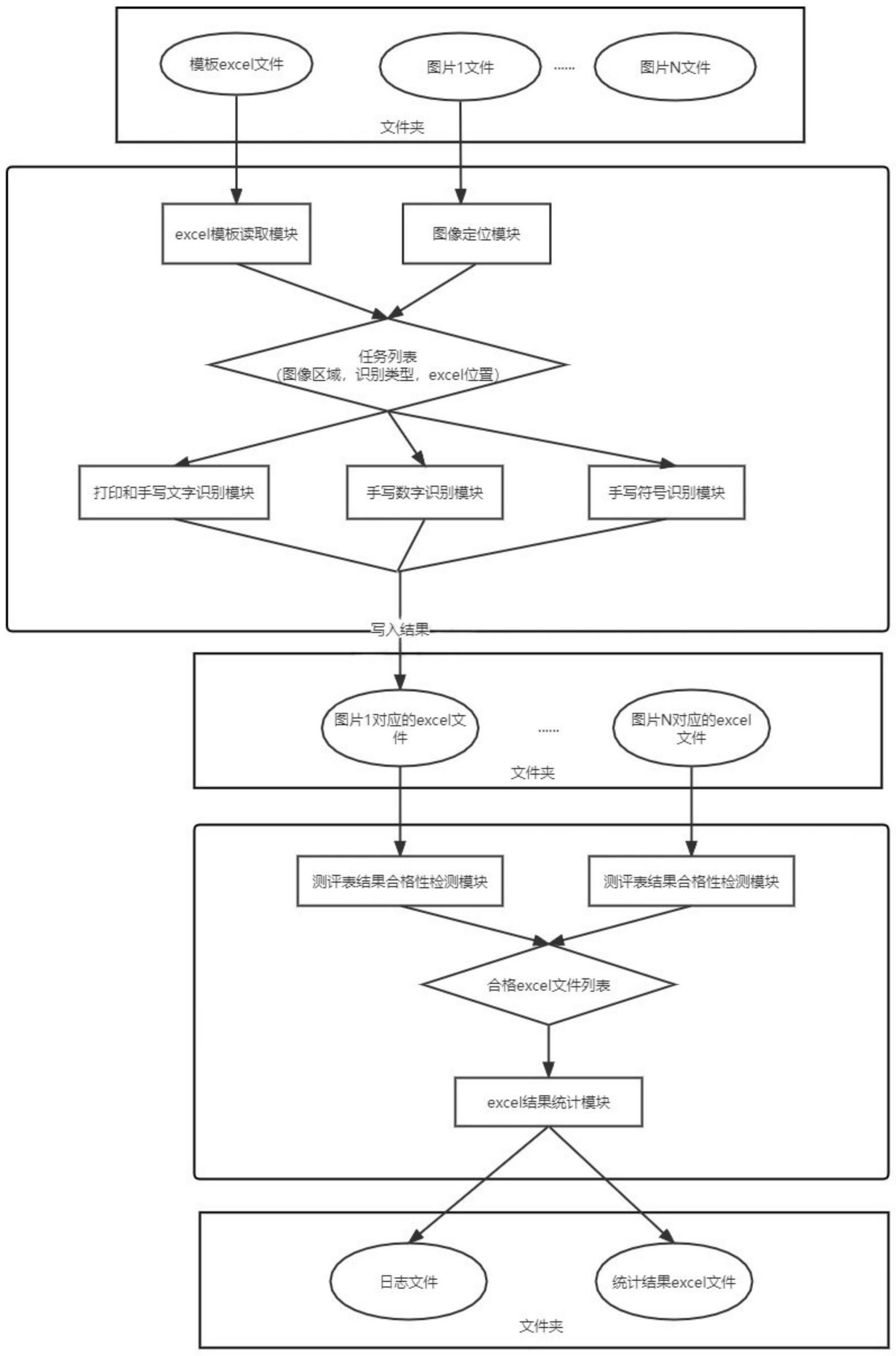
18、本发明还提供了一种基于电子表格的纸质表格内容分类识别系统,包括电子表格模板读取模块、图像定位模块、打印和手写文字识别模块、手写数字识别模块以及手写符号识别模块;其中,excel模板读取模块读入模板文件,并根据里面定义的识别内容建立任务列表;图像定位模块读取表格图片后,首先根据四个定位点进行透视变换,然后提取出待识别单元格的子图,所述任务列表中定义了单元格子图在原图中区域、识别类型、以及其在excel文件中的行列位置;打印和手写文字识别模块对定义为打印和手写文字的单元格子图进行文字识别;手写数字识别模块对定义为手写数字的单元格子图进行手写数字识别;手写符号识别模块对定义为手写符号的单元格子图进行手写符号识别,识别完的结果写入对应的excel文件中,其中该excel文件根据模板文件创建。
19、本发明还提供了一种基于电子表格的纸质表格内容分类统计系统,包括本发明所述的识别系统、测评表结果合格性检测模块以及结果统计模块,其中测评表结果合格性检测模块对针对每个表格图片转换成的excel文件进行合格性检测,其中包括一组勾选项内是否有且仅有一个项被勾选、打分项是否给出分数,如果不合格,则该测评表不纳入最终结果统计,将所有合格的excel文件记录到列表中,然后excel结果统计模块对合格文件进行勾选项总数及平均分的统计,并将统计结果写入一个excel文件,其中,该excel文件也根据模板文件创建;结果统计模块将所有合格的电子表格文件进行统计,并将统计结果输出到一份与模板格式相同的电子表格文件中。
20、有益效果:
21、1、本发明识别方法,基于待识别纸质表格构建电子表格模板,在电子表格模板中分类定义打印文字和手写文字、手写数字和手写符号,基于电子表格模板中的类别,对待识别纸质表格中的表格内容进行划分,针对划分出的不同类别内容,各自采用对应的识别算法,避免了统一的ocr识别算法对手写数字和手写符号识别率差的问题,并且本发明基于构建的电子表格模板实现对待识别纸质表格的表格结构识别,不需要深度学习模型,仅利用图像处理方法便可实现,速度快,错误率小。本发明全程无需人工干预,统计速度快,结果查询方便,无需硬件设施,成本低,大大提高了测评人员的工作效率和正确率。
22、2、本发明识别方法中,在提取单元格图片时,将四周各向外扩展一定像素,保证内容的完整性。
23、3、本发明识别方法中,由于边框线将图形分成不同区域,本发明通过找连通域的方法将边框线去掉,提取的单元格图片不包含有边框线,不会影响内容的识别。
24、4、本发明统计方法中,可以批量将待识别表格的图片转换为电子表格文件,并检验表格填写的合格性,最后对合格的待识别表格进行统计。增加对待识别表格进行合格性检验的环节,实现统计时仅统计合格的待识别表格。
25、5、本发明统计方法中,通过电子表格模板还能实现对不同类型的内容按不同方式进行统计,包括手写数字栏需要统计每栏数字的平均数,手写符合栏需要记录每栏符号的总数,手写文字栏需要将每栏文字串联。
技术特征:
1.一种基于电子表格的纸质表格内容分类识别方法,其特征在于,基于实际调查或测评所用的纸质表格构建电子表格模板,在电子表格模板中分类定义打印文字和手写文字、手写数字和手写符号,基于电子表格模板中的类别,对待识别纸质表格中的表格内容进行划分,针对划分出的不同类别内容,各自采用对应的识别算法进行识别。
2.如权利要求1所述的方法,其特征在于,电子表格模板中的识别内容定义为下面几类:
3.如权利要求2所述的方法,其特征在于,手写符号包括√,o,x,符号类别分组具体为:如果符号类标识后加有数字1,2,3...,表示这几个连续数字的单元格为一组,一组内必须有且仅有一个√,否则该测评表将被视为不合格。
4.如权利要求1-3任意一项所述的方法,其特征在于,对手写文字和打印文字采用paddle ocr算法进行识别,对手写数字、手写符号分别采用自定义的卷积神经网络模型进行识别。
5.如权利要求1-3任意一项所述的方法,其特征在于,对于待识别纸质表格进行自动转正和矫正,具体如下:
6.如权利要求5所述的方法,其特征在于,对纸质表格中的单元格进行精准切割时,首先利用模板结构预计出单元格的位置,然后扩大范围切割出单元格所在的区域,再根据边框线将单元格分为各个连通域,找出最小外接矩形最大的那个连通域,即为单元格的精准区域。
7.如权利要求6所述的方法,其特征在于,找连通域法的算法流程如下:
8.一种基于电子表格的纸质表格内容分类统计方法,其特征在于,基于如权利要求1-7任意一项所述的识别方法得到的结果,批量将识别结果转换为与所述电子表格模板格式一致的电子表格结果文件,最后对电子表格结果文件进行统计。
9.一种基于电子表格的纸质表格内容分类识别系统,其特征在于,包括电子表格模板读取模块、图像定位模块、打印和手写文字识别模块、手写数字识别模块以及手写符号识别模块;其中,excel模板读取模块读入模板文件,并根据里面定义的识别内容建立任务列表;图像定位模块读取表格图片后,首先根据四个定位点进行透视变换,然后提取出待识别单元格的子图,所述任务列表中定义了单元格子图在原图中区域、识别类型、以及其在excel文件中的行列位置;打印和手写文字识别模块对定义为打印和手写文字的单元格子图进行文字识别;手写数字识别模块对定义为手写数字的单元格子图进行手写数字识别;手写符号识别模块对定义为手写符号的单元格子图进行手写符号识别,识别完的结果写入对应的excel文件中,其中该excel文件根据模板文件创建。
10.一种基于电子表格的纸质表格内容分类统计系统,包括如权利要求9所述的识别系统、测评表结果合格性检测模块以及结果统计模块,其中测评表结果合格性检测模块对针对每个表格图片转换成的excel文件进行合格性检测,其中包括一组勾选项内是否有且仅有一个项被勾选、打分项是否给出分数,如果不合格,则该测评表不纳入最终结果统计,将所有合格的excel文件记录到列表中,然后excel结果统计模块对合格文件进行勾选项总数及平均分的统计,并将统计结果写入一个excel文件,其中,该excel文件也根据模板文件创建;结果统计模块将所有合格的电子表格文件进行统计,并将统计结果输出到一份与模板格式相同的电子表格文件中。
技术总结
本发明提出了一种基于电子表格的纸质表格内容分类识别和统计方法及系统,能够对纸质表格中不同类型内容实现分类识别以及统计,速度快,错误率小。本发明基于待识别纸质表格构建电子表格模板,在电子表格模板中分类定义打印文字和手写文字、手写数字和手写符号,基于电子表格模板中的类别,对待识别纸质表格中的表格内容进行划分,针对划分出的不同类别内容,各自采用对应的识别算法,避免了统一的OCR识别算法对手写数字和手写符号识别率差的问题。
技术研发人员:任娟,刘清珺,陈婷,邓平晔
受保护的技术使用者:北京市科学技术研究院分析测试研究所(北京市理化分析测试中心)
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!