用于深度学习的粗粒度可重构阵列算子设计方法及系统
本发明涉及深度学习加速器编译器,尤其涉及一种用于深度学习的粗粒度可重构阵列算子的设计与实现。
背景技术:
1、近年来,深度学习在计算机视觉和语音识别等任务中获得巨大的成功,在各种复杂的任务中在精度上和速度上都超过了人类水平。然而深度学习应用的高计算量、高数据量特性以及不同网络结构对芯片的算力,可编程性都提出了更高的要求。另外,随着深度学习应用在物联网,自动驾驶等嵌入式设备的部署,芯片的能效同样也是重要的考虑因素。
2、能效以及吞吐率是深度学习加速器的两个重要指标。深度学习中存在大量的完美嵌套循环,先前的编译器工作关注重点在于循环顺序以及tiling策略。循环顺序以及tiling策略共同影响dram与片上存储之间的通信量,从而决定了整个芯片的能效。然而在一些实时应用场景如自动驾驶,目标跟踪等,需要加速器快速处理海量的图像语音等信息,这些应用场景对加速器的吞吐率提出了更高的要求。粗粒度可重构阵列(coarse-grainedreconfigurable array,cgra)在深度学习应用中获得越来越多的关注。cgra的吞吐率很大程度依赖于编译器如何高效地将应用映射到cgra相应的硬件资源上,提高资源利用率,尤其是计算资源,即处理单元阵列(process elements array,pea)。然而先前cgra编译器工作鲜有涉及深度学习应用在cgra上的映射问题。
技术实现思路
1、本发明提供了一种用于深度学习的粗粒度可重构阵列算子的设计方法及系统,满足能效以及吞吐率应用于深度学习的两个重要指标,高效将应用映射到cgra相应的硬件资源上。
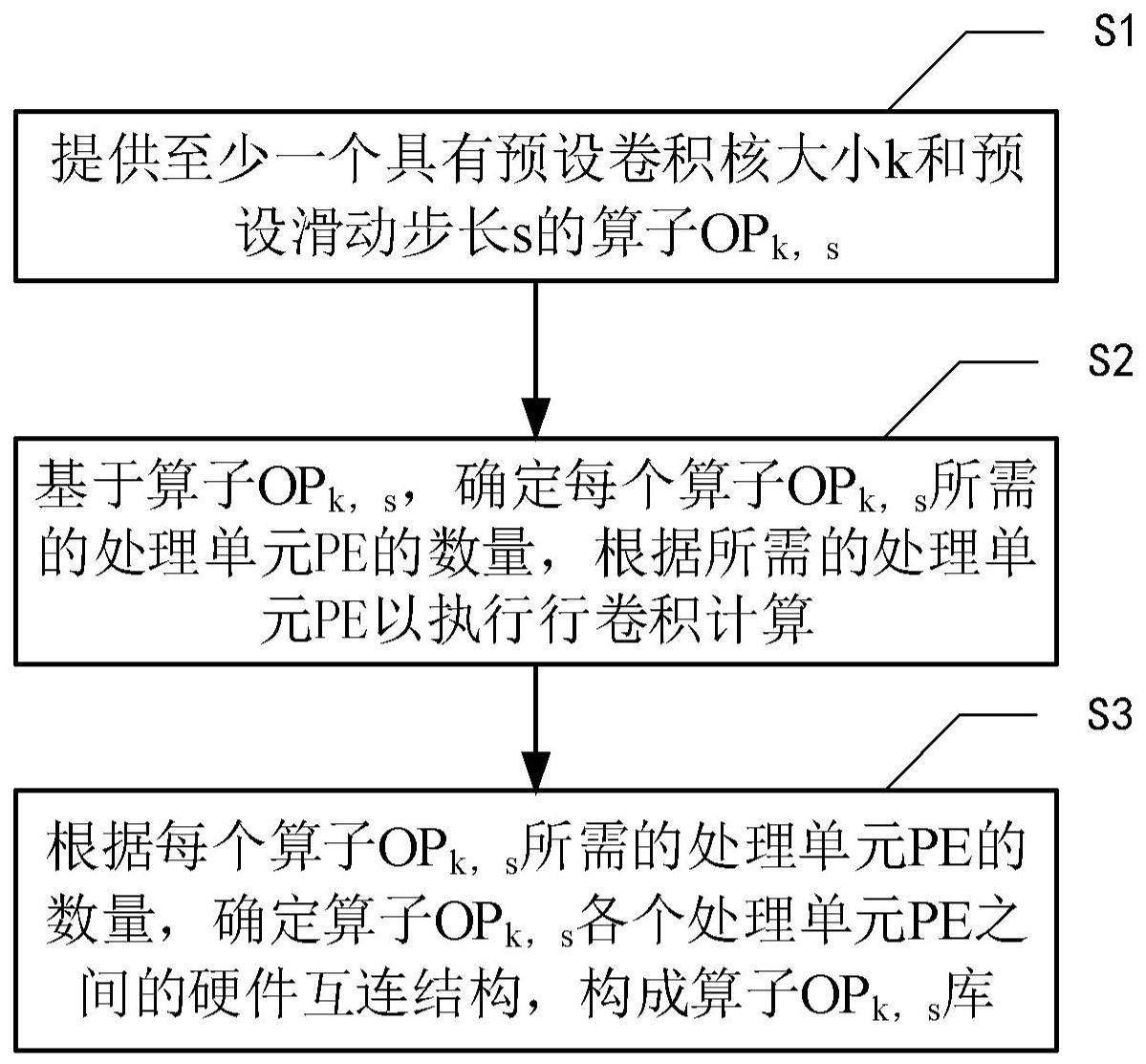
2、本发明提供了一种用于深度学习的粗粒度可重构阵列算子设计方法,包括:提供至少一个具有预设卷积核大小k和预设滑动步长s的算子opk,s,k、s≥1且为整数;基于算子opk,s,确定每个算子opk,s所需的处理单元pe的数量,根据所需的处理单元pe以执行行卷积计算,其中,pe≥1且为整数;根据每个算子opk,s所需的处理单元pe的数量,确定算子opk,s所需的各个处理单元pe之间的硬件互连结构,构成算子opk,s库。
3、根据本发明的实施例,执行行卷积计算包括:将卷积核拆分为i行,i≥1且为整数,基于所需的处理单元pe以对每行卷积核的权重向量与输入向量以窗口滑动的方式进行内积运算,得到每行卷积核的部分和;其中,窗口滑动包括:以预设步长s在每行卷积核上滑动。根据本发明的实施例,执行行卷积计算还包括:获取每行卷积核的部分和并累加,得到最终的输出特征图像。
4、根据本发明的实施例,每个算子opk,s所需的处理单元pe的数量根据以下公式来确定:
5、
6、其中,pen表示每个算子opk,s所需的处理单元pe的数量
7、根据本发明的实施例,执行行卷积计算还包括:获取窗口滑动时相邻窗口的启动间隔;当每行卷积核以窗口滑动的方式进行时,按照启动间隔依次启动内积运算,启动间隔根据以下公式来确定:
8、
9、其中,ii为启动间隔,pen为每个算子opk,s所需的处理单元pe的数量,q为单行滑动窗口内的内积运算中乘累加的数量。
10、根据本发明的实施例,所需的处理单元pe之间的硬件互连结构包括以行排布、以列排布或以l型排布的多种排布方式。
11、根据本发明的实施例,提供每行卷积核的权重向量以及输入特征图的向量;获取输入特征图中的起始位置以及数据长度,根据起始位置以及数据长度进行窗口的滑动以及内积运算。
12、根据本发明的另一实施例,提供了一种用于实现上述任一实施例的用于深度学习的粗粒度可重构阵列算子设计系统,包括:控制器,用于向至少一个处理单元pe输入信息,其中,输入信息包括权重向量、输入向量、状态指令和操作指令,状态指令用于确定操作指令的执行状态,操作指令用于至少一个处理单元pe计算权重向量和输入向量的内积;输入总线,用于向至少一个处理单元pe输入权重向量和输入向量;配置总线,用于向至少一个处理单元pe输入状态指令和操作指令;处理单元阵列pea,包括多个处理单元pe,每个处理单元pe用于根据操作指令对权重向量与输入向量进行内积运算,得到内积结果;输出总线,用于供至少一个处理单元pe输出内积结果。
13、根据本发明的另一实施例,处理单元阵列pea共有m列n行,m≥1且为整数,n≥1且为整数,其中:每列处理单元pe共享一根输入总线;每行处理单元pe共享一根输出总线;每列处理单元pe共享一根配置总线。
14、根据本发明的另一实施例,处理单元pe包括:指令寄存子单元,用于存储操作指令和状态指令;指令解码子单元,用于解码操作指令和状态指令;权重寄存子单元,用于存储权重向量或输入向量;本地寄存子单元,用于存储中间数据;逻辑运算子单元,用于根据操作指令对权重向量和输入向量进行内积运算,得到内积结果。
15、与现有技术相比,本发明提供的用于深度学习的粗粒度可重构阵列算子设计方法,至少具有以下有益效果:
16、以最大化资源利用率为目标,在满足存储和输入输出带宽资源约束下,将尽可能多的相同或不同的算子实现映射到粗粒度可重构阵列上,基于行卷积计算,在不同数量的处理单元pe下,软件流水化每种算子,同时分析不同的启动间隔下算子对输入数据的需求。同时,不同算子对应不同的硬件实现,实现多种处理单元pe互连结构,所有的硬件实现构成算子库,为深度学习应用映射方法提供了新的解决思路。
技术特征:
1.一种用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,包括:
2.根据权利要求1所述的用于深度学习的粗粒度可重构阵列算子设计方法,所述执行行卷积计算包括:
3.根据权利要求2所述的用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,所述执行行卷积计算还包括:获取每行卷积核的部分和并累加,得到最终的输出特征图像。
4.根据权利要求2所述的用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,所述每个所述算子opk,s所需的处理单元pe的数量根据以下公式来确定:
5.根据权利要求4所述的用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,所述执行行卷积计算还包括:
6.根据权利要求1所述的用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,所述所需的处理单元pe之间的的硬件互连结构包括以行排布、以列排布或以l型排布的多种排布方式。
7.根据权利要求2所述的用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,所述每行卷积核通过窗口滑动前还包括:
8.一种用于深度学习的粗粒度可重构阵列算子设计系统,用于实现如权利要求1-7中任一项所述的用于深度学习的粗粒度可重构阵列算子设计方法,其特征在于,所述系统包括:
9.根据权利要求8所述的用于深度学习的粗粒度可重构阵列算子设计系统,其特征在于,所述处理单元阵列pea共有m列n行,m≥1且为整数,n≥1且为整数,其中:
10.根据权利要求9所述的用于深度学习的粗粒度可重构阵列算子设计系统,其特征在于,所述处理单元pe包括:
技术总结
本发明提供了一种用于深度学习的粗粒度可重构阵列算子设计方法及系统,涉及深度学习加速器编译器技术领域。该方法包括:提供至少一个具有预设卷积核大小k和预设滑动步长s的算子OP<subgt;k,s</subgt;,k、s≥1且为整数;基于算子OP<subgt;k,s</subgt;,确定每个算子OP<subgt;k,s</subgt;所需的处理单元PE的数量,根据所述所需的处理单元PE以执行行卷积计算,其中,PE≥1且为整数;根据每个算子OP<subgt;k,s</subgt;所需的处理单元PE的数量,确定算子所需的各个处理单元PE之间的硬件互连结构,构成算子OP<subgt;k,s</subgt;库。
技术研发人员:陈松,倪小兵,何凯旋,陶永进,孙文迪,康一
受保护的技术使用者:中国科学技术大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!