一种分布式大数据组件统一服务引擎设计方法与流程
本发明涉及服务引擎,具体而言,涉及一种分布式大数据组件统一服务引擎设计方法、设备和计算机可读存储介质。
背景技术:
1、本发明对于背景技术的描述属于与本发明相关的相关技术,仅仅是用于说明和便于理解本发明的
技术实现要素:
,不应理解为申请人明确认为或推定申请人认为是本发明在首次提出申请的申请日的现有技术。
2、随着互联网急速发展,大量互联网公司开始研发大数据平台,表现为对组件技术和数据的统一整合,对开发的低成本期望也越来越高,这些变化催生了对大数据平台的变革和创新。但是如何高效整合大数据组件并对外开放接口功能成为了大数据平台亟待解决的问题。特别是与后端及其他技术部门的解耦和使用成为了大数据平台要解决的问题之一。
3、目前大数据平台通常采用spark、flink计算框架作为平台的离线引擎和实时引擎,主流hadoop、hive进行存储和资源调度,并结合其他大数据生态组件来满足用户对数据进行查询和计算的需求。传统的做法是将hdfs、hive、kafka等较为简单的大数据组件的基本操作放在后端微服务系统中,由后端维护;而spark、flink较为复杂的大数据引擎则放在大数据部门进行研发和维护。对于前者来讲实现简单,但是如果后端和大数据部门基于某个组件涉及到相同业务时,则需要两个部门同时修改内部逻辑,这在开发的时候无疑带来了巨大的精力消耗;对于后者来讲,将spark、flink较为复杂的大数据引擎放在大数据部门研发虽然能够解决两个部门同时修改内部逻辑的问题,但对于启动spark、flink作业时,仍需将两个作业放置到后端的微服务系统中,这种每修改一次再将新的作业jar包放置到后端服务中进行验证,这种方式无疑增加了使用的开销,降低工作效率。综上,以往大数据平台研发采用何种处理方式,都不能解决对于各部门技术解耦问题。
4、为了解决上述技术问题,本发明提出了一种分布式大数据组件统一服务引擎设计方法、设备和计算机可读存储介质,通过大数据计算框架组织和对外开放服务接口的方式整合大数据生态组件和计算,降低了开发难度、使用开销,提升了工作效率。
技术实现思路
1、本发明提供了一种分布式大数据组件统一服务引擎设计方法、设备和计算机可读存储介质,通过大数据计算框架组织和对外开放服务接口的方式整合大数据生态组件和计算,降低了开发难度、使用开销,提升了工作效率。
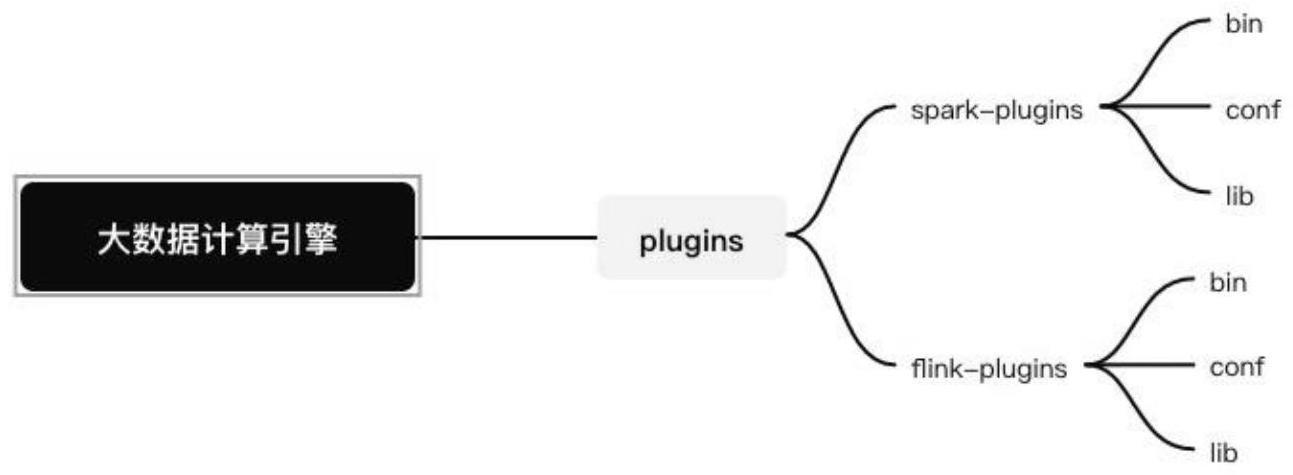
2、本发明第一方面的实施例提供了一种分布式大数据组件统一服务引擎设计方法,包括如下步骤:根据大数据计算框架spark/flink的特点,在系统中以jonname-plugins-module的组织方式来引用相关业务开发的源码包和配置文件以及启动脚本,不依赖其他jar包,提供大数据计算引擎中核心的计算引擎层;对具有相同特点的计算框架按照上述步骤进行添加,并通过前缀进行区分。
3、优选地,还包括如下步骤:大数据计算引擎通过engine-module的组织方式将大数据生态组件进行整合。
4、优选地,整合操作包括如下步骤:通过engine-hbase模块整合hbase-api相关操作,提供hbase核心操作支撑能力并作为大数据计算引擎系统中hbase底层处理引擎;通过engine-hive模块整合hive-api相关操作,提供hive核心操作支撑能力并作为大数据计算引擎系统中hive底层处理引擎;通过engine-kafka模块整合kafka-api相关操作,提供kafka核心操作支撑能力并作为大数据计算引擎系统中kafka底层处理引擎;通过engine-hdfs模块整合hdfs-api相关操作,提供hdfs核心操作支撑能力并作为大数据计算引擎系统中hdfs底层处理引擎;通过engine-yarn模块整合yarn-api相关操作,提供yarn核心操作支撑能力并作为大数据计算引擎系统中yarn底层处理引擎。
5、优选地,整合操作中的各个步骤均不依赖外部模块。
6、优选地,还包括如下步骤:大数据计算引擎通过spring-controller技术对外提供服务访问接口,并根据业务和处理引擎分为多个controller层,controller层包括:hbasecontroller层、hivecontroller层、kafkacontroller层、taskcontroller层、yarnexplorecontroller层。
7、优选地,还包括如下步骤:大数据计算引擎对外服务采用spring-cloud技术进行整合,所有对外接口均可通过open-feign方式进行访问,在系统中有单独的feign模块开发,后端可通过maven私服的方式将开发好的feign拉到后端服务中进行访问。
8、优选地,还包括如下步骤:大数据计算引擎通过nacos作为统一服务注册中心,对外提供域名供后端及其他技术部门进行服务访问。
9、优选地,还包括如下步骤:大数据计算引擎通过service-module模块进行业务处理,将引擎层和对外服务层进行分离。
10、本发明第二方面的实施例还提供了一种分布式大数据组件统一服务引擎设计设备,其包括存储器和处理器;其中,存储器用于存储可执行程序代码;处理器用于读取存储器中存储的可执行程序代码以执行分布式大数据组件统一服务引擎设计方法。
11、本发明第三方面的实施例还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现分布式大数据组件统一服务引擎设计方法。
12、本发明提供的分布式大数据组件统一服务引擎设计方法、设备和计算机可读存储介质,通过大数据计算框架组织和对外开放服务接口的方式整合大数据生态组件和计算,降低了开发难度、使用开销,提升了工作效率。
13、本发明的附加方面和优点将在下面的描述部分中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种分布式大数据组件统一服务引擎设计方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的分布式大数据组件统一服务引擎设计方法,其特征在于,还包括如下步骤:所述大数据计算引擎通过engine-module的组织方式将大数据生态组件进行整合。
3.根据权利要求2所述的分布式大数据组件统一服务引擎设计方法,其特征在于,所述整合操作包括如下步骤:
4.根据权利要求3所述的分布式大数据组件统一服务引擎设计方法,其特征在于,所述整合操作中的各个步骤均不依赖外部模块。
5.根据权利要求1所述的分布式大数据组件统一服务引擎设计方法,其特征在于,还包括如下步骤:所述大数据计算引擎通过spring-controller技术对外提供服务访问接口,并根据业务和处理引擎分为多个controller层,所述controller层包括:hbasecontroller层、hivecontroller层、kafkacontroller层、taskcontroller层、yarnexplorecontroller层。
6.根据权利要求1所述的分布式大数据组件统一服务引擎设计方法,其特征在于,还包括如下步骤:所述大数据计算引擎对外服务采用spring-cloud技术进行整合,所有对外接口均可通过open-feign方式进行访问,在系统中有单独的feign模块开发,后端可通过maven私服的方式将开发好的feign拉到后端服务中进行访问。
7.根据权利要求1所述的分布式大数据组件统一服务引擎设计方法,其特征在于,还包括如下步骤:所述大数据计算引擎通过nacos作为统一服务注册中心,对外提供域名供后端及其他技术部门进行服务访问。
8.根据权利要求1-7中任意一项所述的分布式大数据组件统一服务引擎设计方法,其特征在于,还包括如下步骤:所述大数据计算引擎通过service-module模块进行业务处理,将引擎层和对外服务层进行分离。
9.一种分布式大数据组件统一服务引擎设计设备,其包括存储器和处理器;其中,所述存储器用于存储可执行程序代码;所述处理器用于读取所述存储器中存储的可执行程序代码以执行根据权利要求1-8任意一项所述的分布式大数据组件统一服务引擎设计方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1-8任意一项所述的分布式大数据组件统一服务引擎设计方法。
技术总结
本发明提供了一种分布式大数据组件统一服务引擎设计方法、设备和计算机可读存储介质,方法包括如下步骤:根据大数据计算框架spark/flink的特点,在系统中以jonName‑plugins‑module的组织方式来引用相关业务开发的源码包和配置文件以及启动脚本,不依赖其他jar包,提供大数据计算引擎中核心的计算引擎层;对具有相同特点的计算框架按照上述步骤进行添加,并通过前缀进行区分。本发明提供的分布式大数据组件统一服务引擎设计方法、设备和计算机可读存储介质,通过大数据计算框架组织和对外开放服务接口的方式整合大数据生态组件和计算,降低了开发难度、使用开销,提升了工作效率。
技术研发人员:杨娟,杨再飞,翟士丹,高亮
受保护的技术使用者:北京海致星图科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!