一种基于K最近邻图的分布外检测技术
本发明涉及计算机视觉和深度学习,具体为一种基于k最近邻图的分布外检测技术。
背景技术:
1、近年来,随着科技的发展,深度神经网络已经在计算机视觉、文本等领域展现出优越的性能。在封闭设置下,训练和测试数据从同一分布中采样,神经网络可以表现出非常好的性能。然而,在实际应用中部署神经网络时,神经网络会接收到很多训练数据集所包含的类别以外的数据,而此时神经网络会给出意料之外的输出。最近的研究表明,即使对于完全无法识别的输入或不相关的输入,神经网络也倾向于做出高置信度的预测。而在自动驾驶领域和医学领域,如果神经网络把从未见过的输入以高置信度给出错误的输出,会有很大的隐患。而理想的情况是,神经网络应该主动意识到自己接收到的输入是自己无法进行分类或处理的,此时应该给予该分布外示例很大的不确定性,并交给人类进行处理。
2、分类器在遇到新类型的输入,即分布外示例时,意识到不确定性至关重要。因此,能够准确地检测分布外的例子对于视觉识别任务是很重要的一环。
3、现有的技术方案主要有:
4、1.基于距离的方法:利用从模型中提取的特征嵌入,来计算测试数据和训练数据的距离,以此来进行分布外检测。
5、2.基于密度的方法:通过对数据密度进行建模来对分布外数据进行检测。
6、3.基于分类的方法:通过依赖分类器给出的分类分数来进行分布外检测。
7、但上述现有技术方案具有:基于距离的方法都对底层特征空间是类条件高斯分布做出了强分布假设。但是这个假设不一定准确,因为特征空间的分布往往是高维度的,假设为高斯分布可能会限制分布外检测性能。基于密度的方法,需要对分布内数据集的分布进行建模,但是由于分布内数据集也是多种多样的,并且数据集的分布是以高维度的形式呈现的,因此想要比较好的建模出数据的分布,需要比较大的计算资源和时间。基于分类的方法,分布外检测性能很大程度上取决于分类模型的性能,所以效果也不是很稳定,因此需要进行改进。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于k最近邻图的分布外检测技术,具备面对海量不同的的数据,需要不对数据的分布进行假设来进行分布外检测;并且需要利用好分布内数据的最具有全局代表性的特征,更好地划分决策边界;需要节省计算资源和时间。从而实现一种更快的、非参、高效的分布外检测方法,可以更好地划分决策边界,更快的找到分布内数据的最重要的特征,解决了对底层特征空间做出不准确的分布假设、占用大量计算资源和时间、分布外检测性能太依赖分类模型性能的问题。
3、(二)技术方案
4、为实现上述面对海量不同的的数据,需要不对数据的分布进行假设来进行分布外检测;并且需要利用好分布内数据的最具有全局代表性的特征,更好地划分决策边界;需要节省计算资源和时间。从而实现一种更快的、非参、高效的分布外检测方法,可以更好地划分决策边界,更快的找到分布内数据的最重要的特征的目的,本发明提供如下技术方案:
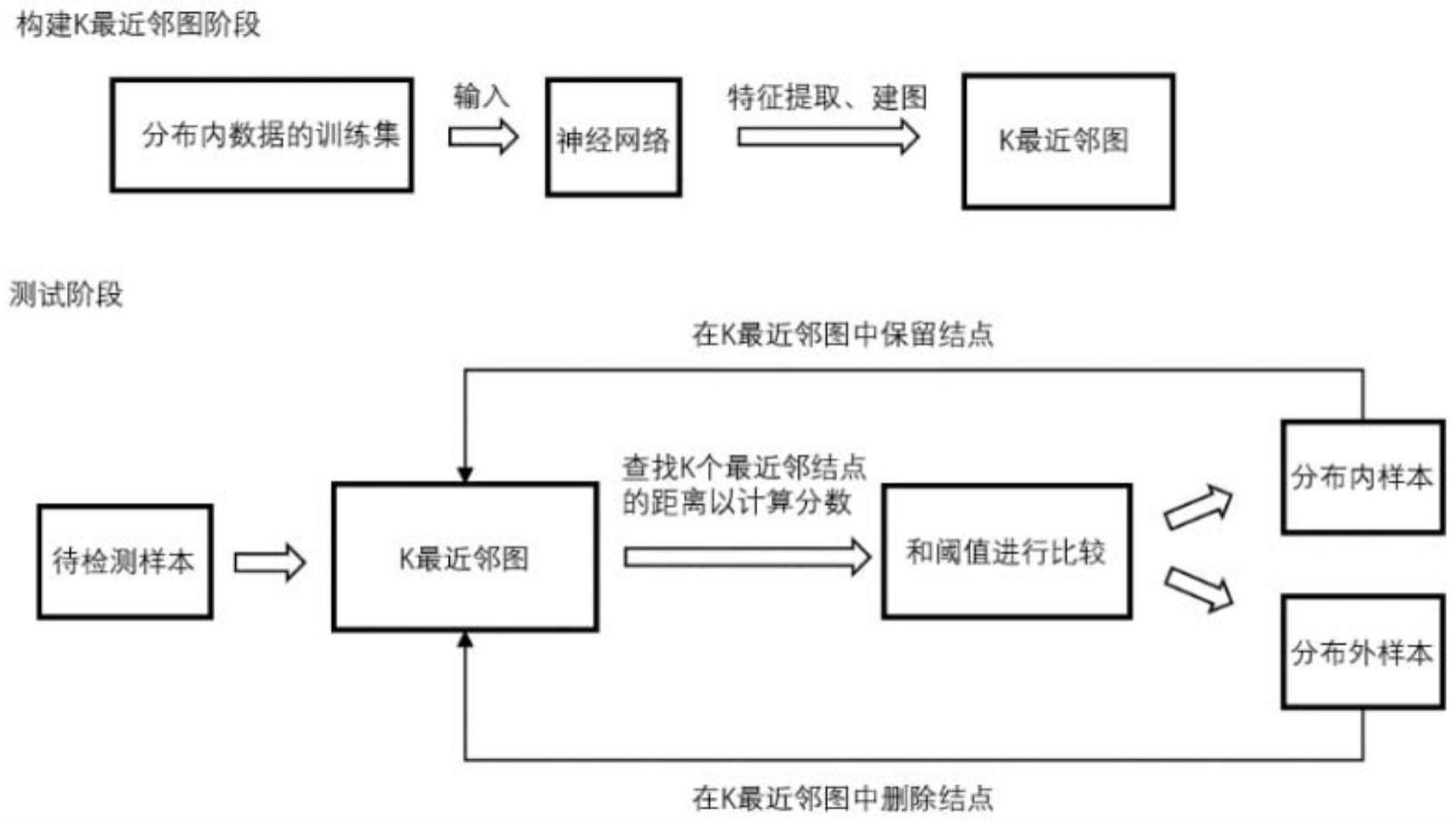
5、一种基于k最近邻图的分布外检测技术,包括以下步骤:
6、s1、首先使用神经网络中的特征提取器对数据集中的每个样本x进行特征提取,提取的特征是神经网络倒数第二层的特征;
7、s2、使用分布内数据的训练数据集的特征初始化k最近邻图,用图中的每一个结点zi表示每一个样本的特征,i是分布内数据集中样本的id号,让每个特征结点随机指向另外k个不同的特征结点,同时计算有指向关系的两个结点的特征的距离,以随机初始化k最近邻图,距离采用余弦相似度s,经过初始化之后,每个样本都会指向k个邻居结点;
8、s3、对初始化之后的k最近邻图进行优化重建,随机选择一个结点zi的特征,并和随机k个结点的特征计算余弦相似度,以搜索距离自己更近的结点,如果找到距离特征结点zi更近的特征结点,则把zi结点所指向的较远的结点更新为更近的结点;
9、s4、然后再重复进行多次第三步的操作,如果超过5次发现没有再找到更近的结点,则认为k最近邻图已经重建完成。
10、优选的,所述步骤s1中,针对参数x具有以下公式:
11、z=h(x)。
12、优选的,所述步骤s2中,余弦相似度的数学表达式如下,zi和z′j分别代表不同的样本的特征:
13、
14、优选的,所述步骤s4中,在测试阶段,把测试样本x的特征也当成一个新结点,首先指向k最近邻图中随机k个结点,并分别与其特征计算全局代表性权重特征距离l,样本x通过反复和最近邻居结点的k个邻居结点进行计算l距离,并更新结点x指向更近结点的操作,直到最终找到和结点x距离最近的k个结点,距离l的计算公式如下:
15、l(x,zi)=s(x,zi)*r(zi)。
16、优选的,所述r是一个特征结点的全局代表性,由该结点的入度计算得到,全局代表性越大,则表示该结点所表示的特征越能代表分布内数据,全局代表性由以下公式表示,其中ii是k最近邻图中id为i的结点的入度,是所有大于0的ii的平均值:
17、
18、优选的,所述步骤s4中,利用测试样本x和样本x最近的k个训练数据的距离的均值作为分布外检测的分数,进行分布外检测,如果距离大于等于阈值,则把样本x识别为分布外数据,并且在图中删除代表样本x的结点和k个指向k个邻居结点的边;如果距离小于阈值,则认为样本x是分布内数据,且保留代表样本x的结点和其指向k个结点的边,并把边的距离从距离l修改为余弦相似度。
19、优选的,所述阈值的设置因不同训练数据集而异,阈值的设置,需要确保95%的id数据被正确分类,分布外检测的分数的表达式如下,其中和测试样本最近的k个距离为{l1,l2,l3,…,lk}:
20、
21、(三)有益效果
22、与现有技术相比,本发明提供了一种基于k最近邻图的分布外检测技术,具备以下有益效果:
23、1、该基于k最近邻图的分布外检测技术,通过构建k最近邻图,加快了搜索最近邻结点的速度。
24、2、该基于k最近邻图的分布外检测技术,在计算特征距离的时候,在余弦相似度的基础上,增加特征的全局代表性的权重,充分利用了更具分布内全局代表性的特征,大大提高了分布外检测的性能。
技术特征:
1.一种基于k最近邻图的分布外检测技术,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于k最近邻图的分布外检测技术,其特征在于,所述步骤s1中,针对参数x具有以下公式:
3.根据权利要求1所述的一种基于k最近邻图的分布外检测技术,其特征在于,所述步骤s2中,余弦相似度的数学表达式如下,zi和zj′分别代表不同的样本的特征:
4.根据权利要求1所述的一种基于k最近邻图的分布外检测技术,其特征在于,所述步骤s4中,在测试阶段,把测试样本x的特征也当成一个新结点,首先指向k最近邻图中随机k个结点,并分别与其特征计算全局代表性权重特征距离l,样本x通过反复和最近邻居结点的k个邻居结点进行计算l距离,并更新结点x指向更近结点的操作,直到最终找到和结点x距离最近的k个结点,距离l的计算公式如下:
5.根据权利要求4所述的一种基于k最近邻图的分布外检测技术,其特征在于,所述r是一个特征结点的全局代表性,由该结点的入度计算得到,全局代表性越大,则表示该结点所表示的特征越能代表分布内数据,全局代表性由以下公式表示,其中ii是k最近邻图中id为i的结点的入度,是所有大于0的ii的平均值:
6.根据权利要求1所述的一种基于k最近邻图的分布外检测技术,其特征在于,所述步骤s4中,利用测试样本x和样本x最近的k个训练数据的距离的均值作为分布外检测的分数,进行分布外检测,如果距离大于等于阈值,则把样本x识别为分布外数据,并且在图中删除代表样本x的结点和k个指向k个邻居结点的边;如果距离小于阈值,则认为样本x是分布内数据,且保留代表样本x的结点和其指向k个结点的边,并把边的距离从距离l修改为余弦相似度。
7.根据权利要求6所述的一种基于k最近邻图的分布外检测技术,其特征在于,所述阈值的设置因不同训练数据集而异,阈值的设置,需要确保95%的id数据被正确分类,分布外检测的分数的表达式如下,其中和测试样本最近的k个距离为{l1,l2,l3,…,lk}:
技术总结
本发明涉及计算机视觉和深度学习技术领域,且公开了基于K最近邻图的分布外检测技术,首先使用神经网络对分布内训练数据进行特征提取;其次把分布内数据集的特征作为结点,使用这些结点初始化并重建K最近邻图;测试时,在K最近邻图中搜索测试样本的K个最近邻结点,并为测试样本计算分布外检测分数;如果分布外检测分数小于阈值,则判断测试样本为分布内数据,并把代表该样本的结点加入K最近邻图,否则判断该测试样本为分布外数据。该基于K最近邻图的分布外检测技术,通过构建K最近邻图,加快了搜索最近邻结点的速度;在计算特征距离的时候,在余弦相似度的基础上,增加特征的全局代表性的权重,充分利用了更具分布内全局代表性的特征。
技术研发人员:唐可可,蔡旭健,彭伟龙,李树栋,李默涵,王乐
受保护的技术使用者:广州大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!