文档匹配方法及系统与流程
本发明涉及自然语言处理,具体而言涉及一种政策文档指标匹配方法及系统。
背景技术:
1、由于政策文件种类繁多,从中小型企业到大型企业,不同企业对应的政策文件不同,企业或者个人想要从大量的政策文件中挖掘出对自己有用的信息,是一件费时费力的工作。
2、目前,企业想要和政策文件中的指标进行匹配,通常采用人工匹配的方式,在政策文件中寻找对应的指标知识,再和公司的资质进行对比,由于人工匹配的方式容易出现错漏,导致一些重要指标知识点往往被忽略,对企业和个人会造成一定的损失影响,因此,如何实现对各类政策文件的统一管理规划、政策文件的信息化建设,如何实现企业全面的、准确的政策指标挖掘,是一个必要解决的难题。
技术实现思路
1、本发明目的在于提供一种文档匹配方法,能够解决现有企业通过人工匹配方式进行资质匹配而导致的效率低下、错漏众多、损失影响较大的问题。
2、为实现上述目的,本发明所采用的技术方案如下:
3、文档匹配方法,包括:
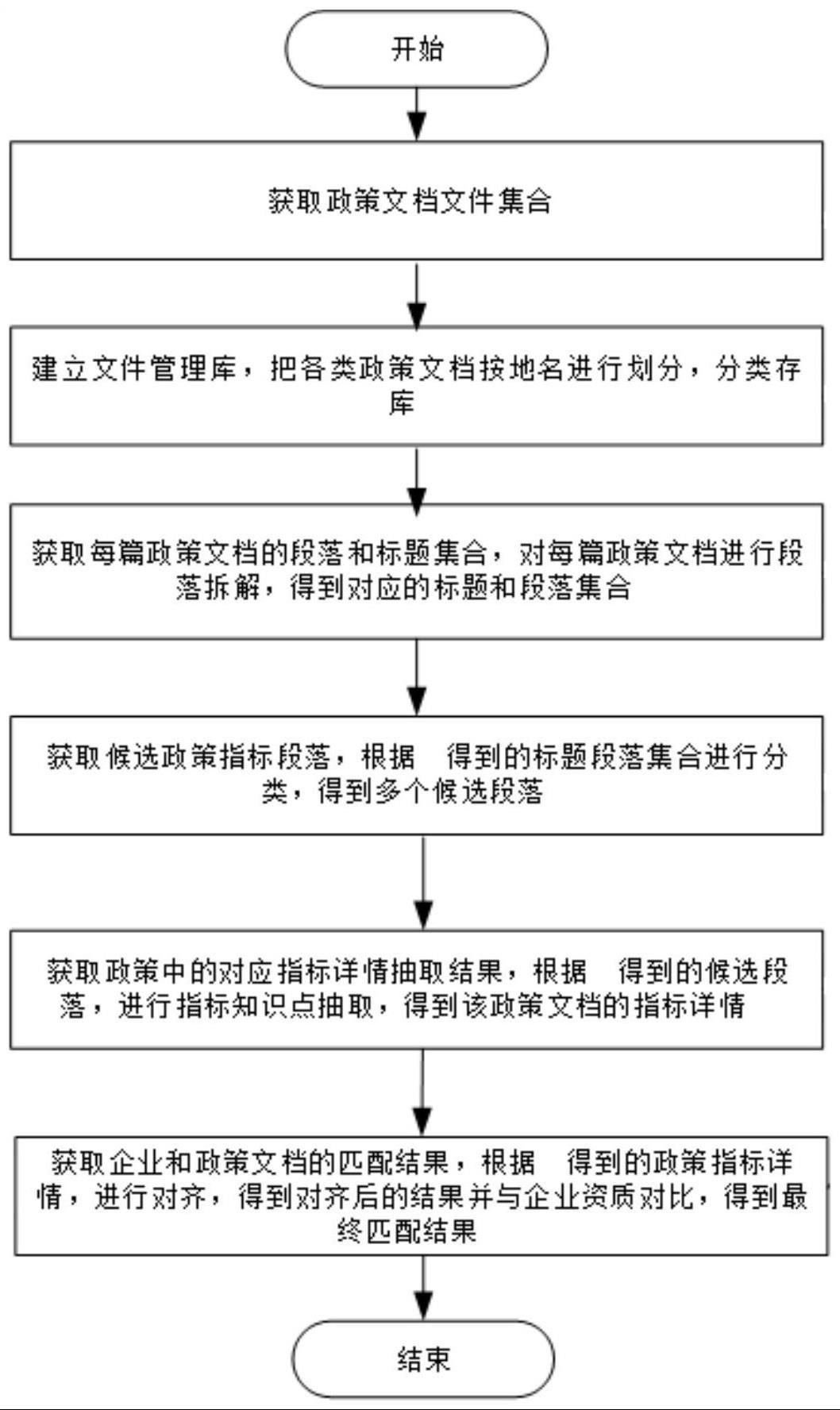
4、步骤1、获取政策文档,形成政策文档集合p;
5、步骤2、划分所述政策文档,以地名为依据,分类存储于文件管理库t中;
6、步骤3、拆解所述文件管理库t中政策文档的标题、段落,得到标题和段落集合k;
7、步骤4、分类所述标题和段落集合k,得到候选政策指标段落l;
8、步骤5、抽取所述候选政策指标段落l中的指标知识点,得到政策文档的指标详情w;
9、步骤6、对齐所述指标详情w,根据对齐后的结果与企业资质进行对比,得到企业和政策文档指标的匹配结果q。
10、优选地,前述步骤2中,划分所述政策文档,以地名为依据,分类存储于文件管理库t中,包括:
11、建立文件管理库t,所述文件管理库t包含多个不同地级市名称的地名文件和一个无地级市名称的无地名文件;
12、利用实体识别模型对所述政策文档的政策标题进行识别,得到所述政策文档的地名标题;
13、若所述政策文档的地名标题包含地级市名称,则将所述政策文档存放于对应地级市名称的地名文件;
14、若所述政策文档的地名标题不包含地级市名称,则将所述政策文档存放于无地名文件。
15、优选地,前述步骤3中,拆解所述文件管理库t中政策文档的标题、段落,包括:
16、利用标题段落解析模型,将所述文件管理库t中的政策文档拆解成标题和段落,得到对应的标题和段落集合k。
17、优选地,前述步骤4中,分类所述标题和段落集合k,得到候选政策指标段落l,包括:
18、基于bert建立政策候选段落分类模型;
19、将所述标题和段落集合k做为所述政策候选段落分类模型的输入;
20、利用bert预训练语言模型并将其作为特征提取层,获得段落编码器特征;
21、添加全连接层,对段落编码器进行分类,判断该段落是否为候选段落;
22、若该段落是候选段落,则标记为候选政策指标段落l;
23、若该段落不是候选段落,则忽略。
24、优选地,前述步骤5中,抽取所述候选政策指标段落l中的指标知识点,得到政策文档的指标详情w,包括:
25、利用指标抽取模型对所述候选政策指标段落l进行抽取;
26、基于bert预训练语言模型提取所述候选政策指标段落l中句子的上下文特征,获得指标知识点;
27、利用指针的方式分别预测所述指标知识点的开始位置和结束位置,得到指标详情w。
28、优选地,利用指针的方式分别预测所述指标知识点的开始位置和结束位置,其预测的计算公式如下:
29、
30、
31、其中,表示待抽取句子中第i个token是指标详情开始位置的概率,表示待抽取句子中第i个token是指标详情结束位置的概率,hi全连接后的隐层状态,w(.)表示模型训练的权重,b(.)为偏执项。
32、优选地,前述步骤6中,对齐所述指标详情w,包括:
33、将指标详情w划分为三种类型,所述三种类型包括文本、时间和数值;
34、将文本类的指标详情对齐,形成文本类指标详情;
35、将时间类的指标详情对齐,形成时间类指标详情;
36、将数值类的指标详情对齐,形成数值类指标详情。
37、优选地,前述步骤6中,得到企业和政策文档指标的匹配结果q,包括:
38、将对齐后的指标详情w与企业资质进行匹配,若匹配结果一致,则返回匹配;
39、若匹配结果不一致,则返回不匹配。
40、根据本发明目的的第二方面,还提出一种文档匹配系统,包括:
41、一个或多个处理器;
42、存储器,存储可被操作的指令,所述指令在通过所述一个或多个处理器执行时使得所述一个或多个处理器执行操作,所述操作包括如所述文档匹配方法的流程。
43、与现有技术相比,本发明所达到的有益效果在于:本发明通过将非结构化的政策文档转化为结构化的知识图谱进行存储,并建立政策文档管理库,依据地名对政策文档进行保存,方便对政策文档的统一管理,同时,通过本发明提供的文档匹配方法,能够直接与企业资质进行匹配,与人工匹配的方式相比,本发明方法能够大幅度提高匹配效率,降低重要指标的错漏率。
44、应当理解,前述构思以及在下面更加详细地描述的额外构思的所有组合只要在这样的构思不相互矛盾的情况下都可以被视为本公开的发明主题的一部分。另外,所要求保护的主题的所有组合都被视为本公开的发明主题的一部分。
45、结合附图从下面的描述中可以更加全面地理解本发明教导的前述和其他方面、实施例和特征。本发明的其他附加方面例如示例性实施方式的特征和/或有益效果将在下面的描述中显见,或通过根据本发明教导的具体实施方式的实践中得知。
技术特征:
1.一种文档匹配方法,其特征在于,包括:
2.根据权利要求1所述的文档匹配方法,其特征在于,前述步骤2中,划分所述政策文档,以地名为依据,分类存储于文件管理库t中,包括:
3.根据权利要求1或2所述的文档匹配方法,其特征在于,前述步骤3中,拆解所述文件管理库t中政策文档的标题、段落,包括:
4.根据权利要求3所述的文档匹配方法,其特征在于,前述步骤4中,分类所述标题和段落集合k,得到候选政策指标段落l,包括:
5.根据权利要求1所述的文档匹配方法,其特征在于,前述步骤5中,抽取所述候选政策指标段落l中的指标知识点,得到政策文档的指标详情w,包括:
6.根据权利要求5所述的文档匹配方法,其特征在于,利用指针的方式分别预测所述指标知识点的开始位置和结束位置,其预测的计算公式如下:
7.根据权利要求1所述的文档匹配方法,其特征在于,前述步骤6中,对齐所述指标详情w,包括:
8.根据权利要求7所述的文档匹配方法,其特征在于,前述步骤6中,得到企业和政策文档指标的匹配结果q,包括:
9.一种文档匹配系统,其特征在于,包括:
技术总结
本发明提供一种文档匹配方法及系统,包括:获取政策文档,形成政策文档集合P;划分所述政策文档,分类存储于文件管理库T中;拆解所述文件管理库T中政策文档的标题、段落,得到标题和段落集合K;分类所述标题和段落集合K,得到候选政策指标段落L;抽取所述候选政策指标段落L中的指标知识点,得到政策文档的指标详情W;对齐所述指标详情W,根据对齐后的结果与企业资质进行对比,得到企业和政策文档指标的匹配结果Q。本发明方法能够直接与企业资质进行匹配,与现有的人工匹配方式相比,本发明能够大幅度提高匹配效率,降低重要指标的错漏率。
技术研发人员:李平,杜振东,王清琛
受保护的技术使用者:南京云问网络技术有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!