提高存算一体化系统性能的静态计算划分方法
本发明属于计算机,更具体地,本发明涉及一种提高存算一体化系统性能的静态计算划分方法。
背景技术:
1、随着大数据、深度学习、人工智能等新兴领域的蓬勃发展,应用的数据集不断增大,信息处理逐渐由传统的“计算密集型”向“访存密集型”转移。近十年来,随着硅基电子器件逼近物理极限,摩尔定律濒临失效,中央处理器(central processing unit,cpu)的性能难以高速、持续地提升。同时,传统存储器件无法兼具“高速度”与“高密度”的特点,导致现有以计算为核心的冯·诺依曼结构严重依赖层次化存储结构以获得系统性能与存储容量的折中。而大数据时代下离散化、随机化的数据访问致使层次化存储的效率断崖式下降甚至濒临失效,数据频繁在处理器和多级存储间搬运,产生了带宽受限、计算效率下降、计算能效低下等一系列问题。传统冯·诺依曼结构计算机正遭受严峻挑战,难以满足智能社会对计算的需求。
2、为了缓解甚至打破存储墙,目前主要的技术路线是彻底打破冯·诺依曼结构中“存算分离”的固有思想,从底层架构进行突破,对计算机体系结构进行重新设计,这一技术路线被称为存算一体化体系结构(processing-in-memory,pim)。存算一体化体系结构的主要思想是在存内集成计算单元,利用存内的超高带宽和低访问延迟,实现近数据计算。近年来,3d堆叠内存、硅通孔技术(through-silicon vias,tsvs)等制造使能技术和大数据、神经网络等“杀手级”应用的出现,给存算一体化体系结构的发展带来了新的契机。通过在存内集成高并发、高效能的计算单元,完成数据的就近甚至就地计算,存算一体化体系结构可以实现部分应用一至两个数量级的性能加速,并降低约80%数据的搬运能耗.部分新型非易失存储(non-volatile memory,nvm)器件甚至可以实现计算和存储的完全融合。由于数据无需通过接口在内存和cpu间频繁搬运,存算一体化体系结构已经成为了一种缓解甚至打破存储墙的可行手段之一。
3、目前,已有一些关于存算一体化系统中计算划分问题的研究,但是主要侧重点在于解决存内多计算单元间的计算划分,如prometheus基于社区发现(communitydetection)算法提出了一种最小化hmc内部不同计算单元间数据传输的计算划分算法,这类方法通常假设全部的计算任务都在存内执行,片上处理器几乎完全闲置,浪费了宝贵的计算资源。
技术实现思路
1、本发明提供一种提高存算一体化系统性能的静态计算划分方法,旨在改善上述问题。
2、本发明是这样实现的,一种提高存算一体化系统性能的静态计算划分方法,所述方法包括如下步骤:
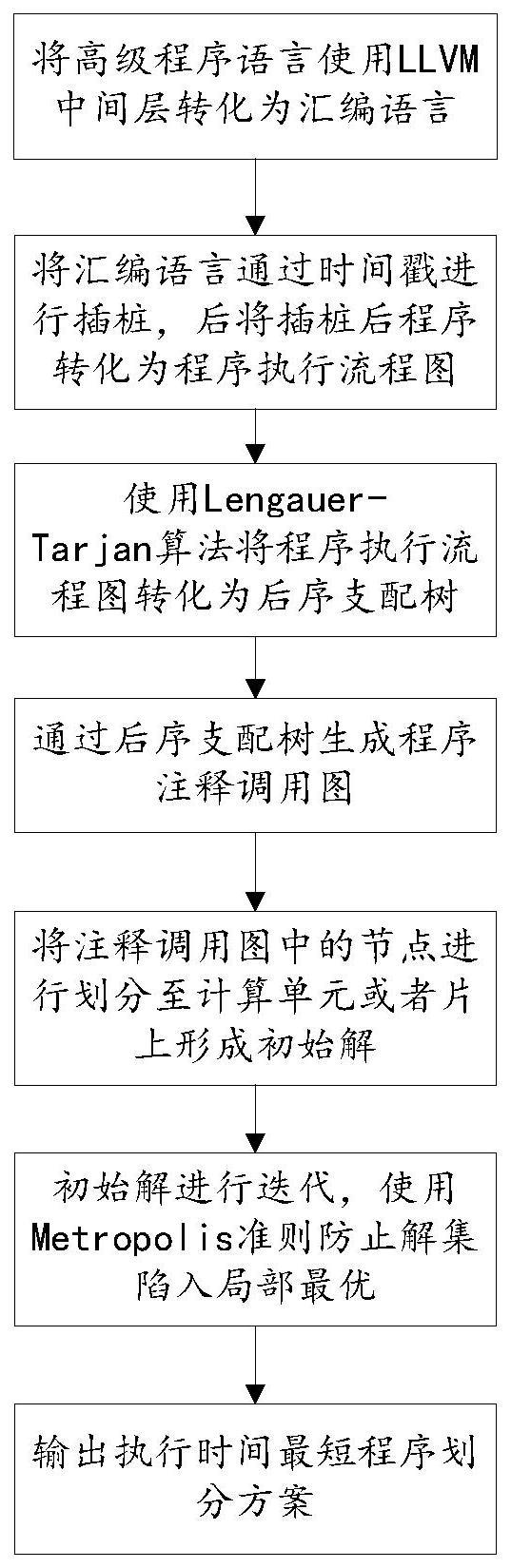
3、s1、将程序划分成若干基本块,将程序转化为程序的注释调用图,注释调用图中的节点即对应于程序中的基本块;
4、s2、将注释调用图中的各节点v划分至内计算单元或片上处理器,形成程序的多个划分方案,输出执行时间最短的程序划分方案。
5、进一步的,注释调用图的生成方法具体如下:
6、s11、使用llvm中间层对将高级程序语言进行抽象为汇编语言,后对会汇编语言进行插桩形成程序的执行流程图;
7、s12、基于lengauer-tarjan算法生成执行流程图的后序支配树;
8、s13、基于后序支配树间各基本块间的支配关系,形成注释调用图的控制依赖边,添加数据依赖边、添加边和节点的属性后,形成注释调用图。
9、进一步的,控制依赖边的生成过程具体如下:
10、s131、检测程序的执行流程图中是否存在环,若存在,则执行步骤s133,再执行步骤s132,若不存在,则直接执行步骤s132;
11、s132、遍历后序支配树边集e2中的所有边e2,在执行流程的边集e1删除与边e2相同的边,形成注释调用图的控制依赖边;
12、s133、环中所有节点都依赖于头节点,以此提取控制相关。
13、进一步的,程序划分方案的执行时间计算公式具体如下:
14、tall=tcpu+tpim+tm
15、其中,tcpu为在片上处理器的执行总时间,tpim为在存内计算单元的执行总时间,tm为片上处理器与存内计算单元间的数据传输总时间。
16、进一步的,tcpu、tpim、tm的计算公式具体如下:
17、
18、
19、
20、
21、其中,表示点集s中全部基本块在片上处理器的执行总时间表示;表示点集t中全部基本块在存内计算单元上执行的总时间表示,表示数据在片上处理器和存内计算单元间的传输总时间,su,v表示基本块u和基本块v之间传输的数据大小,bw表示内存的读写带宽;
22、基本块v对应的指令在存内计算单元上执行时,iv=1,基本块v对应的指令在片上处理器中执行时,iv=0。
23、进一步的,输出执行时间最短的程序划分方案的获取方法具体如下:
24、将执行次数最高的基本块u分发到存内计算单元中执行,剩余基本块分发到片上处理器中执行,将该程序的划分方案作为初始解,计算该划分方案执行的总时间;
25、每次迭代过程中,筛选出执行次数占比超过阈值th的基本块且将其分发至被存内计算单元执行的基本块集合{u},在当前最优解{i}opt的基础上取反编号的基本块j变量ij,形成第i个可行解{i}i;
26、计算划分方案{i}i对应的执行时间ti,计算执行时间ti与当前最优解的执行时间topt的差值δt,若δt为负,则可行解{i}i即为当前最优解并更新当前最优时间为执行时间ti,若δt为正,则说明可行解{i}i的执行时间比当前最优解长,以概率r接受可行解{i}i,即将可行解{i}i作为当前最优解并更新当前最优时间执行时间ti。
27、进一步的,若δt=0,比较可行解{i}i及当前最优解{i}opt的划分方案对应的数据搬运功耗δe,并取数据搬运功耗较低的划分方案作为当前最优解。
28、进一步的,概率r的计算公式具体如下:
29、
30、其中,k为修正系数,代表当前取反ij基本块的执行次数占最大执行次数的百分比,δt为第i个可行解{i}i对应的执行时间ti与当前最优解的执行时间topt的差值。
31、本发明提供的提高存算一体化系统性能的静态计算划分方法具有如下有益技术效果:针对现有计算划分算法未考虑片上处理器和存内计算单元共存场景的问题,基于对程序的离线分析,提出在片上处理器和存内计算单元间的计算划分方法;通过对程序进行离线分析,生成存算一体程序的注释调用图,最终将存算一体化系统中的计算划分问题转化为注释调用图中的最小割问题;加上本发明提出的加速划分问题的求解和收敛速度的方法,可以充分发挥片上处理器和存内计算单元的综合性能,同时降低不必要的数据搬运开销。
技术特征:
1.一种提高存算一体化系统性能的静态计算划分方法,其特征在于,所述方法包括如下步骤:
2.如权利要求1所述提高存算一体化系统性能的静态计算划分方法,其特征在于,注释调用图的生成方法具体如下:
3.如权利要求2所述提高存算一体化系统性能的静态计算划分方法,其特征在于,控制依赖边的生成过程具体如下:
4.如权利要求1所述提高存算一体化系统性能的静态计算划分方法,其特征在于,程序划分方案的执行时间计算公式具体如下:
5.如权利要求5所述提高存算一体化系统性能的静态计算划分方法,其特征在于,tcpu、tpim、tm的计算公式具体如下:
6.如权利要求1所述提高存算一体化系统性能的静态计算划分方法,其特征在于,输出执行时间最短的程序划分方案的获取方法具体如下:
7.如权利要求7所述提高存算一体化系统性能的静态计算划分方法,其特征在于,若δt=0,比较可行解{i}i及当前最优解{i}opt的划分方案对应的数据搬运功耗δe,并取数据搬运功耗较低的划分方案作为当前最优解。
8.如权利要求7所述提高存算一体化系统性能的静态计算划分方法,其特征在于,概率r的计算公式具体如下:
技术总结
本发明公开一种提高存算一体化系统性能的静态计算划分方法,包括如下步骤:S1、将程序划分成若干基本块,将程序转化为程序的注释调用图,注释调用图中的节点即对应于程序中的基本块;S2、将注释调用图中的各节点<subgt;v</subgt;划分至内计算单元或片上处理器,形成程序的多个划分方案,输出执行时间最短的程序划分方案。基于对程序的离线分析,提出在片上处理器和存内计算单元间的计算划分算法,最终将存算一体化系统的计算划分问题转化为注释调用图的最小割问题,使用该方法得到的计算划分能够有效提升系统性能,降低不必要数据搬产生的能耗。
技术研发人员:薛洪宇,徐晟,陈紫阳,赵发鹏,王赛,陈付龙
受保护的技术使用者:安徽师范大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!