一种基于司法文本的词嵌入模型集成方法与流程
本发明涉及词嵌入模型集成领域,特别涉及一种基于司法文本的词嵌入模型集成方法。
背景技术:
1、在过去十年中,人工智能ai已成为一个流行术语,涵盖了所有先进的智能技术,如对抗性竞争、计算机视觉和自然语言处理,为计算机辅助智能化发展带来了惊人的进步。作为人工智能的延伸,自然语言处理nlp在处理机器翻译、语音识别、信息检索和文本相似性分析方面取得了前所未有的成功。尽管自然语言处理nlp已演变应用在智能社会的不同方面,但在智能司法应用当中仍缺乏具体准确的应用。
2、随着计算机应用的不断扩展,机器翻译、语音识别和信息检索等场景都依赖于自然语言处理的技术。作为一种训练词向量的技术,word2vec模型被广泛使用,因为它可以基于语料库训练词嵌入模型,并根据训练模型将句子表示为向量。
3、在智能司法方面,自然语言处理nlp可以通过识别相似的案件和推荐相关文本来帮助法院节省时间。词嵌入方法克服了司法文本中的基本问题,即自然语义。此外,基于word2vec模型的技术可以帮助以更有效的方式进行词嵌入。不幸的是,词语嵌入缺乏克服自然语言中常见缺陷的能力,如多音字。这些常见的缺陷会导致意外的偏差,而意外的偏差在司法文本领域应该被消除。
4、回顾文本相似性架构的历史,经典的文本相似性架构是基于相似句子之间的具体差异。经典差异的定义是两个句子所代表的不同词的数量和长度的差异,或者简而言之,是交集与联合的比率。由于僵化的模型和有限的词汇量,这个经典的建筑被一个基于大型语料库的高维模型所取代。鉴于这种模型,出现了术语频率-反文档频率tf-idf和词袋bow。他们的主要想法是,如果你创建了一个充满单词的语料库,你可以将每个句子投射到一个高维向量中。然而,创建一个语料库只能将句子转换成向量,而不考虑词序或同义词。这个问题实际上对词嵌入的出现有根本性的影响。
5、词语嵌入是一个描述相邻词语之间关系的概念,倾向于预测词语的含义。例如,一个规则的句子可以被转换成一个倒置的句子,甚至可以重建另一个有完全不同的词的句子,尽管意义相同。基于经典模型或语料库模型,很难区分相似性,甚至会错误地将其归为相反的向量。尽管如此,单词嵌入可以模拟真实的自然语言场景,产生可相互替换的单词。此外,在2013年,一种新的技术被用来训练词嵌入,它被称为word2vec。word2vec是一种在文本训练后构建词嵌入模型的方法,可以选择连续词袋cbow和跳格sg。在word2vec的帮助下,词嵌入的概念可以扩展到自然语言处理nlp领域以外的其他应用。最近的应用已经训练了用户行为的词嵌入,如点击、请求和搜索,以提供个人建议。像电子商务、和金融市场领域已经利用这种方法来处理搜索排名。
6、在司法文本方面,为了增强词嵌入的可扩展性,相对研究在训练好的词嵌入中加入了专业语料库。这种方法是为了完善词嵌入模型,提高比较相似句子的准确性。尽管由于专业语料库的扩展,向量空间在实验中似乎效果很好,但在处理完全不同类别的案例时,这种解决方案是非常糟糕的。不同案例中的相似性可能很高,而不是降低到零。更重要的是,如果两个案例是同一类型的,那么确切的差异就不能准确地说明。
技术实现思路
1、为此,需要提供一种在原有的词嵌入模型的基础上,以一种集成的方法来抵消显示在嵌入中的缺陷。通过提取一些因素,如罚金和刑期等因素来帮助识别差异,并给案件贴上标签来完成有监督的集合学习来缓解由于词语嵌入能力弱导致的意外偏差,从而提高模型的鲁棒性。
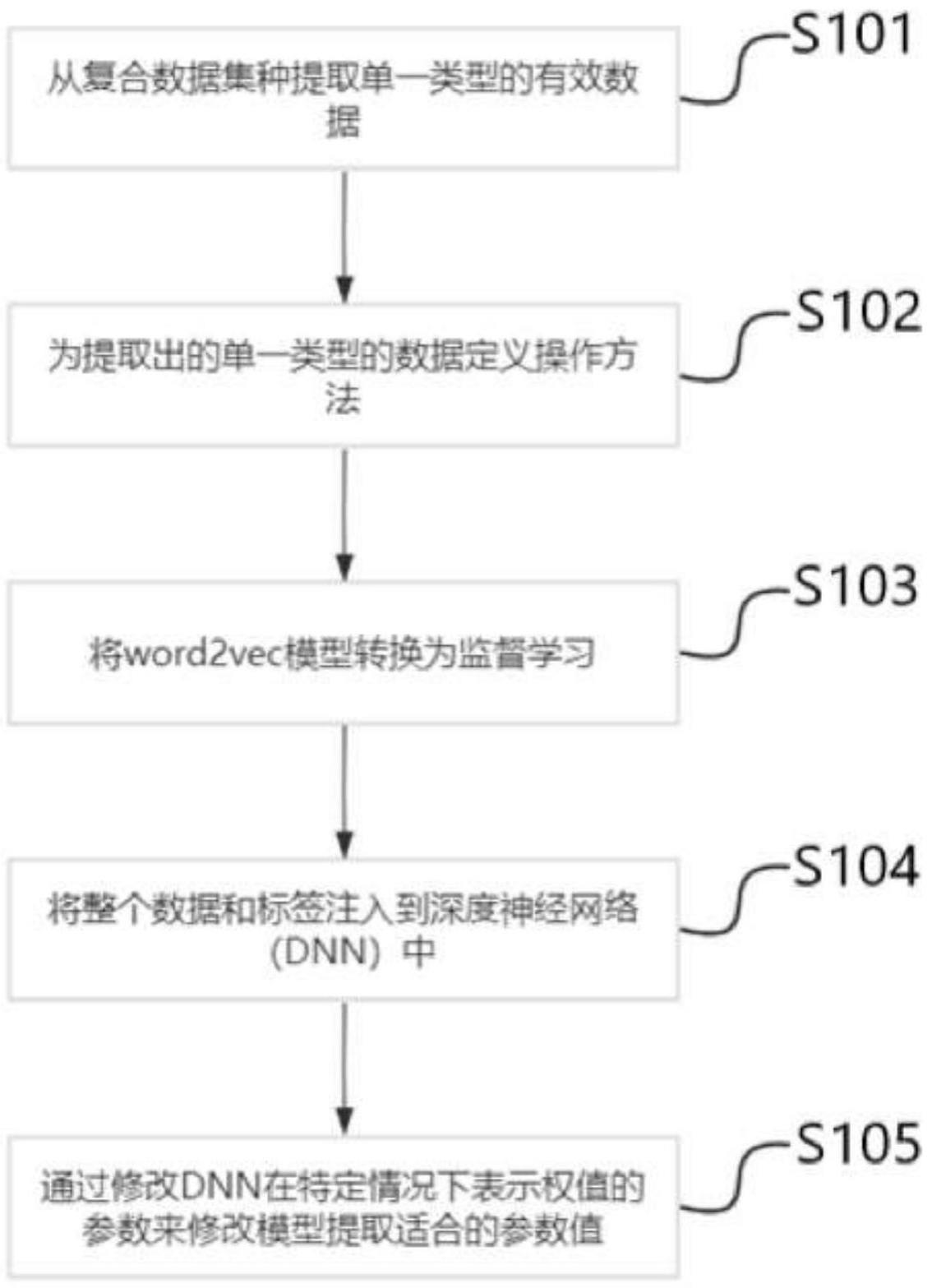
2、为实现上述目的,发明人提供了一种基于司法文本的词嵌入模型集成方法,包括以下步骤:
3、s101、从复合数据集中提取单一类型的数据;
4、s102、为提取出的单一类型的数据分别定义操作方法;
5、s103、将无监督学习的word2vec模型转换为监督学习;
6、s104、将整个数据和标签注入到深度神经网络中;
7、s105、通过修改深度神经网络在特定情况下表示权值的参数来修改模型提取适合的参数值。
8、作为本发明的一种优选方式,所述步骤s101中,从复合数据集中提取单一类型的数据包括从事实中提取文本词、从金钱中提取惩罚和/或从监禁中提取刑期。
9、作为本发明的一种优选方式,所述步骤s102中,为提取出的单一类型的数据分别定义操作方法包括:
10、对文本词,使用word2vec将文本切片;
11、对于惩罚,通过映射来获取不同惩罚之间的差异;和/或,
12、对于刑期,通过映射来获取不同刑期之间的差异。
13、作为本发明的一种优选方式,对文本词,使用word2vec将文本切片时,选择开源语料库cail来训练词的嵌入。
14、作为本发明的一种优选方式,所述步骤s102还包括:由word2vec模型的向量与惩罚映射和刑期映射形成的向量之间的差异,其计算方法是通过映射对比相应的惩罚术语来对数据进行单一提取。
15、作为本发明的一种优选方式,所述步骤s103,将无监督学习的word2vec模型转换为监督学习包括:通过对无监督学习的word2vec中添加人工干涉,对不同类型的数据进行分类,来提取单一类型的数据,将无监督学习的word2vec模型转化为有监督学习的模型。
16、作为本发明的一种优选方式,所述不同类型的数据包括文本词、惩罚和刑期。
17、作为本发明的一种优选方式,所述步骤s104中,深度神经网络吸收了无监督学习和有监督学习优点。
18、作为本发明的一种优选方式,所述步骤s105包括:在深度神经网络模型过拟合或epoch次数较少时,通过修改不同类型数据所代表的权重参数,来修改模型用于适应微小的变化。
19、区别于现有技术,上述技术方案所达到的有益效果有:本方法在原有的词嵌入模型的基础上提取罚款、刑期等因素来帮助识别差异,并通过附件案例的标签来完成监督集成学习;本方法为一种降低复杂度、提高数据拟合度的词嵌入集成方法,其构造的深度神经网络模型有助于减少自然语言的偶然相似性,可以提高在司法文本识别中可靠性因素的确定性,这种基于司法文本的词嵌入模型集成方法在处理突发性相似误差时具有较好的适用性;此外,通过将数据集中的词汇进行数据提取来优化深度神经网络模型,可以有效的提高词嵌入过程中的稳定性。
技术特征:
1.一种基于司法文本的词嵌入模型集成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于司法文本的词嵌入模型集成方法,其特征在于:所述步骤s101中,从复合数据集中提取单一类型的数据包括从事实中提取文本词、从金钱中提取惩罚和/或从监禁中提取刑期。
3.根据权利要求2所述的基于司法文本的词嵌入模型集成方法,其特征在于,所述步骤s102中,为提取出的单一类型的数据分别定义操作方法包括:
4.根据权利要求3所述的基于司法文本的词嵌入模型集成方法,其特征在于:对文本词,使用word2vec将文本切片时,选择开源语料库cail来训练词的嵌入。
5.根据权利要求3所述的基于司法文本的词嵌入模型集成方法,其特征在于,所述步骤s102还包括:由word2vec模型的向量与惩罚映射和刑期映射形成的向量之间的差异,其计算方法是通过映射对比相应的惩罚术语来对数据进行单一提取。
6.根据权利要求3所述的基于司法文本的词嵌入模型集成方法,其特征在于,所述步骤s103,将无监督学习的word2vec模型转换为监督学习包括:通过对无监督学习的word2vec中添加人工干涉,对不同类型的数据进行分类,来提取单一类型的数据,将无监督学习的word2vec模型转化为有监督学习的模型。
7.根据权利要求6所述的基于司法文本的词嵌入模型集成方法,其特征在于:所述不同类型的数据包括文本词、惩罚和刑期。
8.根据权利要求6所述的基于司法文本的词嵌入模型集成方法,其特征在于:所述步骤s104中,深度神经网络吸收了无监督学习和有监督学习优点。
9.根据权利要求8所述的基于司法文本的词嵌入模型集成方法,其特征在于,所述步骤s105包括:在深度神经网络模型过拟合或epoch次数较少时,通过修改不同类型数据所代表的权重参数,来修改模型用于适应微小的变化。
技术总结
本发明公开了一种基于司法文本的词嵌入模型集成方法,包括以下步骤:S101、从复合数据集中提取单一类型的数据;S102、为提取出的单一类型的数据分别定义操作方法;S103、将无监督学习的word2vec模型转换为监督学习;S104、将整个数据和标签注入到深度神经网络中;S105、通过修改深度神经网络在特定情况下表示权值的参数来修改模型提取适合的参数值;本方案在原有的词嵌入模型的基础上,以一种集成的方法来抵消显示在嵌入中的缺陷;通过提取罚金和刑期等因素来帮助识别差异,并给案件贴上标签来完成有监督的集合学习来缓解由于词语嵌入能力弱导致的意外偏差,从而提高模型的鲁棒性。
技术研发人员:郑志松,林锋,刘晓雷,赵剑波
受保护的技术使用者:江苏数兑科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!