基于文本依赖值判断自动分配数据标签的方法及其应用与流程
本申请涉及大数据,特别是涉及基于文本依赖值判断自动分配数据标签的方法及其应用。
背景技术:
1、大数据时代背景下,计算机网络技术以其独特的优势广泛应用,在为社会生产生活提供便利的同时,推动了互联网产业朝着更高的层次发展。随着5g时代的到来,极大地解决了数据传输的问题,人类向着智能化社会迈出了至关重要的一步,智能家居、智能机器人、无人驾驶等等所需求的数据量是非常庞大的。数据标注可以说是ai取代了一部分工作岗位后又衍生出来的一种工作。在未来ai发展良好的前提下,数据的缺口一定是巨大的。可以预见3-5年内数据标注员的需求会一直存在。在日常的标注工作中,也逐渐发展出了各种数据标注的方法和系统,为了更好地解决数据标注的问题和快速标注的问题。
2、目前,由于大数据的数据量庞大,并且拥有时效性、多样性、精确性的特点,在对数据进行标注的时候,为了保证数据标注的准确性,往往需要人力的介入,但是人力的介入,又会占据大量的人力资源,如果采用算法进行智能标注,开发的成本也会增加,并且标注的准确率有待提升。
3、因此,亟待一种新的并且简单快速的标注方法,以节省人力资源和开发资源。
技术实现思路
1、本申请实施例提供了基于文本依赖值判断自动分配数据标签的方法及其应用,针对目前技术数据标注人力资源成本高的问题。
2、第一方面,本申请提供了基于文本依赖值判断自动分配数据标签的方法,所述方法包括以下步骤:
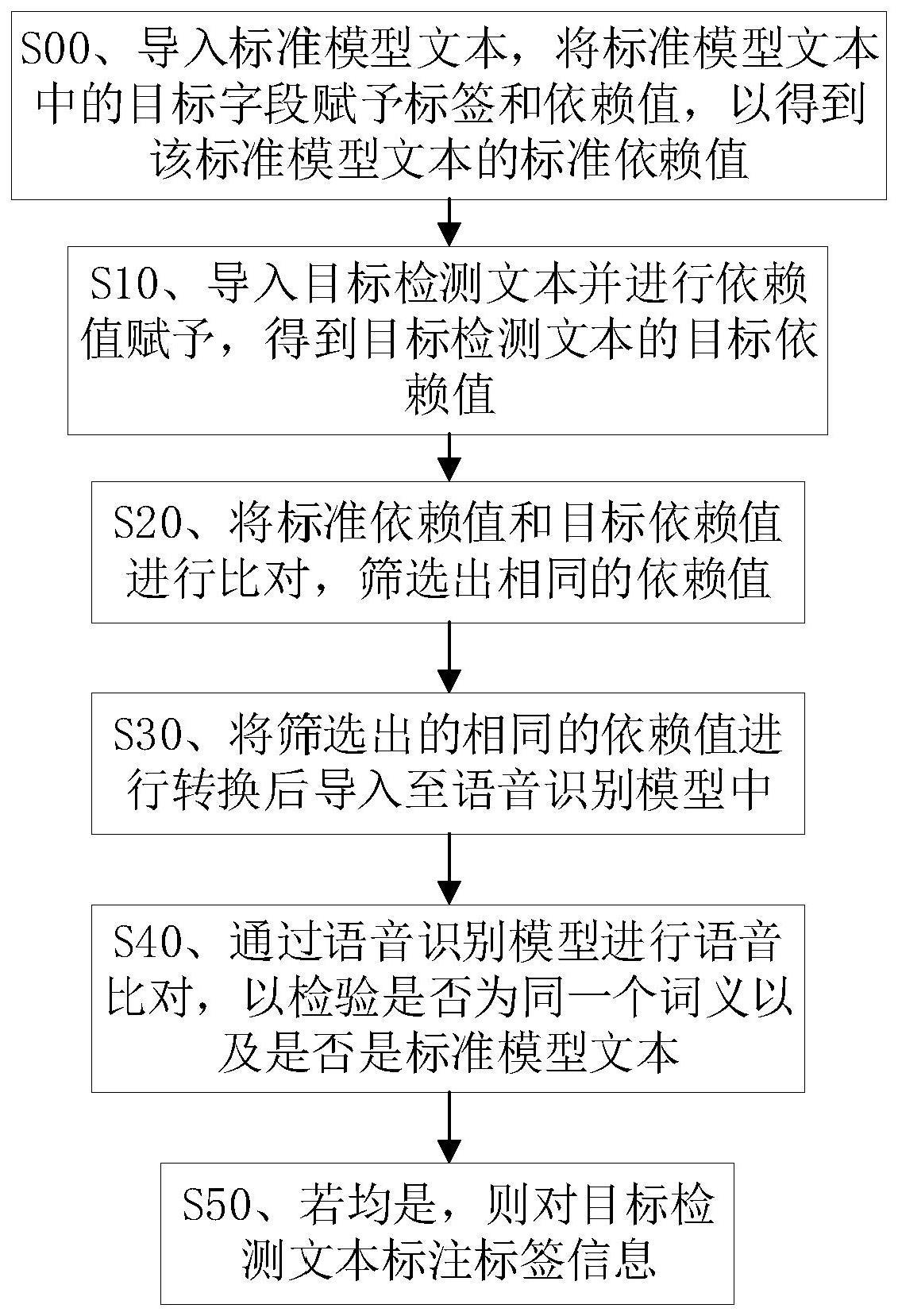
3、s00、导入标准模型文本,将标准模型文本中的目标字段赋予标签和依赖值,以得到该标准模型文本的标准依赖值;
4、s10、导入目标检测文本并进行依赖值赋予,得到目标检测文本的目标依赖值;
5、s20、将标准依赖值和目标依赖值进行比对,筛选出相同的依赖值;
6、s30、将筛选出的相同的依赖值进行转换后导入至语音识别模型中;
7、s40、通过语音识别模型进行语音比对,以检验是否为同一个词义以及是否是标准模型文本;
8、s50、若均是,则对目标检测文本标注标签信息。
9、进一步地,s00步骤中,依赖值的赋予步骤为:
10、设定结构元素b,将目标字段像素化得到图像x;
11、通过结构元素b扫描图像x中每一个像素点;
12、若结构元素b覆盖图像x的区域有任意一点的颜色均为设定颜色,则扫描点为设定颜色,否则为非设定颜色,最终得到扩展后的图像x作为依赖值。
13、进一步地,通过对依赖值进行削减,以去除影响因子。
14、进一步地,对依赖值进行削减的步骤为:
15、通过结构元素b扫描图像x中每一个像素点;
16、若结构元素b覆盖图像x的区域有任意一点的颜色均为设定颜色,则扫描点为非设定颜色,否则不变,最终得到削减后的图像x作为依赖值。
17、进一步地,s30步骤中,将筛选出的相同的依赖值转换成其他文字形式后再导入语音识别模型进行语音比对。
18、进一步地,s30步骤中,若目标检测文本和标准模型文本存在相同的依赖值,转换成的其他文字形式均相同,则再导入语音识别模型检验是否为标准模型文本。
19、进一步地,将依赖值表示为数字或特殊符号。
20、第二方面,本申请提供了一种基于文本依赖值判断自动分配数据标签的装置,包括:
21、导入模块,用于导入标准模型文本和目标检测文本;
22、依赖值赋予模块,用于将标准模型文本中的目标字段赋予标签和依赖值,以得到该标准模型文本的标准依赖值;用于对目标检测文本进行依赖值赋予,得到目标检测文本的目标依赖值;
23、比对模块,用于将标准依赖值和目标依赖值进行比对,筛选出相同的依赖值;
24、语音识别模型模块,用于将筛选出的相同的依赖值进行转换后导入至语音识别模型中;通过语音识别模型进行语音比对,以检验是否为同一个词义以及是否是标准模型文本;
25、输出模块,对符合同一词义和是标准模型文本的目标检测文本标注标签信息。
26、第三方面,本申请提供了一种电子装置,包括存储器和处理器,存储器中存储有计算机程序,处理器被设置为运行计算机程序以执行上述的基于文本依赖值判断自动分配数据标签的方法。
27、第四方面,本申请提供了一种可读存储介质,可读存储介质中存储有计算机程序,计算机程序包括用于控制过程以执行过程的程序代码,过程包括根据上述的基于文本依赖值判断自动分配数据标签的方法。
28、本发明的主要贡献和创新点如下:
29、1、与现有技术相比,本申请通过依赖值的建立,对文本的多样性和复杂性进行了简化处理,方便文本的识别;通过最后的语音识别模型,将文本内容导入模型进行语音识别(语音识别之前也需要导入标准文本的依赖值),最后进行文本校验是否为需求的文本内容,可实现快速文本的识别并标注,大大减少了人力阅读文本的成本,提高了标注文本的效率;
30、2、与现有技术相比,本申请基于文本识别的基础上,本质上还是对文本去进行识别,而现有的文本识别的算法基本都是以提取文本特征值为主,本申请是直接利用文本内容进行识别,不需要提取特征值。而避免提取文本特征值,大大降低了受文本不清晰以及其他因素的影响,利用扩展将文本赋予依赖值,再利用削减去识别文本,本质上加强了文本的识别准确性,降低了识别的难度。
31、本申请的一个或多个实施例的细节在以下附图和描述中提出,以使本申请的其他特征、目的和优点更加简明易懂。
技术特征:
1.基于文本依赖值判断自动分配数据标签的方法,其特征在于,包括以下步骤:
2.如权利要求1所述的基于文本依赖值判断自动分配数据标签的方法,其特征在于,s00步骤中,所述依赖值的赋予步骤为:
3.如权利要求2所述的基于文本依赖值判断自动分配数据标签的方法,其特征在于,通过对依赖值进行削减,以去除影响因子。
4.如权利要求3所述的基于文本依赖值判断自动分配数据标签的方法,其特征在于,对依赖值进行削减的步骤为:
5.如权利要求1所述的基于文本依赖值判断自动分配数据标签的方法,其特征在于,s30步骤中,将筛选出的相同的依赖值转换成其他文字形式后再导入语音识别模型进行语音比对。
6.如权利要求5所述的基于文本依赖值判断自动分配数据标签的方法,其特征在于,s30步骤中,若所述目标检测文本和所述标准模型文本存在相同的依赖值,转换成的其他文字形式均相同,则再导入语音识别模型检验是否为标准模型文本。
7.如权利要求1-6任一项所述的基于文本依赖值判断自动分配数据标签的方法,其特征在于,将依赖值表示为数字或特殊符号。
8.一种基于文本依赖值判断自动分配数据标签的装置,其特征在于,包括:
9.一种电子装置,包括存储器和处理器,其特征在于,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行权利要求1至7任一项所述的基于文本依赖值判断自动分配数据标签的方法。
10.一种可读存储介质,其特征在于,所述可读存储介质中存储有计算机程序,所述计算机程序包括用于控制过程以执行过程的程序代码,所述过程包括根据权利要求1至7任一项所述的基于文本依赖值判断自动分配数据标签的方法。
技术总结
本申请提出了基于文本依赖值判断自动分配数据标签的方法及其应用,包括以下步骤:S00、导入标准模型文本,将标准模型文本中的目标字段赋予标签和依赖值,以得到该标准模型文本的标准依赖值;S10、导入目标检测文本并进行依赖值赋予,得到目标文本的目标依赖值;S20、将标准依赖值和目标依赖值进行比对,筛选出相同的依赖值;S30、将筛选出的相同的依赖值进行转换后导入至语音识别模型中;S40、通过语音识别模型进行语音比对,以检验是否为同一个词义以及是否是标准模型文本;S50、若均是,则对目标检测文本标注标签信息。本申请可节省人力资源,提高标注效率。
技术研发人员:李圣权,高博文,任通,彭大蒙,来佳飞
受保护的技术使用者:城云科技(中国)有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!